Description
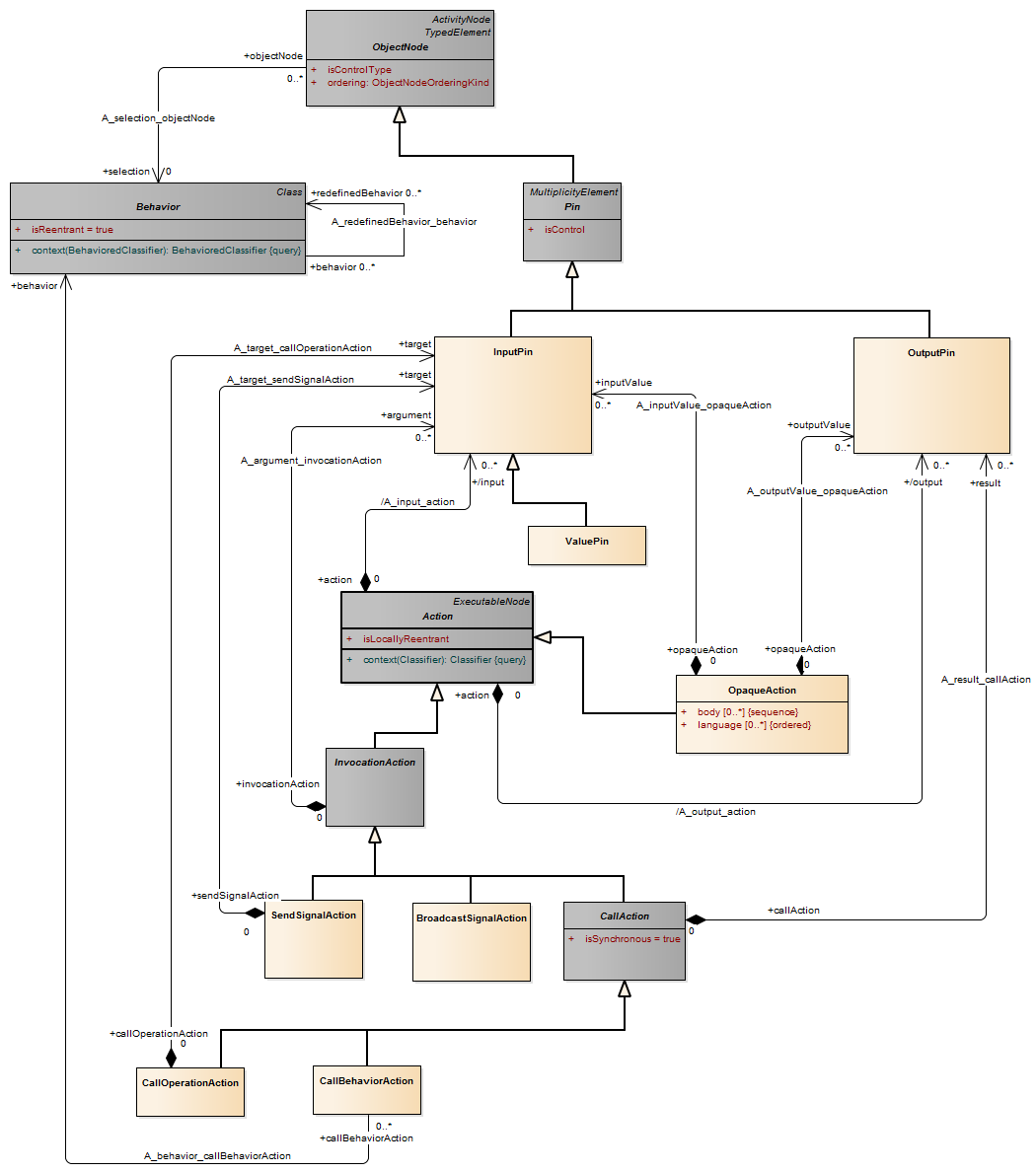
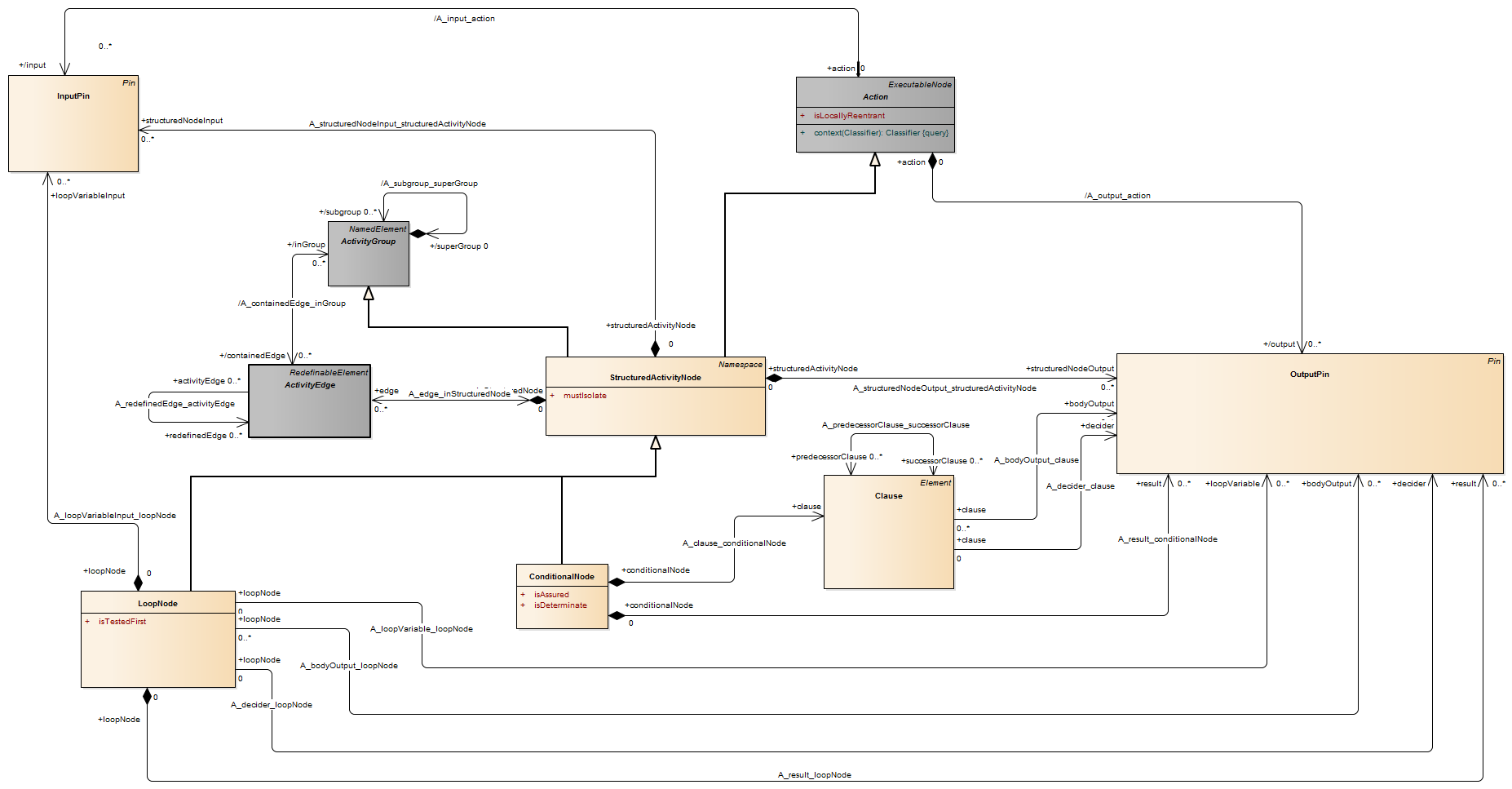
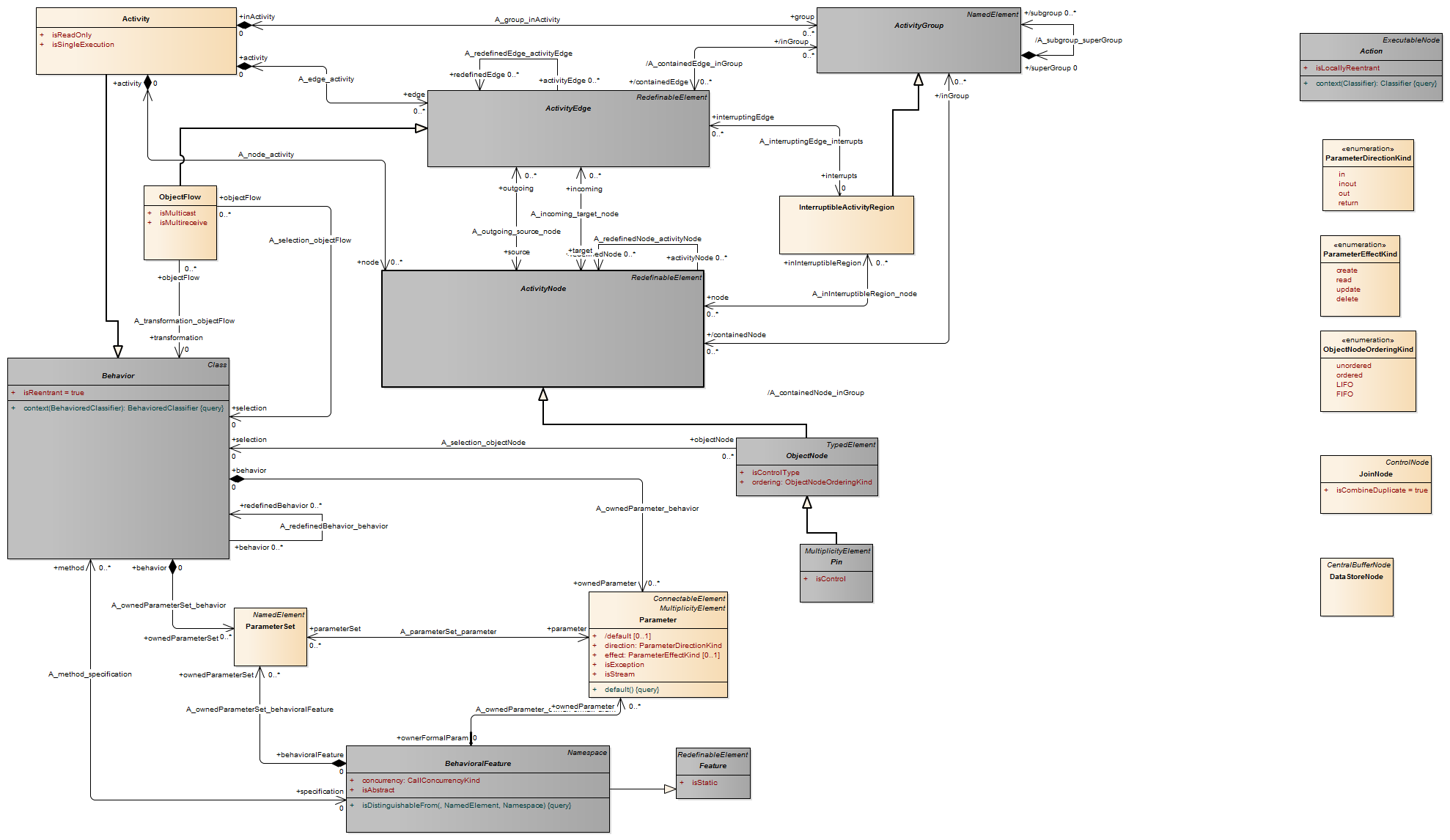
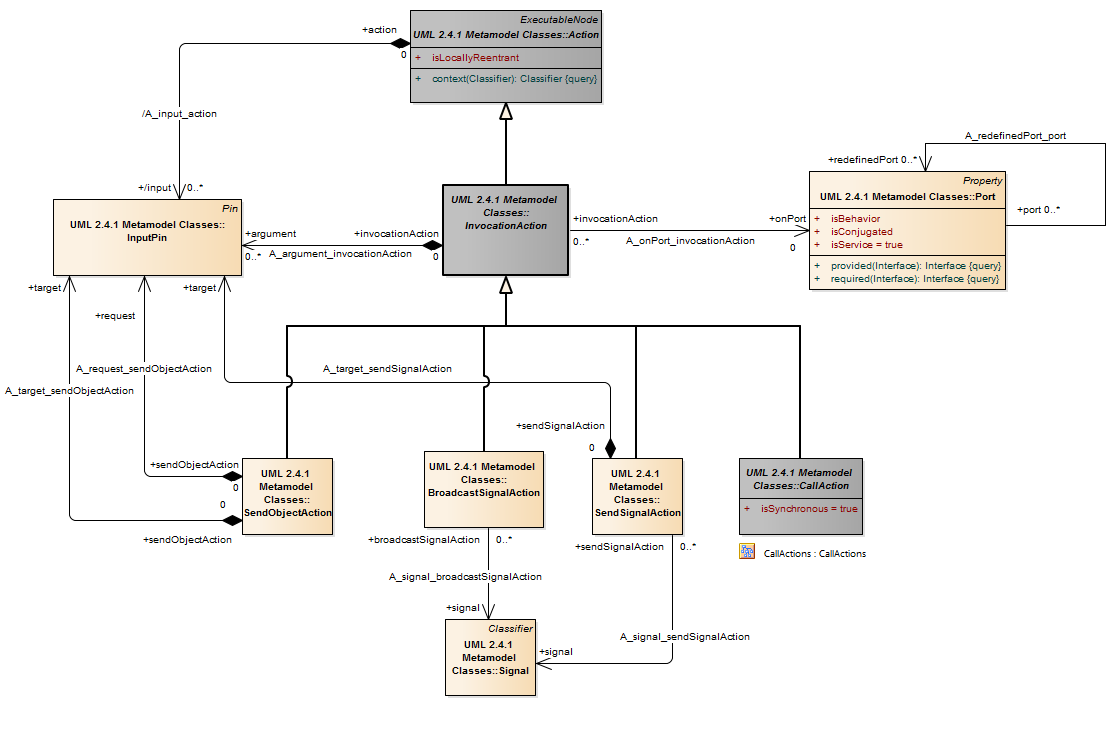
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
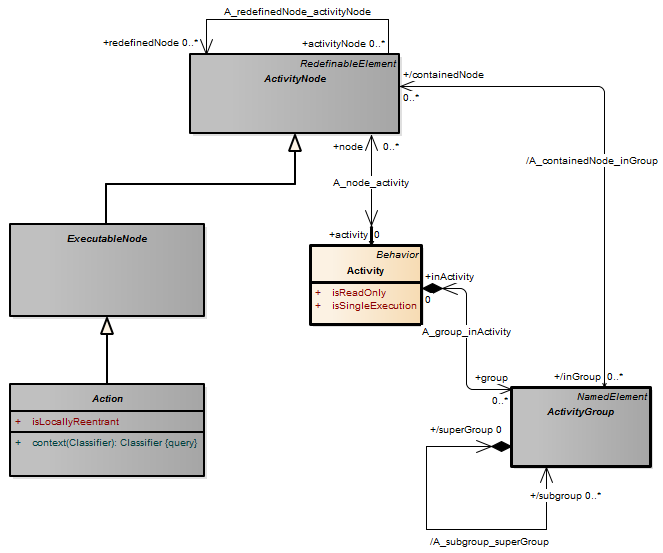
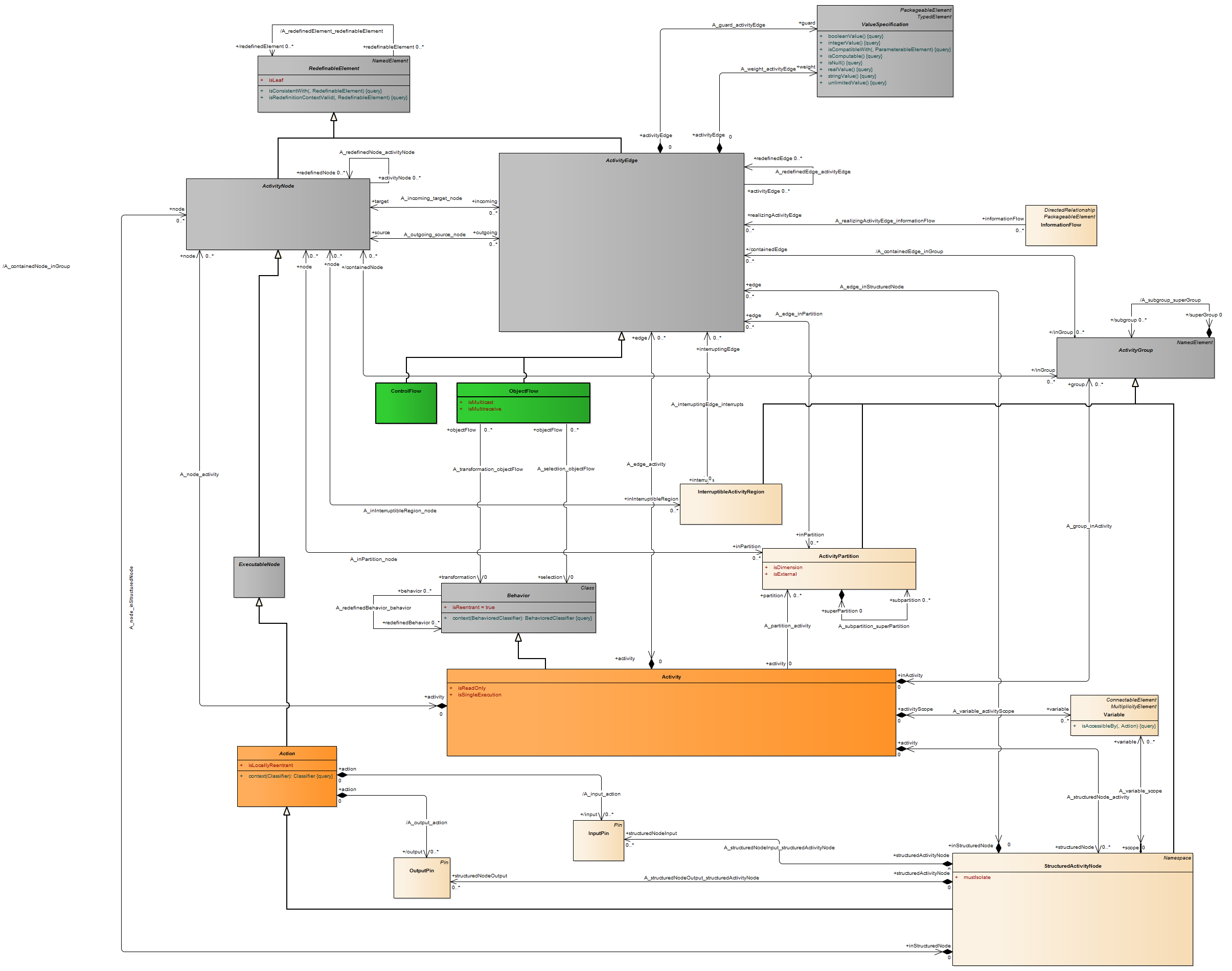
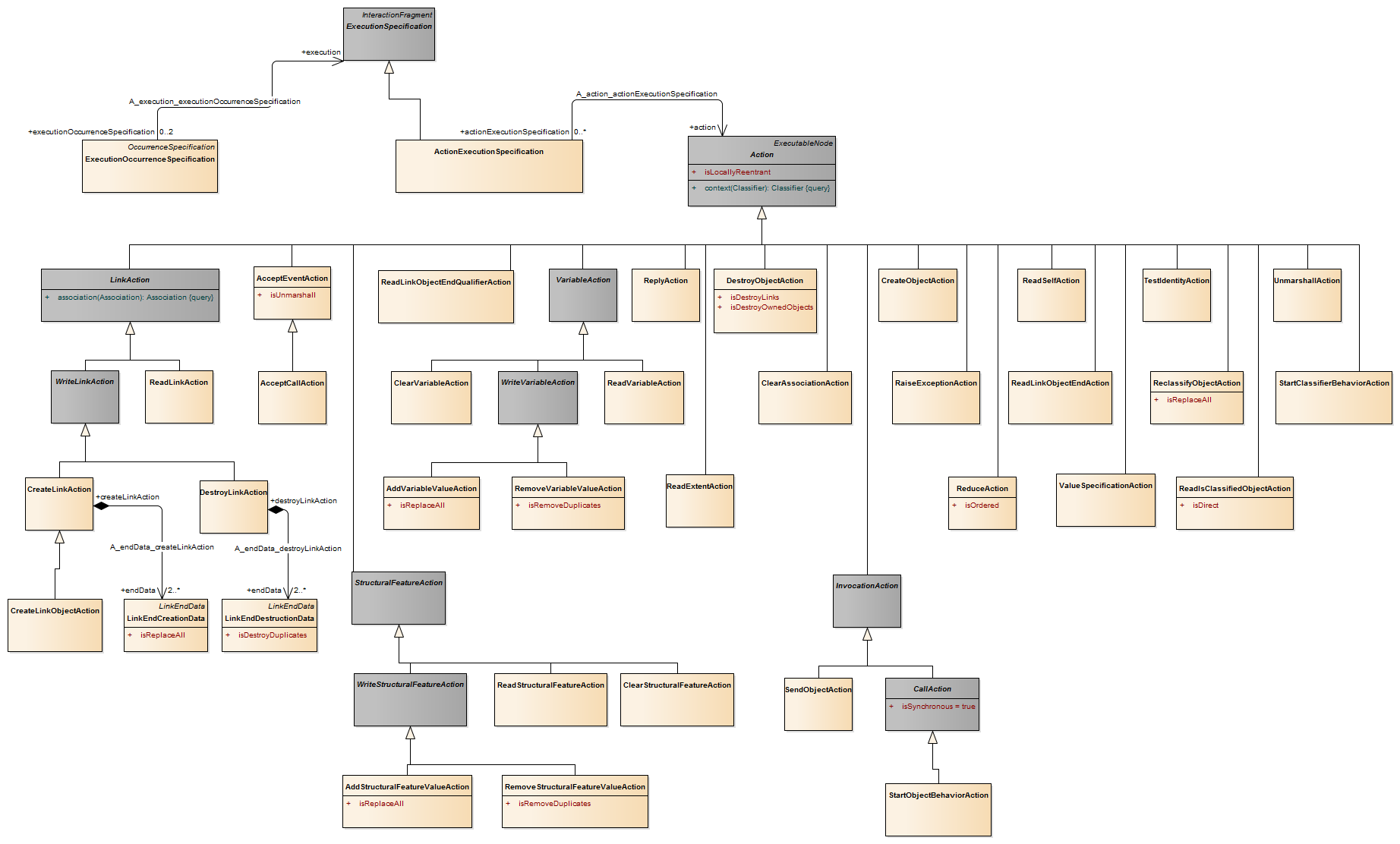
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description An action with implementation-specific semantics
Semantics The semantics of the action are determined by the implementation.
Rationale OpaqueAction is introduced for implementation-specific actions or for use as a temporary placeholder before some other action is chosen.
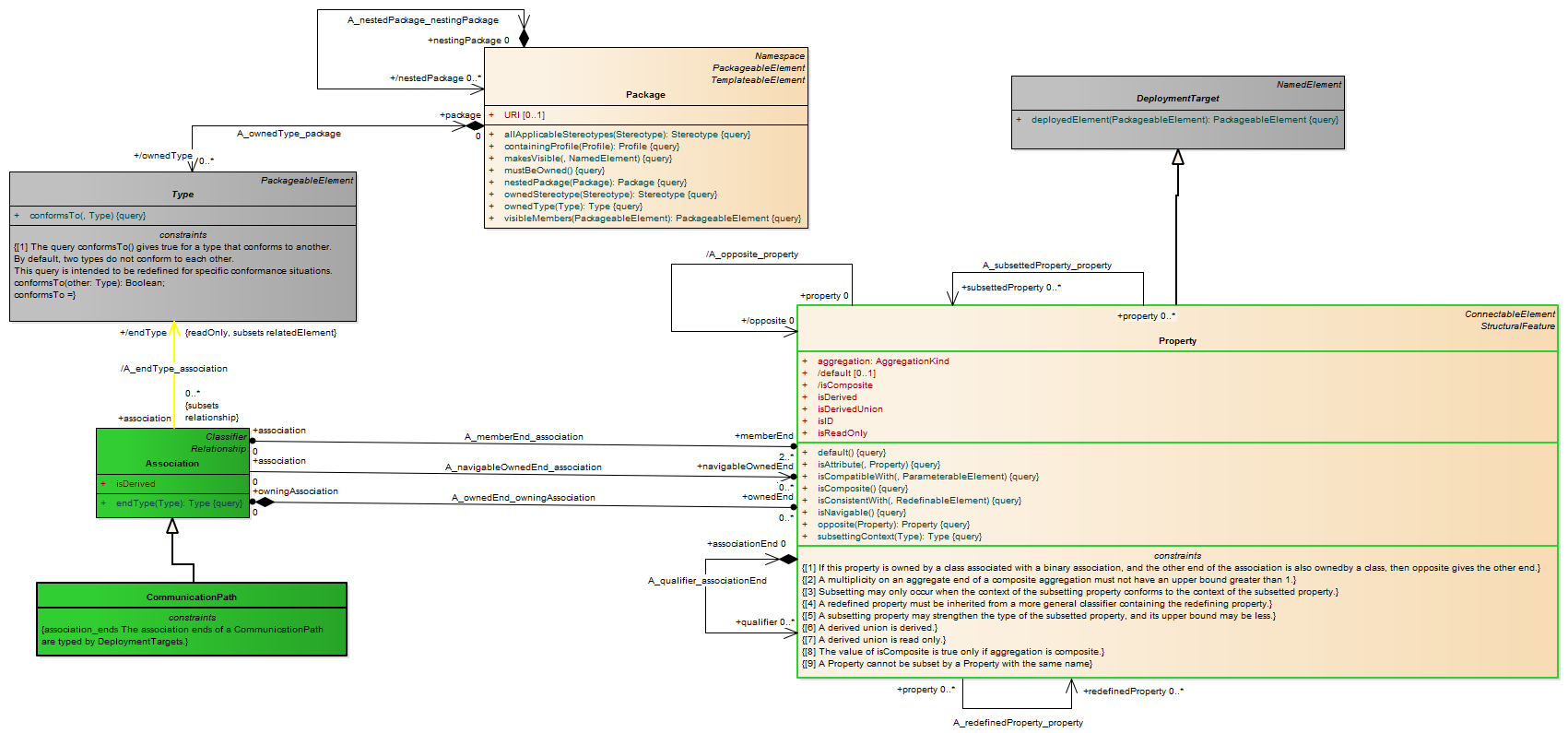
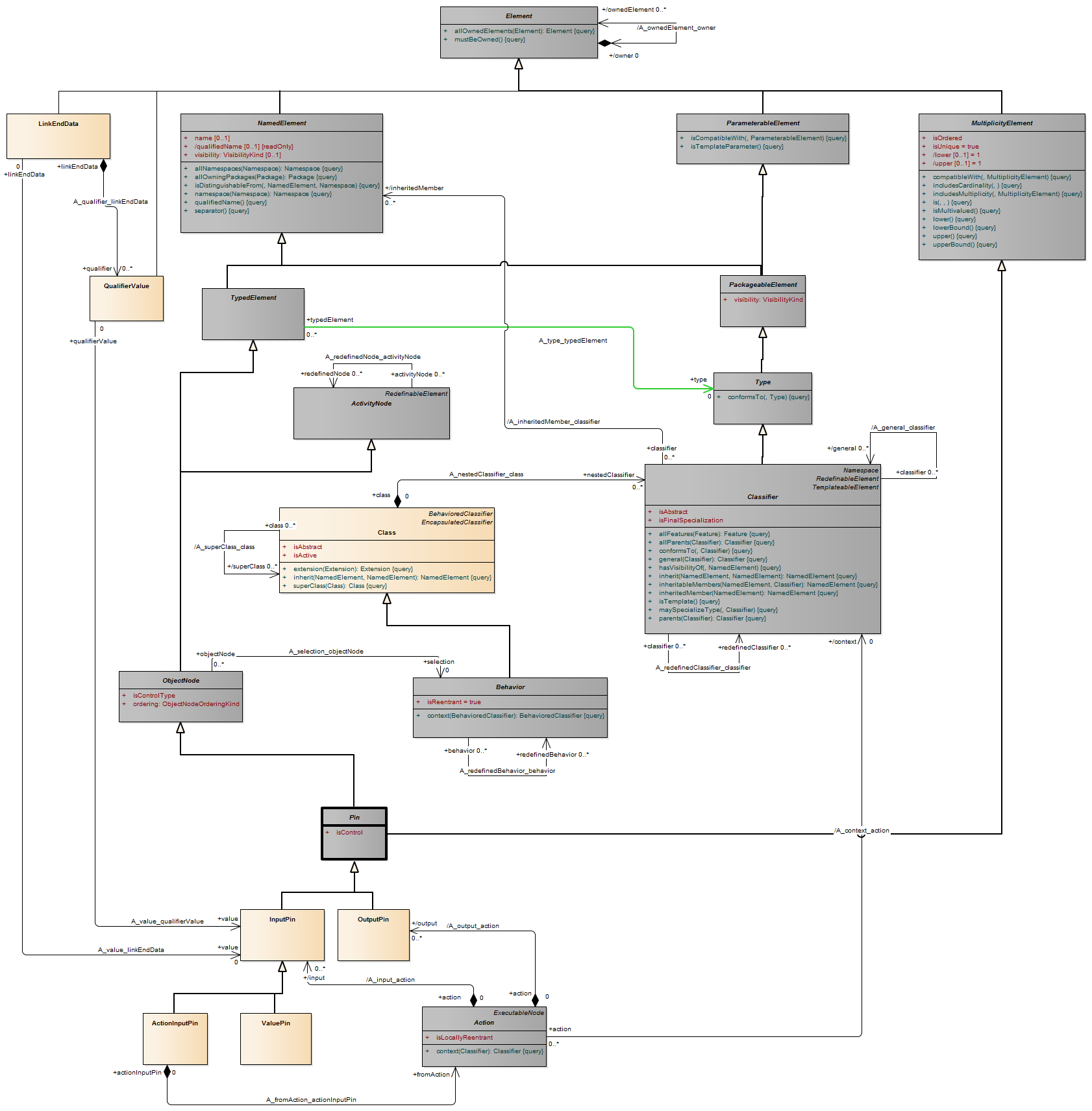
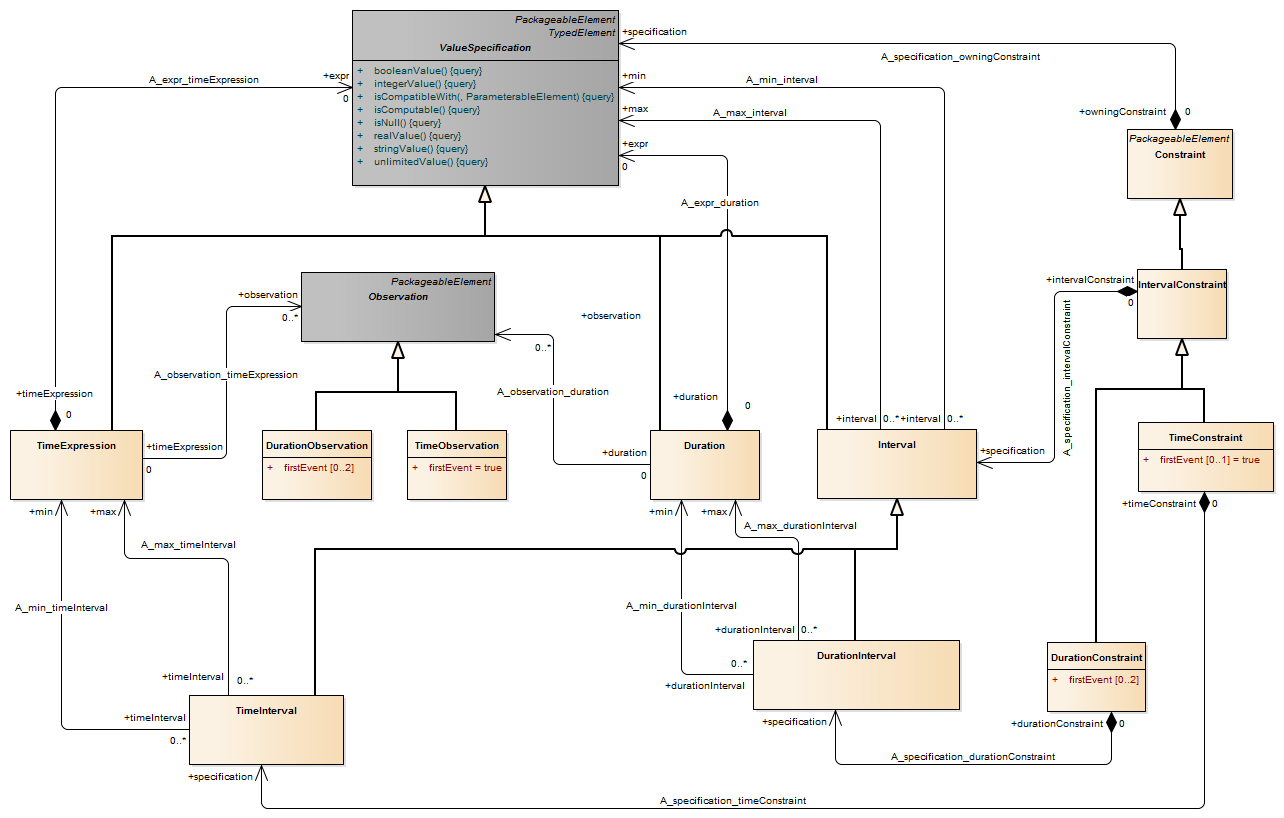
Description A pin is a typed element and multiplicity element that provides values to actions and accepts result values from them.
Semantics
A pin represents an input to an action or an output from an action. The definition on an action assumes that pins are ordered. Pin multiplicity controls action execution, not the number of tokens in the pin (see upperBound on “ObjectNode (from BasicActivities, CompleteActivities)” on page 405). See “InputPin (from BasicActions)” and “OutputPin (from BasicActions)” for semantics of multiplicity. Pin multiplicity is not unique, because multiple tokens with the same value can reside in an object node.
Description A value pin is an input pin that provides a value by evaluating a value specification.
Semantics The value of the pin is the result of evaluating the value specification.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
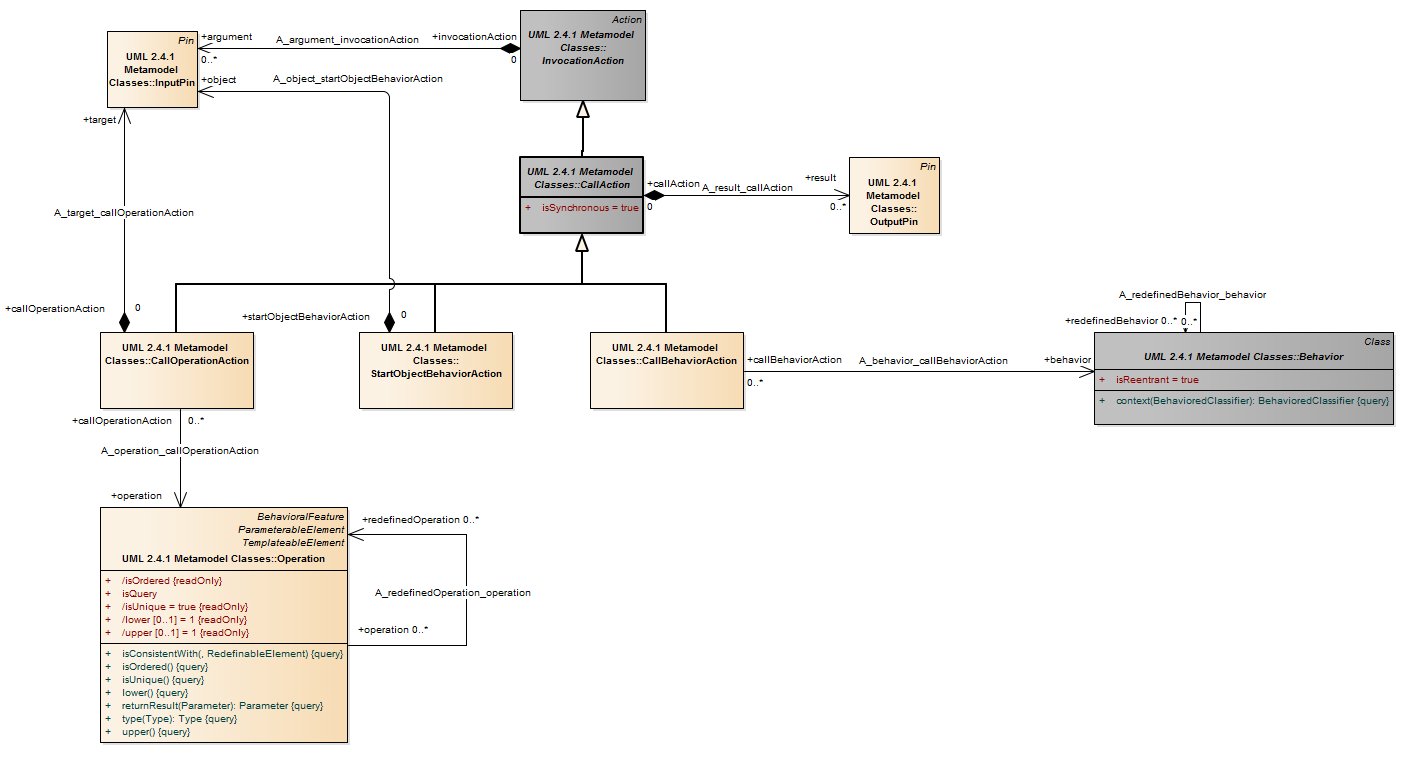
Description CallAction is an abstract class for actions that invoke behavior and receive return values.
Semantics Parameters on behaviors and operations are totally ordered lists. To match parameters to pins on call actions, select the sublist of that list that corresponds to in and inout owned parameters (i.e., Behavior.ownedParameter). The input pins on Action::input are matched in order against these parameters in the sublist order. Then take the sublist of the parameter list that corresponds to out, inout, and return parameters. The output pins on Action::output are matched in order against these parameters in sublist order. If the behavior invoked by a call action is not reentrant, then no more than one execution of it will exist at any given time. An invocation of a non-reentrant behavior does not start the behavior when the behavior is already executing.
An invocation of a reentrant behavior may start a new execution of the behavior when offered the required tokens, even if the behavior is already executing. However, it will not invoke the behavior if there is an ongoing behavior execution invocated by the same action within the same activity execution, and the action has isLocallyReentrant=false (see “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319). See children of CallAction.
Description SendSignalAction is an action that creates a signal instance from its inputs, and transmits it to the target object, where it may cause the firing of a state machine transition or the execution of an activity. The argument values are available to the execution of associated behaviors. The requestor continues execution immediately. Any reply message is ignored and is not transmitted to the requestor. If the input is already a signal instance, use SendObjectAction.
Semantics
[1] When all the prerequisites of the action execution are satisfied, a signal instance of the type specified by signal is generated from the argument values and this signal instance is transmitted to the identified target object. The target object may be local or remote. The signal instance may be copied during transmission, so identity might not be preserved. The manner of transmitting the signal object, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
[2] When a transmission arrives at a target object, it may invoke behavior in the target object. The effect of receiving a signal object is specified in 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
[3] A send signal action receives no reply from the invoked behavior; any attempted reply is simply ignored, and no transmission is performed to the requestor.
Rationale Sends a signal to a specified target object.
Description
CallBehaviorAction is a call action that invokes a behavior directly rather than invoking a behavioral feature that, in turn, results in the invocation of that behavior. The argument values of the action are available to the execution of the invoked behavior. For synchronous calls the execution of the call behavior action waits until the execution of the invoked behavior completes and a result is returned on its output pin. The action completes immediately without a result, if the call is asynchronous.
Semantics
[1] When all the prerequisites of the action execution are satisfied, CallBehaviorAction invokes its specified behavior with the values on the input pins as arguments. When the behavior is finished, the output values are put on the output pins. Each parameter of the behavior of the action provides output to a pin or takes input from one. No other implementation specifics are implied, such as call stacks, and so on.
[2] If the call is asynchronous, the action completes immediately. Execution of the invoked behavior proceeds without any further dependency on the execution of the behavior containing the invoking action. Once the invocation of the behavior has been initiated, execution of the asynchronous action is complete.
[3] An asynchronous invocation completes when its behavior is started, or is at least ensured to be started at some point. Any return or out values from the invoked behavior are not passed back to the containing behavior. When an asynchronous invocation is done, the containing behavior continues regardless of the status of the invoked behavior. For example, the containing behavior may complete even though the invoked behavior is not finished.
[4] If the call is synchronous, execution of the calling action is blocked until it receives a reply from the invoked behavior. The reply includes values for any return, out, or inout parameters.
[5] If the call is synchronous, when the execution of the invoked behavior completes, the result values are placed on the result pins of the call behavior action, and the execution of the action is complete (StructuredActions, ExtraStructuredActivities). If the execution of the invoked behavior yields an exception, the exception is transmitted to the call behavior action to begin search for a handler. See RaiseExceptionAction.
Description
CallOperationAction is an action that transmits an operation call request to the target object, where it may cause the invocation of associated behavior. The argument values of the action are available to the execution of the invoked behavior. If the action is marked synchronous, the execution of the call operation action waits until the execution of the invoked behavior completes and a reply transmission is returned to the caller; otherwise, execution of the action is complete when the invocation of the operation is established and the execution of the invoked operation proceeds concurrently with the execution of the calling behavior. Any values returned as part of the reply transmission are put on the result output pins of the call operation action. Upon receipt of the reply transmission, execution of the call operation action is complete.
Semantics
The inputs to the action determine the target object and additional actual arguments of the call.
[1] When all the prerequisites of the action execution are satisfied, information comprising the operation and the argument pin values of the action execution is created and transmitted to the target object. The target objects may be local or remote. The manner of transmitting the call, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
[2] When a call arrives at a target object, it may invoke a behavior in the target object. The effect of receiving such call is specified in 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
[3] If the call is synchronous, when the execution of the invoked behavior completes, its return results are transmitted back as a reply to the calling action execution. The manner of transmitting the reply, the time required for transmission, the representation of the reply transmission, and the transmission path are unspecified. If the execution of the invoked behavior yields an exception, the exception is transmitted to the caller where it is reraised as an exception in the execution of the calling action. Possible exception types may be specified by attaching them to the called Operation using the raisedException association.
[4] If the call is asynchronous, the caller proceeds immediately and the execution of the call operation action is complete. Any return or out values from the invoked operation are not passed back to the containing behavior. If the call is synchronous, the caller is blocked from further execution until it receives a reply from the invoked behavior.
[5] When the reply transmission arrives at the invoking action execution, the return result values are placed on the result pins of the call operation action, and the execution of the action is complete.
Semantic Variation Points The mechanism for determining the method to be invoked as a result of a call operation is unspecified.
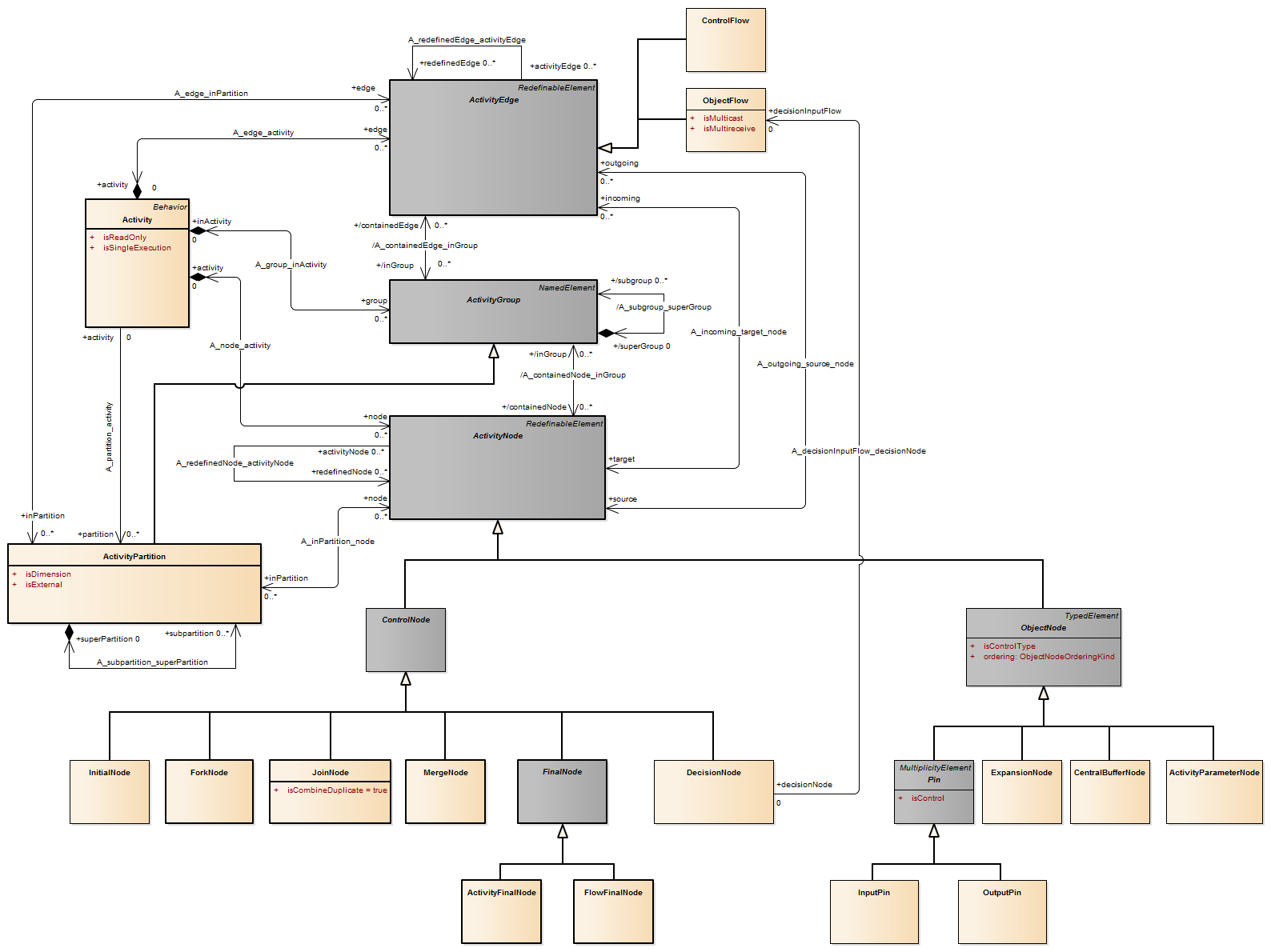
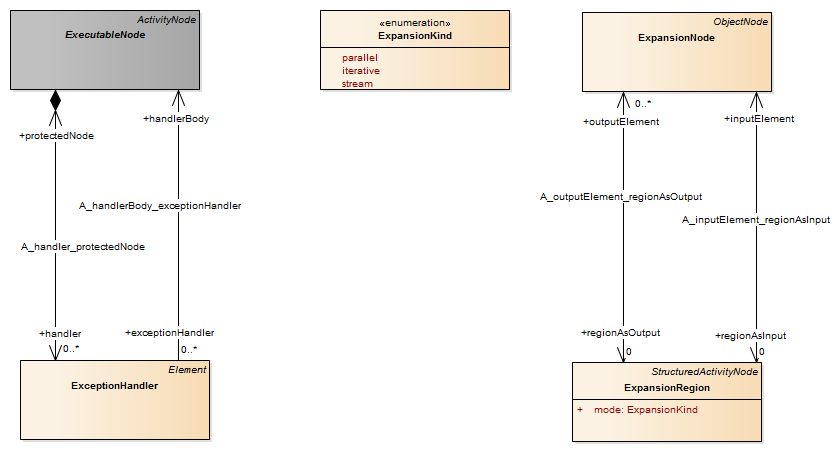
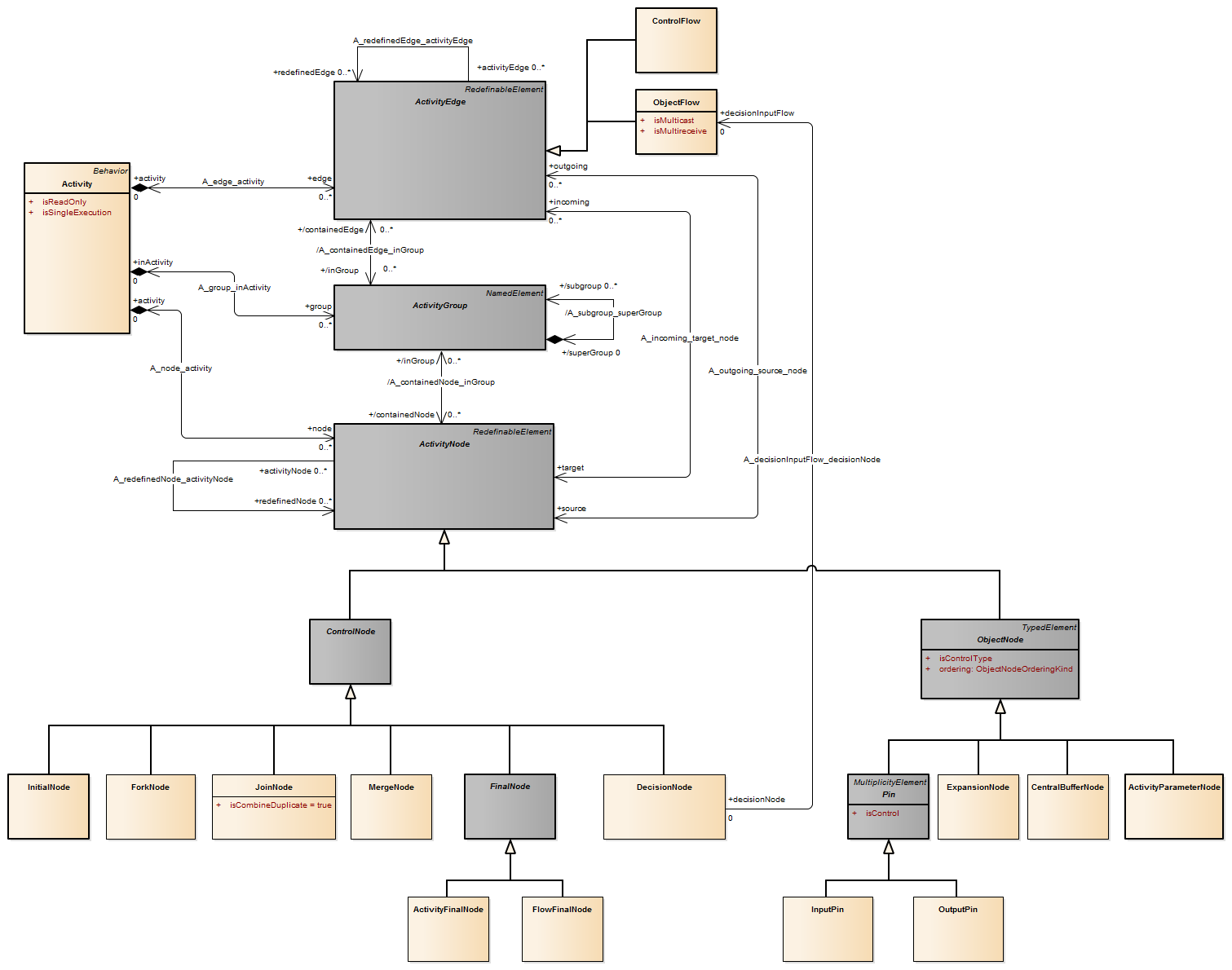
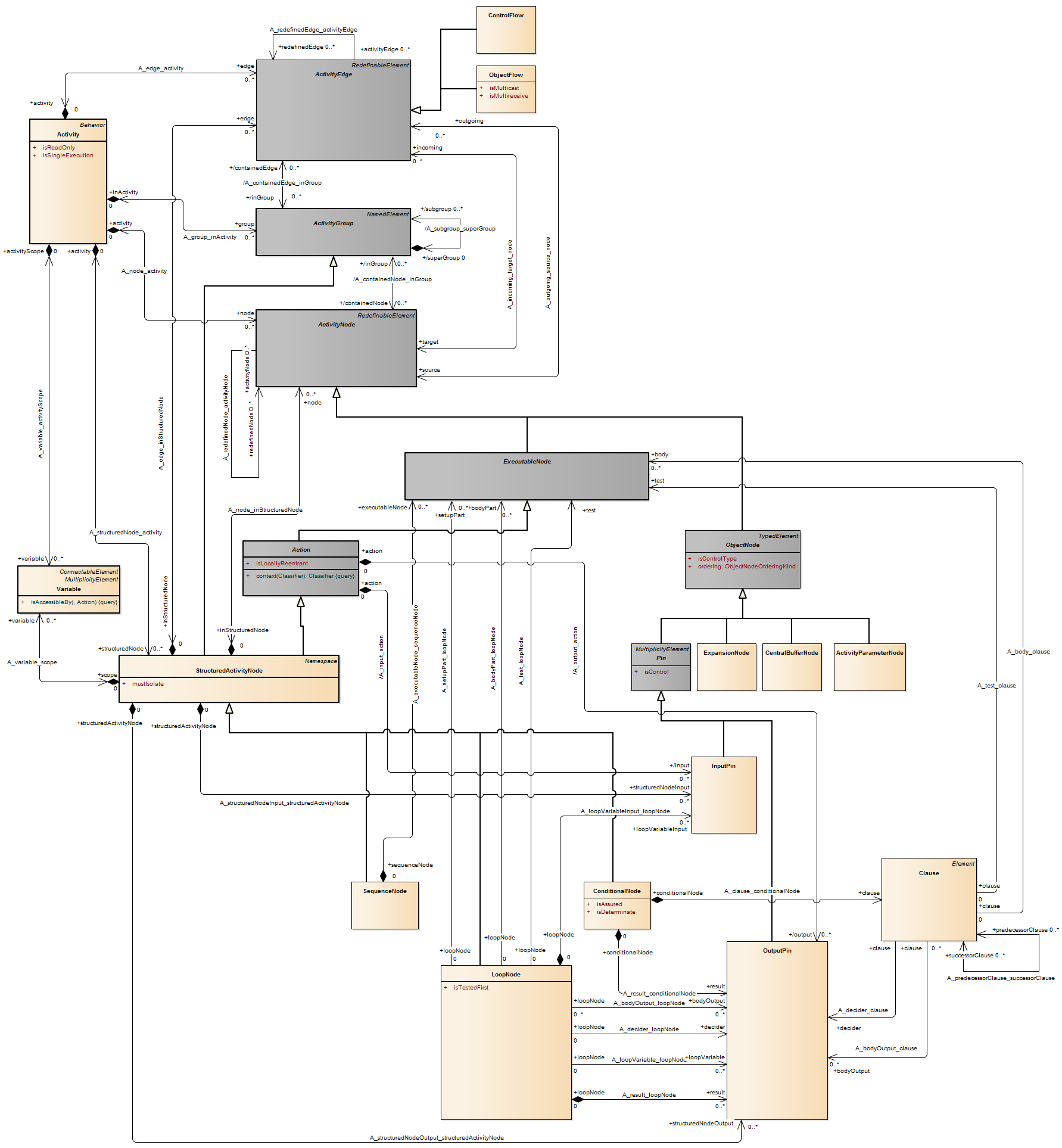
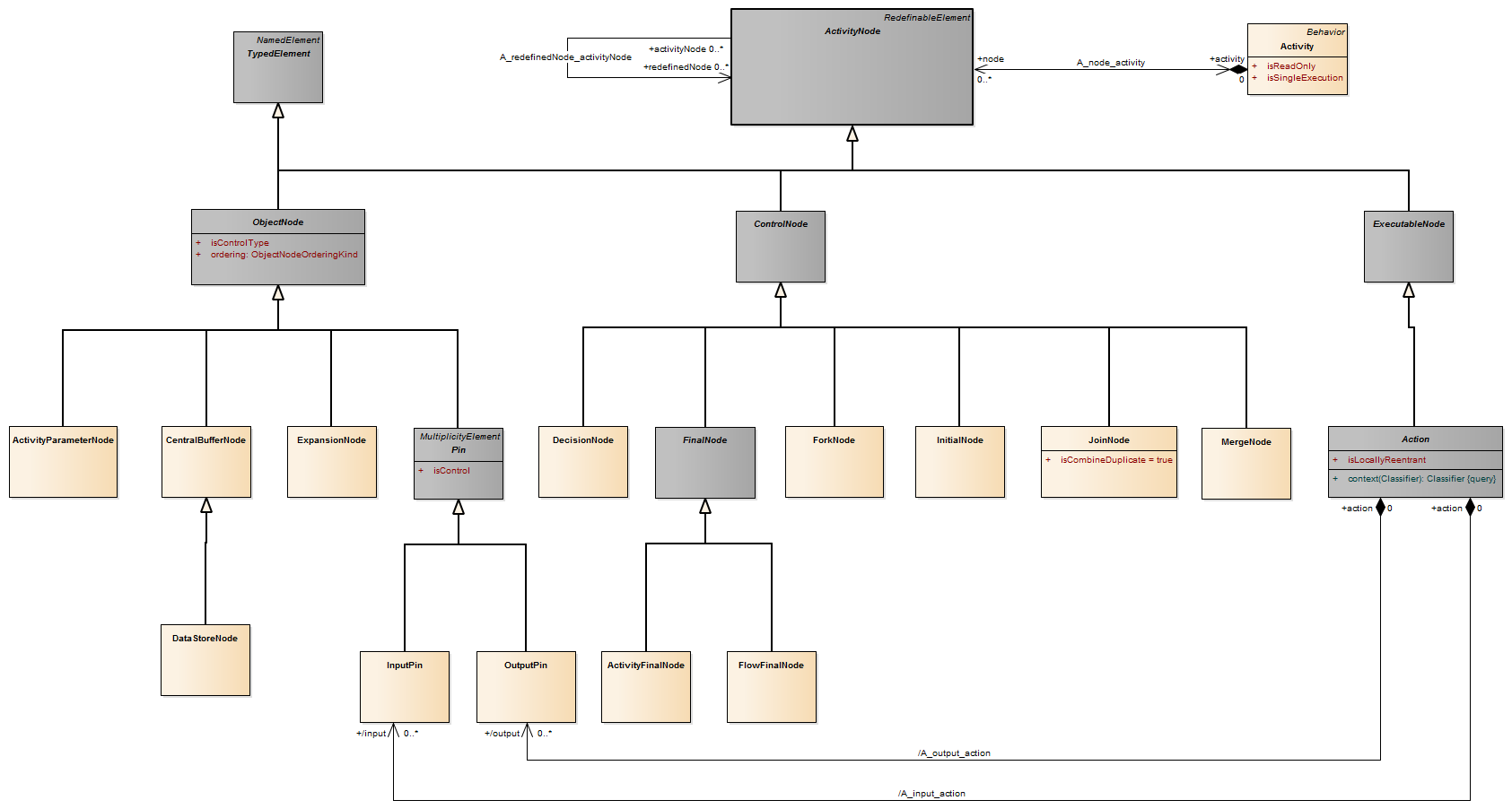
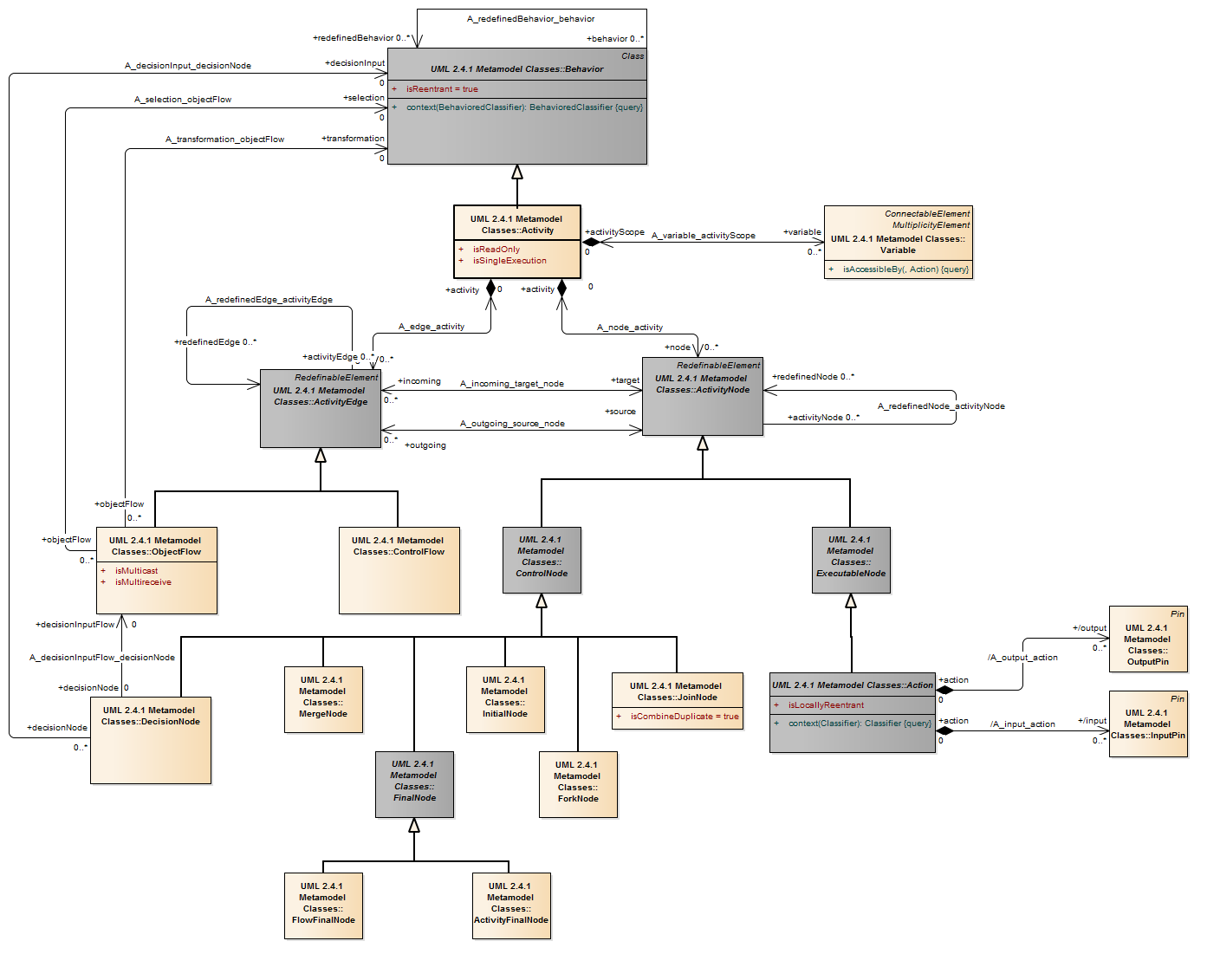
Description An object node is an activity node that indicates an instance of a particular classifier, possibly in a particular state, may be available at a particular point in the activity. Object nodes can be used in a variety of ways, depending on where objects are flowing from and to, as described in the semantics sub clause.
Package CompleteActivities Complete object nodes add support for token selection, limitation on the number of tokens, specifying the state required for tokens, and carrying control values.
Constraints Package BasicActivities
[1] All edges coming into or going out of object nodes must be object flow edges.
Package CompleteActivities
[1] If an object node has a selection behavior, then the ordering of the object node is ordered and vice versa.
[2] A selection behavior has one input parameter and one output parameter. The input parameter must be a bag of elements of the same type as the object node or a supertype of the type of object node. The output parameter must be the same or a subtype of the type of object node. The behavior cannot have side effects.
Semantics Object nodes may only contain values at runtime that conform to the type of the object node, in the state or states specified, if any. If no type is specified, then the values may be of any type. Multiple tokens containing the same value may reside in the object node at the same time. This includes data values. A token in an object node can traverse only one of the outgoing edges. An object node may indicate that its type is to be treated as a control value, even if no type is specified for the node. Control edges may be used with the object node having control type.
Package CompleteActivities An object node may not contain more tokens than its upper bound. The upper bound must be a LiteralUnlimitedNatural. An upper bound of * means the upper bound is unlimited. See ObjectFlow for additional rules regarding when objects may traverse the edges incoming and outgoing from an object node.The ordering of an object node specifies the order in which tokens in the node are offered to the outgoing edges. This can be set to require that tokens do not overtake each other as they pass through the node (FIFO), or that they do (LIFO or modeler-defined ordering). Modeler-defined ordering is indicated by an ordering value of ordered, and a selection behavior that determines what token to offer to the edges. The selection behavior takes all the tokens in the object node as input and chooses a single token from those. It is executed whenever a token is to be offered to an edge. Because the behavior is used while offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. The selection behavior of an object node is overridden by any selection behaviors on its outgoing edges (see “ObjectFlow”). Overtaking due to ordering is distinguished from the case where each invocation of the activity is handled by a separate execution of the activity. In this case, the tokens have no interaction with each other, because they flow through separate executions of the activity (see “Activity”).
Description
BroadcastSignalAction is an action that transmits a signal instance to all the potential target objects in the system, which may cause the firing of a state machine transitions or the execution of associated activities of a target object. The argument values are available to the execution of associated behaviors. The requestor continues execution immediately after the signals are sent out. It does not wait for receipt. Any reply messages are ignored and are not transmitted to the requestor.
Semantics
When all the prerequisites of the action execution are satisfied, a signal object is generated from the argument values according to signal and this signal object is transmitted concurrently to each of the implicit broadcast target objects in the system. The manner of identifying the set of objects that are broadcast targets is a semantic variation point and may be limited to some subset of all the objects that exist. There is no restriction on the location of target objects. The manner of transmitting the signal object, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
When a transmission arrives at a target object, it may invoke a behavior in the target object. The effect of receiving such transmission is specified in Clause 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
A broadcast signal action receives no reply from the invoked behavior; any attempted reply is simply ignored, and no transmission is performed to the requestor.
Semantic Variation Points
The determination of the set of broadcast target objects is a semantic variation point.
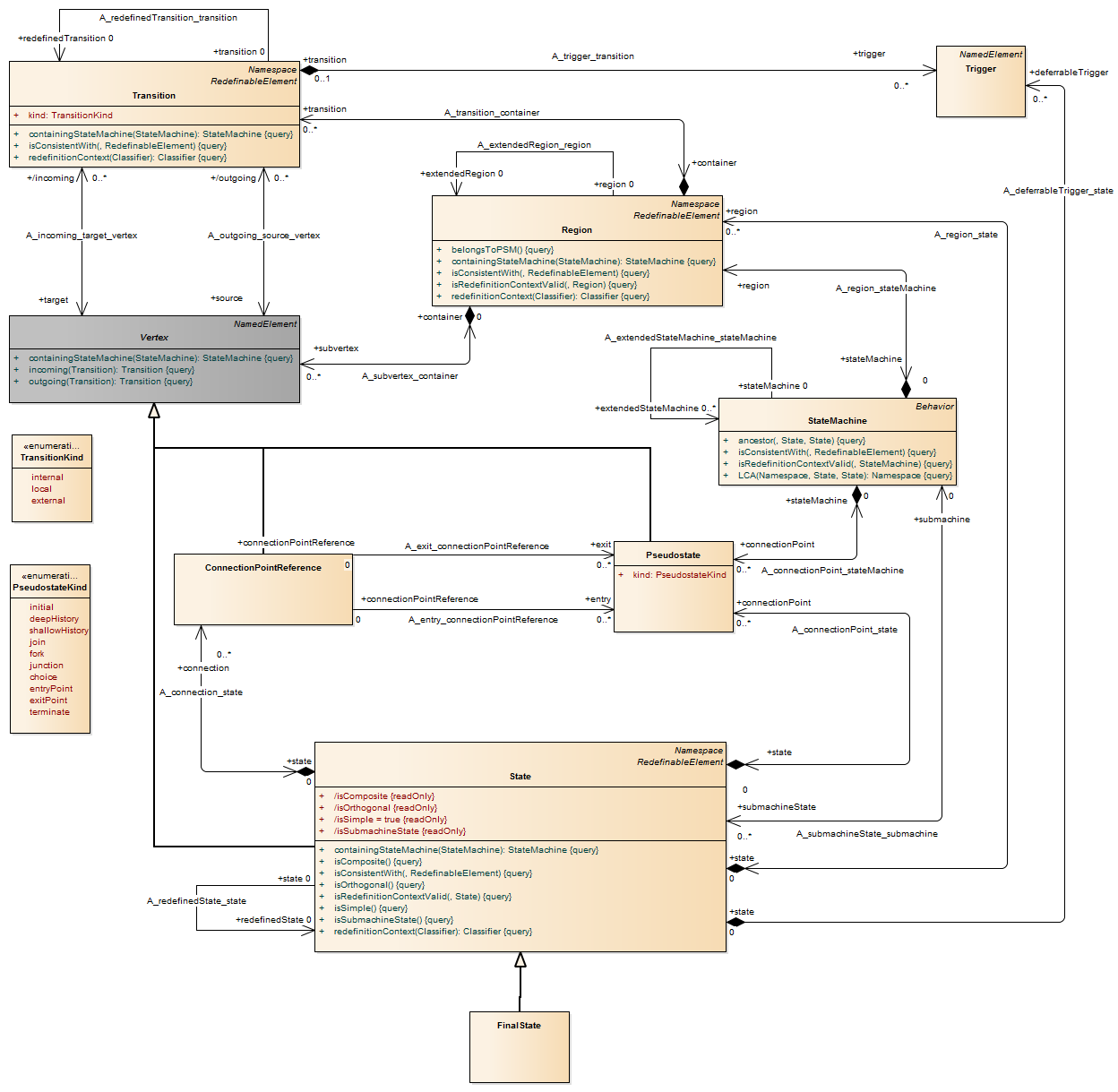
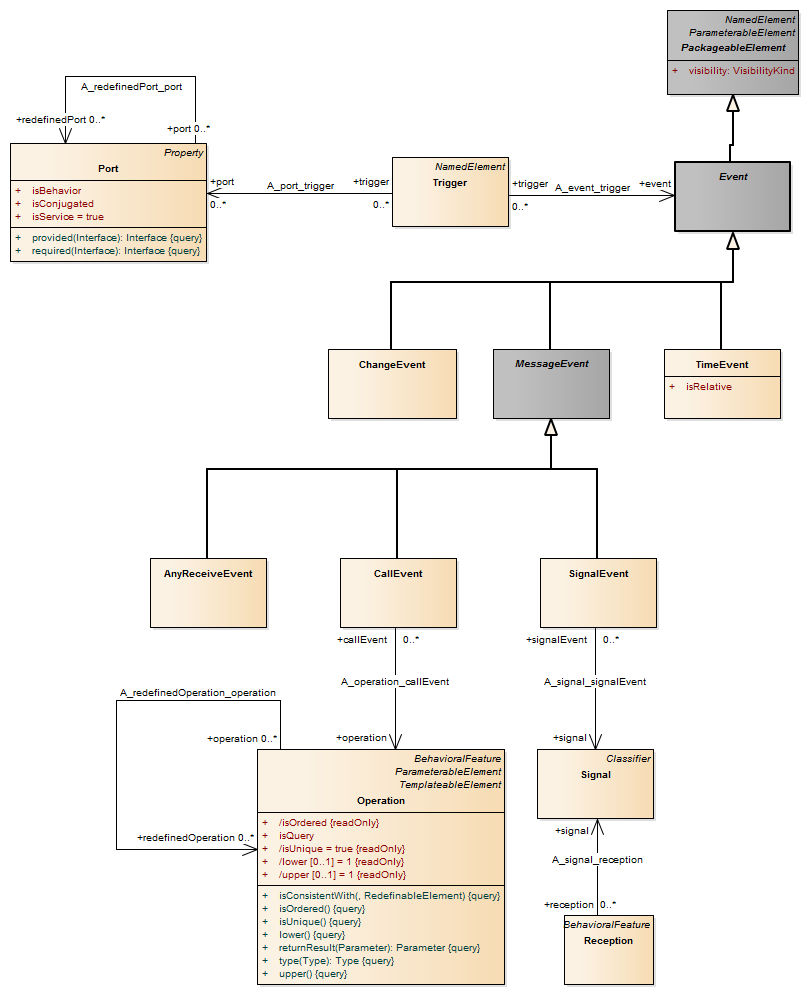
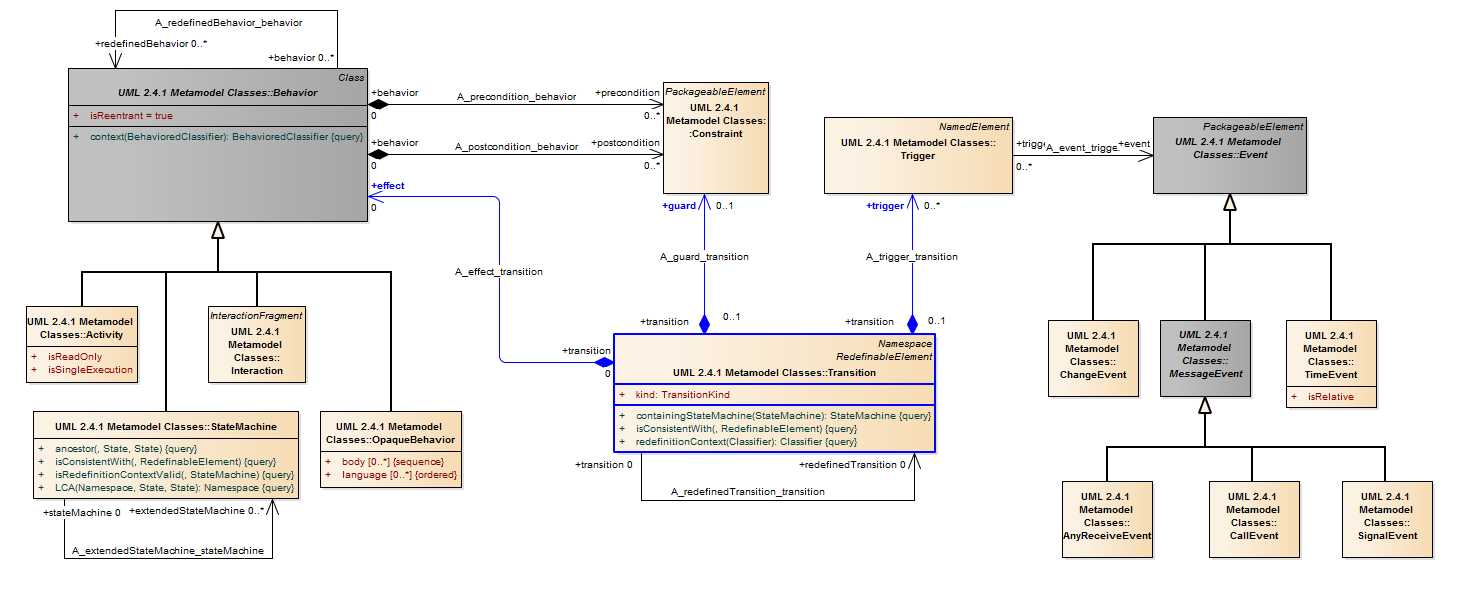
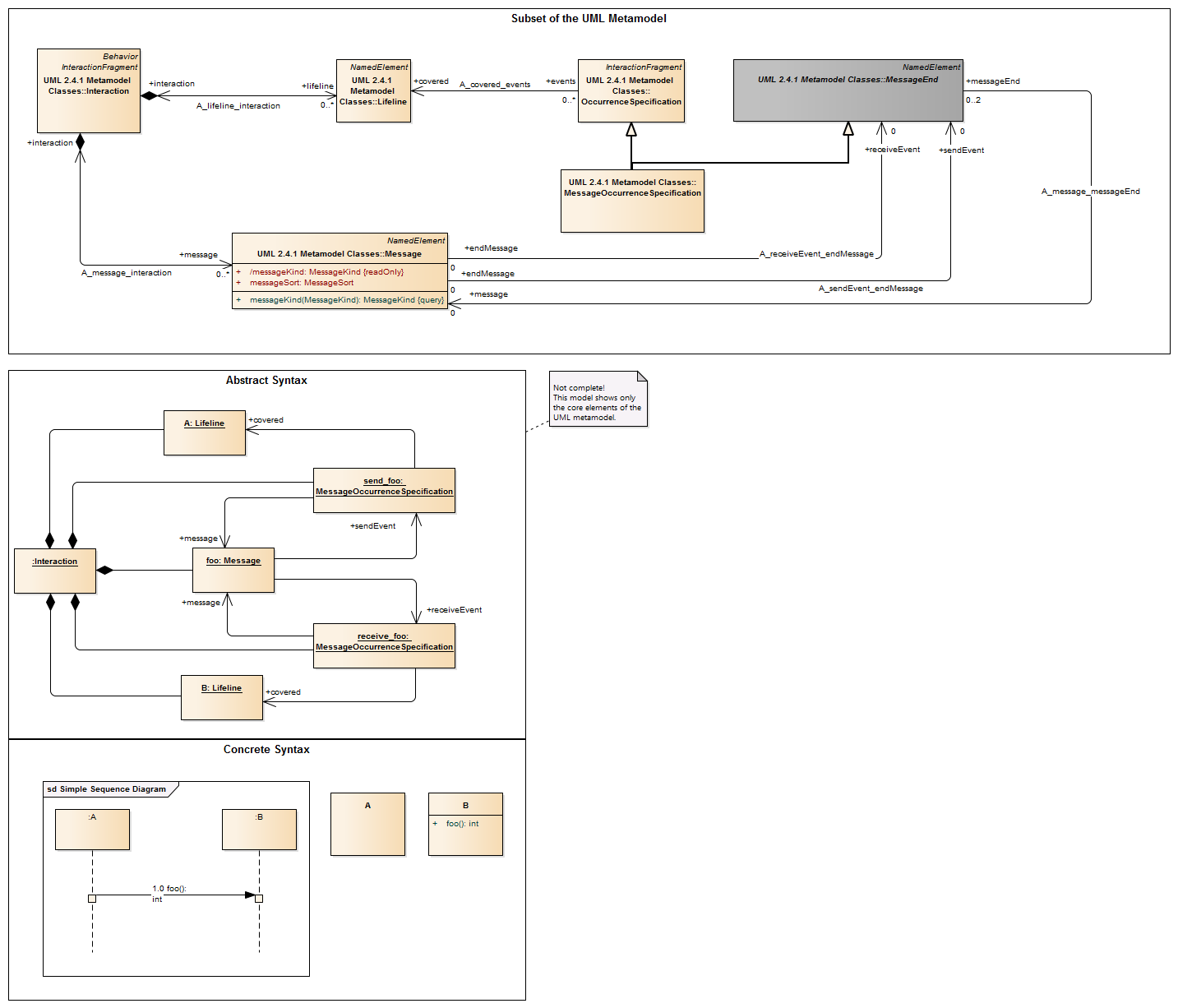
Description A transition is a directed relationship between a source vertex and a target vertex. It may be part of a compound transition, which takes the state machine from one state configuration to another, representing the complete response of the state machine to an occurrence of an event of a particular type.
Semantics High-level transitions Transitions originating from composite states themselves are called high-level or group transitions. If triggered, they result in exiting of all the substates of the composite state executing their exit activities starting with the innermost states in the active state configuration. Note that in terms of execution semantics, a high-level transition does not add specialized semantics, but rather reflects the semantics of exiting a composite state. A high-level transition with a target outside the composite state will imply the execution of the exit action of the composite state, while a high-level transition with a target inside the composite state will not imply execution of the exit action of the composite state. Compound transitions A compound transition is a derived semantic concept, represents a “semantically complete” path made of one or more transitions, originating from a set of states (as opposed to pseudo-state) and targeting a set of states. The transition execution semantics described below refer to compound transitions. In general, a compound transition is an acyclical unbroken chain of transitions joined via join, junction, choice, or fork pseudostates that define path from a set of source states (possibly a singleton) to a set of destination states, (possibly a singleton). For self-transitions, the same state acts as both the source and the destination set. A (simple) transition connecting two states is therefore a special common case of a compound transition. The tail of a compound transition may have multiple transitions originating from a set of mutually orthogonal regions that are joined by a join point. The head of a compound transition may have multiple transitions originating from a fork pseudostate targeted to a set of mutually orthogonal regions.
In a compound transition multiple outgoing transitions may emanate from a common junction point. In that case, only one of the outgoing transitions whose guard is true is taken. If multiple transitions have guards that are true, a transition from this set is chosen. The algorithm for selecting such a transition is not specified. Note that in this case, the guards are evaluated before the compound transition is taken. In a compound transition where multiple outgoing transitions emanate from a common choice point, the outgoing transition whose guard is true at the time the choice point is reached, will be taken. If multiple transitions have guards that are true, one transition from this set is chosen. The algorithm for selecting this transition is not specified. If no guards are true after the choice point has been reached, the model is ill-formed. The owner of a transition is not explicitly constrained, though the region must be owned directly or indirectly by the owning state machine context. A suggested owner of a transition is the LCA of the source and target vertices. Internal transitions An internal transition executes without exiting or re-entering the state in which it is defined. This is true even if the state machine is in a nested state within this state. Completion transitions and completion events A completion transition is a transition originating from a state or an exit point but which does not have an explicit trigger, although it may have a guard defined. A completion transition is implicitly triggered by a completion event. In case of a leaf state, a completion event is generated once the entry actions and the internal activities (“do” activities) have been completed. If no actions or activities exist, the completion event is generated upon entering the state. If the state is a composite state or a submachine state, a completion event is generated if either the submachine or the contained region has reached a final state and the state’s internal activities have been completed. This event is the implicit trigger for a completion transition. The completion event is dispatched before any other events in the pool and has no associated parameters. For instance, a completion transition emanating from an orthogonal composite state will be taken automatically as soon as all the orthogonal regions have reached their final state. If multiple completion transitions are defined for a state, then they should have mutually exclusive guard conditions.
Enabled (compound) transitions A transition is enabled if and only if: • All of its source states are in the active state configuration. • One of the triggers of the transition is satisfied by the event (type) of the current occurrence. An event satisfies a trigger if it matches the event specified by the trigger. In case of signal events, since signals are generalized concepts, a signal event satisfies a signal event associated with the same signal or a generalization thereof. If one of the triggers is for an AnyReceiveEvent, then a signal or call event satisfies this trigger if there is no other signal or call event trigger on the same transition, or any other transition having the same source vertex as the transition with the AnyReceiveEvent trigger (see also “AnyReceiveEvent (from Communications)” on page 444). • If there exists at least one full path from the source state configuration to either the target state configuration or to a dynamic choice point in which all guard conditions are true (transitions without guards are treated as if their guards are always true). Since more than one transition may be enabled by the same event, being enabled is a necessary but not sufficient condition for the firing of a transition.
Guards In a simple transition with a guard, the guard is evaluated before the transition is triggered. In compound transitions involving multiple guards, all guards are evaluated before a transition is triggered, unless there are choice points along one or more of the paths. The order in which the guards are evaluated is not defined. If there are choice points in a compound transition, only guards that precede the choice point are evaluated according to the above rule. Guards downstream of a choice point are evaluated if and when the choice point is reached (using the same rule as above). In other words, for guard evaluation, a choice point has the same effect as a state. Guards should not include expressions causing side effects. Models that violate this are considered ill-formed. Transition execution sequence Every transition, except for internal and local transitions, causes exiting of a source state, and entering of the target state. These two states, which may be composite, are designated as the main source and the main target of a transition. The least common ancestor (LCA) state of a (compound) transition is a region or an orthogonal state that is the LCA of the source and target states of the (compound) transition. The LCA operation is an operation defined for the StateMachine class. If the LCA is a Region, then the main source is a direct subvertex of the region that contains the source states, and the main target is the subvertex of the region that contains the target states. In the case where the LCA is an orthogonal state, the main source and the main target are both represented by the orthogonal state itself. The reason is that a transition crossing regions of an orthogonal state forces exit from the entire orthogonal state and re-entering of all of its regions.
Trigger (from InvocationActions) Description A trigger specification may be qualified by the port on which the event occurred.
Semantics Specifying one or more ports for an event implies that the event triggers the execution of an associated behavior only if the event was received via one of the specified ports.
Trigger (from Communications) Description A trigger specifies an event that may cause the execution of an associated behavior. An event is often ultimately caused by the execution of an action, but need not be.
Semantics Events may cause execution of behavior (e.g., the execution of the effect activity of a transition in a state machine). A trigger specifies the event that may trigger a behavior execution as well as any constraints on the event to filter out events not of interest. Events are often generated as a result of some action either within the system or in the environment surrounding the system. Upon their occurrence, events are placed into the input pool of the object where they occurred (see BehavioredClassifier on page 449). An event is dispatched when it is taken from the input pool and is processed by the classifier. At this point, the event is considered consumed and referred to as the current event. A consumed event is no longer available for processing. (Note that an event identified as deferred by a state that does not fire any trigger is not dispatched and is therefore never consumed; see “State (from BehaviorStateMachines, ProtocolStateMachines)”
Semantic Variation Points No assumptions are made about the time intervals between event occurrence, event dispatching, and consumption. This leaves open the possibility of different semantic variations such as zero-time semantics.
Description A vertex is an abstraction of a node in a state machine graph. In general, it can be the source or destination of any number of transitions.
Description Pseudostates are typically used to connect multiple transitions into more complex state transitions paths. For example, by combining a transition entering a fork pseudostate with a set of transitions exiting the fork pseudostate, we get a compound transition that leads to a set of orthogonal target states.
Semantics The specific semantics of a Pseudostate depends on the setting of its kind attribute. • An initial pseudostate represents a default vertex that is the source for a single transition to the default state of a composite state. There can be at most one initial vertex in a region. The outgoing transition from the initial vertex may have a behavior, but not a trigger or guard.
• deepHistory represents the most recent active configuration of the composite state that directly contains this pseudostate (e.g., the state configuration that was active when the composite state was last exited). A composite state can have at most one deep history vertex. At most one transition may originate from the history connector to the default deep history state. This transition is taken in case the composite state had never been active before. Entry actions of states entered on the implicit direct path from the deep history to the innermost state(s) represented by a deep history are performed. The entry action is preformed only once for each state in the active state configuration being restored. • shallowHistory represents the most recent active substate of its containing state (but not the substates of that substate). A composite state can have at most one shallow history vertex. A transition coming into the shallow history vertex is equivalent to a transition coming into the most recent active substate of a state. At most one transition may originate from the history connector to the default shallow history state. This transition is taken in case the composite state had never been active before. The entry action of the state represented by the shallow history is performed. • join vertices serve to merge several transitions emanating from source vertices in different orthogonal regions. The transitions entering a join vertex cannot have guards or triggers. • fork vertices serve to split an incoming transition into two or more transitions terminating on orthogonal target vertices (i.e., vertices in different regions of a composite state). The segments outgoing from a fork vertex must not have guards or triggers. • junction vertices are semantic-free vertices that are used to chain together multiple transitions. They are used to construct compound transition paths between states. For example, a junction can be used to converge multiple incoming transitions into a single outgoing transition representing a shared transition path (this is known as a merge). Conversely, they can be used to split an incoming transition into multiple outgoing transition segments with different guard conditions. This realizes a static conditional branch. (In the latter case, outgoing transitions whose guard conditions evaluate to false are disabled. A predefined guard denoted “else” may be defined for at most one outgoing transition. This transition is enabled if all the guards labeling the other transitions are false.) Static conditional branches are distinct from dynamic conditional branches that are realized by choice vertices (described below). • choice vertices which, when reached, result in the dynamic evaluation of the guards of the triggers of its outgoing transitions. This realizes a dynamic conditional branch. It allows splitting of transitions into multiple outgoing paths such that the decision on which path to take may be a function of the results of prior actions performed in the same run-to-completion step. If more than one of the guards evaluates to true, an arbitrary one is selected. If none of the guards evaluates to true, then the model is considered ill-formed. (To avoid this, it is recommended to define one outgoing transition with the predefined “else” guard for every choice vertex.) Choice vertices should be distinguished from static branch points that are based on junction points (described above). • An entry point pseudostate is an entry point of a state machine or composite state. In each region of the state machine or composite state it has at most a single transition to a vertex within the same region. • An exit point pseudostate is an exit point of a state machine or composite state. Entering an exit point within any region of the composite state or state machine referenced by a submachine state implies the exit of this composite state or submachine state and the triggering of the transition that has this exit point as source in the state machine enclosing the submachine or composite state. • Entering a terminate pseudostate implies that the execution of this state machine by means of its context object is terminated. The state machine does not exit any states nor does it perform any exit actions other than those associated with the transition leading to the terminate pseudostate. Entering a terminate pseudostate is equivalent to invoking a DestroyObjectAction.
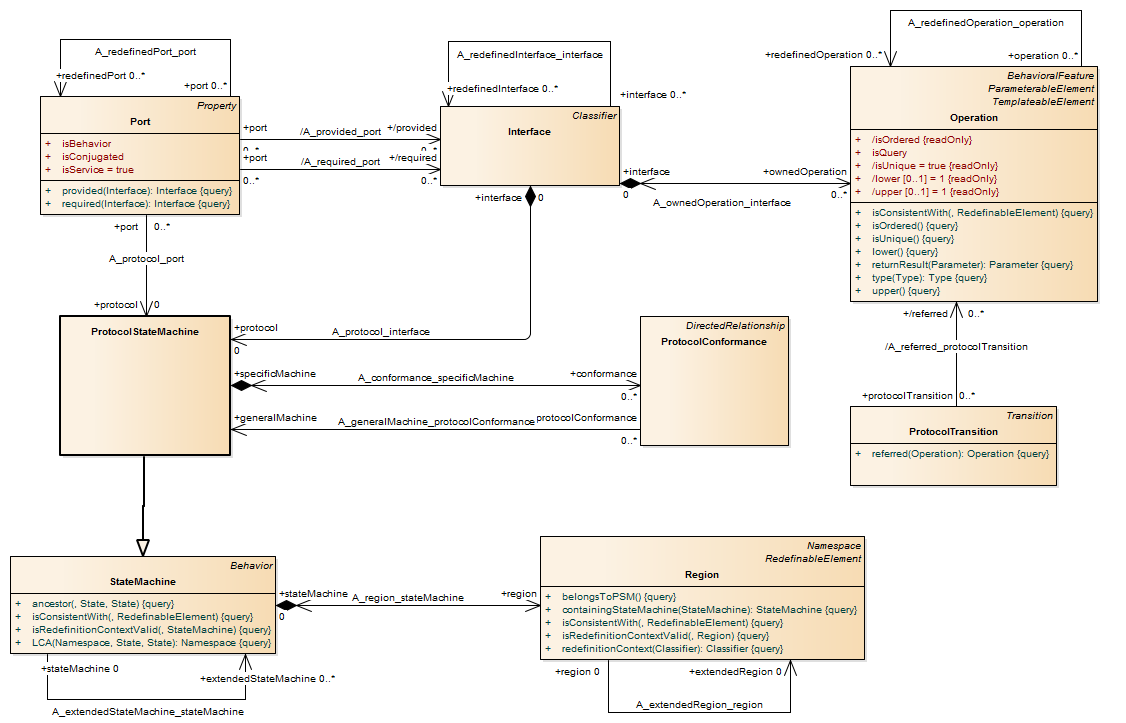
Description A region is an orthogonal part of either a composite state or a state machine. It contains states and transitions.
Semantics The semantics of regions is tightly coupled with states or state machines having regions, and it is therefore defined as part of the semantics for state and state machine. When a composite state or state machine is extended, each inherited region may be extended, and regions may be added.
A connection point reference represents a usage (as part of a submachine state) of an entry/exit point defined in the statemachine reference by the submachine state.
Description Connection point references of a submachine state can be used as sources/targets of transitions. They represent entries into or exits out of the submachine state machine referenced by the submachine state.
Semantics Connection point references are sources/targets of transitions implying exits out of/entries into the submachine state machine referenced by a submachine state. An entry point connection point reference as the target of a transition implies that the target of the transition is the entry point pseudostate as defined in the submachine of the submachine state. As a result, the regions of the submachine state machine are entered at the corresponding entry point pseudostates. An exit point connection point reference as the source of a transition implies that the source of the transition is the exit point pseudostate as defined in the submachine of the submachine state that has the exit point connection point defined. When a region of the submachine state machine has reached the corresponding exit points, the submachine state exits at this exit point.
Description State in Behavioral State machines A state models a situation during which some (usually implicit) invariant condition holds. The invariant may represent a static situation such as an object waiting for some external event to occur. However, it can also model dynamic conditions such as the process of performing some behavior (i.e., the model element under consideration enters the state when the behavior commences and leaves it as soon as the behavior is completed). The following kinds of states are distinguished: • Simple state, • composite state, and • submachine state.
A composite state is either a simple composite state (with just one region) or an orthogonal state (with more than one region). Simple state A simple state is a state that does not have substates (i.e., it has no regions and it has no submachine state machine). Composite state A composite state either contains one region or is decomposed into two or more orthogonal regions. Each region has a set of mutually exclusive disjoint subvertices and a set of transitions. A given state may only be decomposed in one of these two ways. In Figure 15.35, state CourseAttempt is an example of a composite state with a single region, whereas state “Studying” is a composite state that contains three regions. Any state enclosed within a region of a composite state is called a substate of that composite state. It is called a direct substate when it is not contained by any other state; otherwise, it is referred to as an indirect substate. Each region of a composite state may have an initial pseudostate and a final state. A transition to the enclosing state represents a transition to the initial pseudostate in each region. A newly-created object takes its topmost default transitions, originating from the topmost initial pseudostates of each region. A transition to a final state represents the completion of behavior in the enclosing region. Completion of behavior in all orthogonal regions represents completion of behavior by the enclosing state and triggers a completion event on the enclosing state. Completion of the topmost regions of an object corresponds to its termination. An entry pseudostate is used to join an external transition terminating on that entry point to an internal transition emanating from that entry point. An exit pseudostate is used to join an internal transition terminating on that exit point to an external transition emanating from that exit point. The main purpose of such entry and exit points is to execute the state entry and exit actions respectively in between the actions that are associated with the joined transitions. Semantic variation point (default entry rule) If a transition terminates on an enclosing state and the enclosed regions do not have an initial pseudostate, the interpretation of this situation is a semantic variation point. In some interpretations, this is considered an ill-formed model. That is, in those cases the initial pseudostate is mandatory. An alternative interpretation allows this situation and it means that, when such a transition is taken, the state machine stays in the composite state, without entering any of the regions or their substates. Submachine state A submachine state specifies the insertion of the specification of a submachine state machine. The state machine that contains the submachine state is called the containing state machine. The same state machine may be a submachine more than once in the context of a single containing state machine. A submachine state is semantically equivalent to a composite state. The regions of the submachine state machine are the regions of the composite state. The entry, exit, and behavior actions and internal transitions are defined as part of the state. Submachine state is a decomposition mechanism that allows factoring of common behaviors and their reuse. Transitions in the containing state machine can have entry/exit points of the inserted state machine as targets/sources.
State in Protocol State machines The states of protocol state machines are exposed to the users of their context classifiers. A protocol state represents an exposed stable situation of its context classifier: When an instance of the classifier is not processing any operation, users of this instance can always know its state configuration.
Semantics States in general The following applies to states in general. Special semantics applies to composite states and submachine states. Active states A state can be active or inactive during execution. A state becomes active when it is entered as a result of some transition, and becomes inactive if it is exited as a result of a transition. A state can be exited and entered as a result of the same transition (e.g., self transition). State entry and exit Whenever a state is entered, it executes its entry behavior before any other action is executed. Conversely, whenever a state is exited, it executes its exit behavior as the final step prior to leaving the state. Behavior in state (do-activity) The behavior represents the execution of a behavior, that occurs while the state machine is in the corresponding state. The behavior starts executing upon entering the state, following the entry behavior. If the behavior completes while the state is still active, it raises a completion event. In case where there is an outgoing completion transition (see below) the state will be exited. Upon exit, the behavior is terminated before the exit behavior is executed. If the state is exited as a result of the firing of an outgoing transition before the completion of the behavior, the behavior is aborted prior to its completion. Deferred events A state may specify a set of event types that may be deferred in that state. An event that does not trigger any transitions in the current state, will not be dispatched if its type matches one of the types in the deferred event set of that state. Instead, it remains in the event pool while another non-deferred event is dispatched instead. This situation persists until a state is reached where either the event is no longer deferred or where the event triggers a transition.
State redefinition A state may be redefined. A simple state can be redefined (extended) to become a composite state (by adding a region) and a composite state can be redefined (extended) by adding regions and by adding vertices, states, entry/exit/do activities (if the general state has none), and transitions to inherited regions. The redefinition of a state applies to the whole state machine. For example, if a state list as part of the extended state machine includes a state that is redefined, then the state list for the extension state machine includes the redefined state. Composite state Active state configurations In a hierarchical state machine more than one state can be active at the same time. If the state machine is in a simple state that is contained in a composite state, then all the composite states that either directly or transitively contain the simple state are also active. Furthermore, since the state machine as a whole and some of the composite states in this hierarchy may be orthogonal (i.e., containing regions), the current active “state” is actually represented by a set of trees of states starting with the top-most states of the root regions down to the innermost active substate. We refer to such a state tree as a state configuration. Except during transition execution, the following invariants always apply to state configurations: • If a composite state is active and not orthogonal, at most one of its substates is active. • If the composite state is active and orthogonal, all of its regions are active, with at most one substate in each region. Entering a non-orthogonal composite state Upon entering a composite state, the following cases are differentiated: • Default entry: Graphically, this is indicated by an incoming transition that terminates on the outside edge of the composite state. In this case, the default entry rule is applied (see Semantic variation point (default entry rule)). If there is a guard on the trigger of the transition, it must be enabled (true). (A disabled initial transition is an ill-defined execution state and its handling is not defined.) The entry behavior of the composite state is executed before the behavior associated with the initial transition. • Explicit entry: If the transition goes to a substate of the composite state, then that substate becomes active and its entry code is executed after the execution of the entry code of the composite state. This rule applies recursively if the transition terminates on a transitively nested substate. • Shallow history entry: If the transition terminates on a shallow history pseudostate, the active substate becomes the most recently active substate prior to this entry, unless the most recently active substate is the final state or if this is the first entry into this state. In the latter two cases, the default history state is entered. This is the substate that is target of the transition originating from the history pseudostate. (If no such transition is specified, the situation is ill-defined and its handling is not defined.) If the active substate determined by history is a composite state, then it proceeds with its default entry. • Deep history entry: The rule here is the same as for shallow history except that the rule is applied recursively to all levels in the active state configuration below this one. • Entry point entry: If a transition enters a composite state through an entry point pseudostate, then the entry behavior is executed before the action associated with the internal transition emanating from the entry point.
Entering an orthogonal composite state Whenever an orthogonal composite state is entered, each one of its orthogonal regions is also entered, either by default or explicitly. If the transition terminates on the edge of the composite state, then all the regions are entered using default entry. If the transition explicitly enters one or more regions (in case of a fork), these regions are entered explicitly and the others by default. Exiting non-orthogonal state When exiting from a composite state, the active substate is exited recursively. This means that the exit activities are executed in sequence starting with the innermost active state in the current state configuration. If, in a composite state, the exit occurs through an exit point pseudostate the exit behavior of the state is executed after the behavior associated with the transition incoming to the exit point. Exiting an orthogonal state When exiting from an orthogonal state, each of its regions is exited. After that, the exit activities of the state are executed. Deferred events Composite states introduce potential event deferral conflicts. Each of the substates may defer or consume an event, potentially conflicting with the composite state (e.g., a substate defers an event while the composite state consumes it, or vice versa). In case of a composite orthogonal state, substates of orthogonal regions may also introduce deferral conflicts. The conflict resolution follows the triggering priorities, where nested states override enclosing states. In case of a conflict between states in different orthogonal regions, a consumer state overrides a deferring state.
Submachine state A submachine state is semantically equivalent to the composite state defined by the referenced state machine. Entering and leaving this composite state is, in contrast to an ordinary composite state, via entry and exit points. A submachine composite state machine can be entered via its default (initial) pseudostate or via any of its entry points (i.e., it may imply entering a non-orthogonal or an orthogonal composite state with regions). Entering via the initial pseudostate has the same meaning as for ordinary composite states. An entry point is equivalent with a junction pseudostate (fork in case the composite state is orthogonal): Entering via an entry point implies that the entry behavior of the composite state is executed, followed by the (partial) transition(s) from the entry point to the target state(s) within the composite state. As for default initial transitions, guards associated with the triggers of these entry point transitions must evaluate to true in order for the specification not to be ill-formed. Similarly, it can be exited as a result of reaching its final state, by a “group” transition that applies to all substates in the submachine state composite state, or via any of its exit points. Exiting via a final state or by a group transition has the same meaning as for ordinary composite states. An exit point is equivalent with a junction pseudostate (join in case the composite state is orthogonal): Exiting via an exit point implies that first behavior of the transition with the exit point as target is executed, followed by the exit behavior of the composite state.
Description A state machine owns one or more regions, which in turn own vertices and transitions. The behaviored classifier context owning a state machine defines which signal and call triggers are defined for the state machine, and which attributes and operations are available in activities of the state machine. Signal triggers and call triggers for the state machine are defined according to the receptions and operations of this classifier. As a kind of behavior, a state machine may have an associated behavioral feature (specification) and be the method of this behavioral feature. In this case the state machine specifies the behavior of this behavioral feature. The parameters of the state machine in this case match the parameters of the behavioral feature and provide the means for accessing (within the state machine) the behavioral feature parameters. A state machine without a context classifier may use triggers that are independent of receptions or operations of a classifier, i.e., either just signal triggers or call triggers based upon operation template parameters of the (parameterized) statemachine.
Semantics The event pool for the state machine is the event pool of the instance according to the behaviored context classifier, or the classifier owning the behavioral feature for which the state machine is a method. Event processing - run-to-completion step Event occurrences are detected, dispatched, and then processed by the state machine, one at a time. The order of dequeuing is not defined, leaving open the possibility of modeling different priority-based schemes. The semantics of event occurrence processing is based on the run-to-completion assumption, interpreted as run-to-completion processing. Run-to-completion processing means that an event occurrence can only be taken from the pool and dispatched if the processing of the previous current occurrence is fully completed. Run-to-completion may be implemented in various ways. For active classes, it may be realized by an event-loop running in its own thread, and that reads event occurrences from a pool. For passive classes it may be implemented as a monitor. The processing of a single event occurrence by a state machine is known as a run-to-completion step. Before commencing on a run-to-completion step, a state machine is in a stable state configuration with all entry/exit/internal activities (but not necessarily state (do) activities) completed. The same conditions apply after the run-to-completion step is completed. Thus, an event occurrence will never be processed while the state machine is in some intermediate and inconsistent situation. The run-to-completion step is the passage between two state configurations of the state machine. The run-to-completion assumption simplifies the transition function of the state machine, since concurrency conflicts are avoided during the processing of event, allowing the state machine to safely complete its run-to-completion step.
When an event occurrence is detected and dispatched, it may result in one or more transitions being enabled for firing. If no transition is enabled and the event (type) is not in the deferred event list of the current state configuration, the event occurrence is discarded and the run-to-completion step is completed. In the presence of orthogonal regions it is possible to fire multiple transitions as a result of the same event occurrence — as many as one transition in each region in the current state configuration. In case where one or more transitions are enabled, the state machine selects a subset and fires them. Which of the enabled transitions actually fire is determined by the transition selection algorithm described below. The order in which selected transitions fire is not defined. Each orthogonal region in the active state configuration that is not decomposed into orthogonal regions (i.e., “bottom-level” region) can fire at most one transition as a result of the current event occurrence. When all orthogonal regions have finished executing the transition, the current event occurrence is fully consumed, and the run-to-completion step is completed. During a transition, a number of actions may be executed. If such an action is a synchronous operation invocation on an object executing a state machine, then the transition step is not completed until the invoked object completes its run-to-completion step.
Run-to-completion and concurrency It is possible to define state machine semantics by allowing the run-to-completion steps to be applied orthogonally to the orthogonal regions of a composite state, rather than to the whole state machine. This would allow the event serialization constraint to be relaxed. However, such semantics are quite subtle and difficult to implement. Therefore, the dynamic semantics defined in this document are based on the premise that a single run-to-completion step applies to the entire state machine and includes the steps taken by orthogonal regions in the active state configuration. In case of active objects, where each object has its own thread of execution, it is very important to clearly distinguish the notion of run to completion from the concept of thread pre-emption. Namely, run-to-completion event handling is performed by a thread that, in principle, can be pre-empted and its execution suspended in favor of another thread executing on the same processing node. (This is determined by the scheduling policy of the underlying thread environment — no assumptions are made about this policy.) When the suspended thread is assigned processor time again, it resumes its event processing from the point of pre-emption and, eventually, completes its event processing.
Conflicting transitions It was already noted that it is possible for more than one transition to be enabled within a state machine. If that happens, then such transitions may be in conflict with each other. For example, consider the case of two transitions originating from the same state, triggered by the same event, but with different guards. If that event occurs and both guard conditions are true, then only one transition will fire. In other words, in case of conflicting transitions, only one of them will fire in a single run-to-completion step. Two transitions are said to conflict if they both exit the same state, or, more precisely, that the intersection of the set of states they exit is non-empty. Only transitions that occur in mutually orthogonal regions may be fired simultaneously. This constraint guarantees that the new active state configuration resulting from executing the set of transitions is well-formed. An internal transition in a state conflicts only with transitions that cause an exit from that state.
Firing priorities In situations where there are conflicting transitions, the selection of which transitions will fire is based in part on an implicit priority. These priorities resolve some transition conflicts, but not all of them. The priorities of conflicting transitions are based on their relative position in the state hierarchy. By definition, a transition originating from a substate has higher priority than a conflicting transition originating from any of its containing states. The priority of a transition is defined based on its source state. The priority of joined transitions is based on the priority of the transition with the most transitively nested source state. In general, if t1 is a transition whose source state is s1, and t2 has source s2, then:
• If s1 is a direct or transitively nested substate of s2, then t1 has higher priority than t2.
• If s1 and s2 are not in the same state configuration, then there is no priority difference between t1 and t2.
Transition selection algorithm The set of transitions that will fire is a maximal set of transitions that satisfies the following conditions: • All transitions in the set are enabled.
• There are no conflicting transitions within the set.
• There is no transition outside the set that has higher priority than a transition in the set (that is, enabled transitions with highest priorities are in the set while conflicting transitions with lower priorities are left out). This can be easily implemented by a greedy selection algorithm, with a straightforward traversal of the active state configuration. States in the active state configuration are traversed starting with the innermost nested simple states and working outwards. For each state at a given level, all originating transitions are evaluated to determine if they are enabled. This traversal guarantees that the priority principle is not violated. The only non-trivial issue is resolving transition conflicts across orthogonal states on all levels. This is resolved by terminating the search in each orthogonal state once a transition inside any one of its components is fired.
StateMachine extension A state machine is generalizable. A specialized state machine is an extension of the general state machine, in that regions, vertices, and transitions may be added; regions and states may be redefined (extended: simple states to composite states and composite states by adding states and transitions); and transitions can be redefined. As part of a classifier generalization, the classifierBehavior state machine of the general classifier and the method state machines of behavioral features of the general classifier can be redefined (by other state machines). These state machines may be specializations (extensions) of the corresponding state machines of the general classifier or of its behavioral features. A specialized state machine will have all the elements of the general state machine, and it may have additional elements. Regions may be added. Inherited regions may be redefined by extension: States and vertices are inherited, and states and transitions of the regions of the state machine may be redefined. A simple state can be redefined (extended) to a composite state, by adding one or more regions. A composite state can be redefined (extended) by either extending inherited regions or by adding regions as well as by adding entry and exit points. A region is extended by adding vertices, states, and transitions and by redefining states and transitions.
A submachine state may be redefined. The submachine state machine may be replaced by another submachine state machine, provided that it has the same entry/exit points as the redefined submachine state machine, but it may add entry/ exit points. Transitions can have their content and target state replaced, while the source state and trigger are preserved. In case of multiple general classifiers, extension implies that the extension state machine gets orthogonal regions for each of the state machines of the general classifiers in addition to the one of the specific classifier.
Description A special kind of state signifying that the enclosing region is completed. If the enclosing region is directly contained in a state machine and all other regions in the state machine also are completed, then it means that the entire state machine is completed.
Semantics When the final state is entered, its containing region is completed, which means that it satisfies the completion condition. The containing state for this region is considered completed when all contained regions are completed. If the region is contained in a state machine and all other regions in the state machine also are completed, the entire state machine terminates, implying the termination of the context object of the state machine.
Trigger (from InvocationActions) Description A trigger specification may be qualified by the port on which the event occurred.
Semantics Specifying one or more ports for an event implies that the event triggers the execution of an associated behavior only if the event was received via one of the specified ports.
Trigger (from Communications) Description A trigger specifies an event that may cause the execution of an associated behavior. An event is often ultimately caused by the execution of an action, but need not be.
Semantics Events may cause execution of behavior (e.g., the execution of the effect activity of a transition in a state machine). A trigger specifies the event that may trigger a behavior execution as well as any constraints on the event to filter out events not of interest. Events are often generated as a result of some action either within the system or in the environment surrounding the system. Upon their occurrence, events are placed into the input pool of the object where they occurred (see BehavioredClassifier on page 449). An event is dispatched when it is taken from the input pool and is processed by the classifier. At this point, the event is considered consumed and referred to as the current event. A consumed event is no longer available for processing. (Note that an event identified as deferred by a state that does not fire any trigger is not dispatched and is therefore never consumed; see “State (from BehaviorStateMachines, ProtocolStateMachines)”
Semantic Variation Points No assumptions are made about the time intervals between event occurrence, event dispatching, and consumption. This leaves open the possibility of different semantic variations such as zero-time semantics.
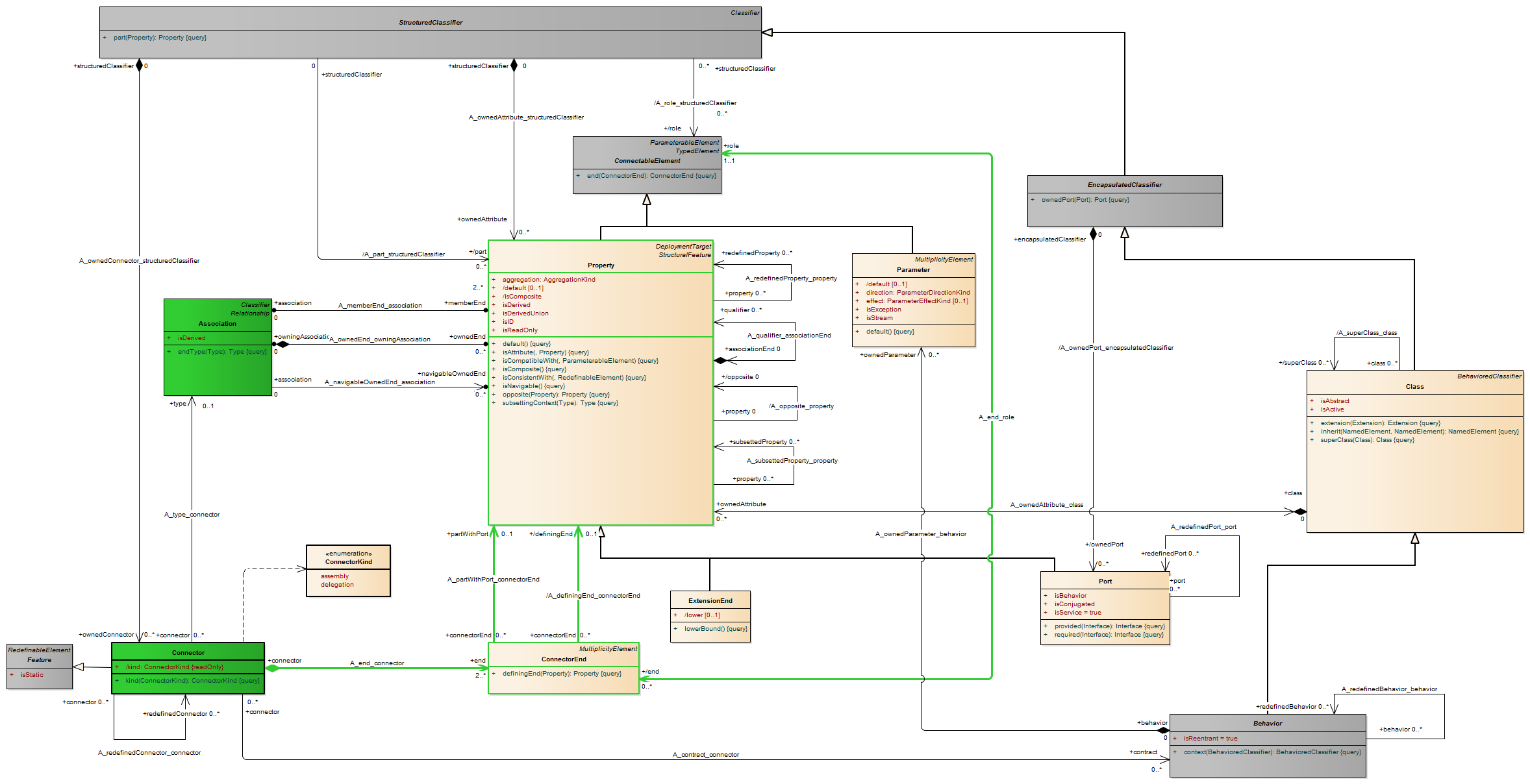
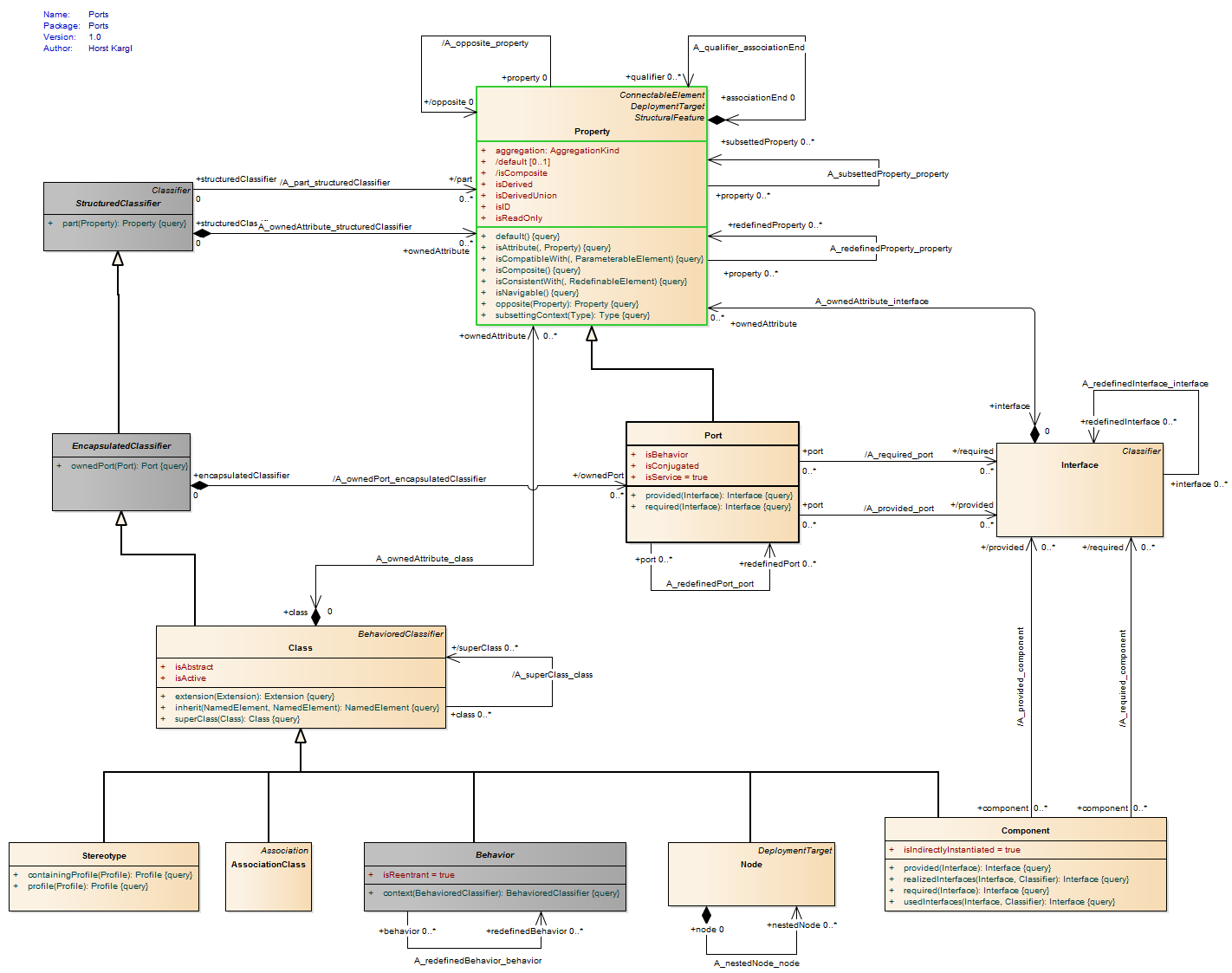
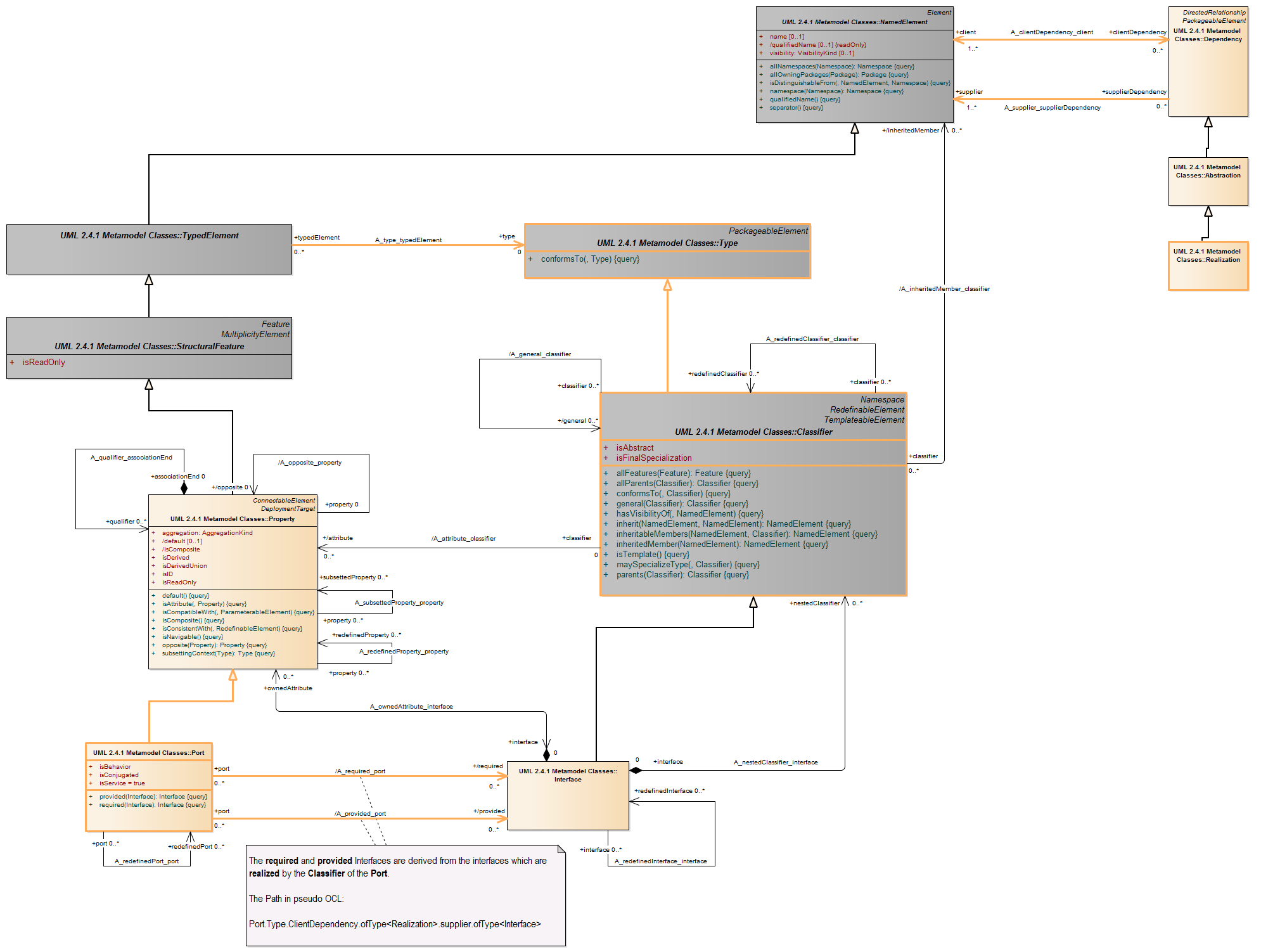
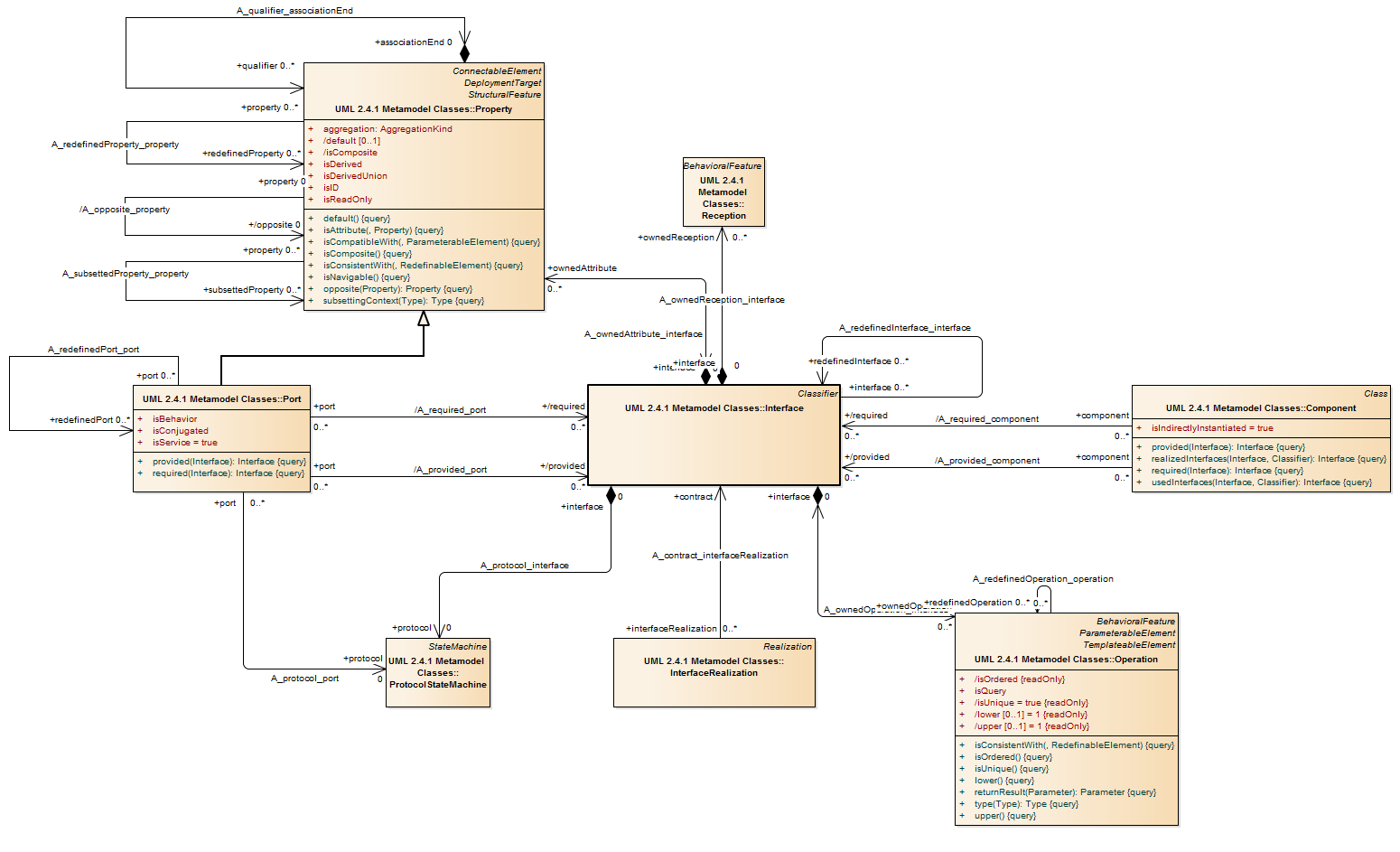
A port is a property of a classifier that specifies a distinct interaction point between that classifier and its environment or between the (behavior of the) classifier and its internal parts. Ports are connected to properties of the classifier by connectors through which requests can be made to invoke the behavioral features of a classifier. A Port may specify the services a classifier provides (offers) to its environment as well as the services that a classifier expects (requires) of its environment.
Description
Ports represent interaction points between a classifier and its environment. The interfaces associated with a port specify the nature of the interactions that may occur over a port. The required interfaces of a port characterize the requests that may be made from the classifier to its environment through this port. The provided interfaces of a port characterize requests to the classifier that its environment may make through this port. A port has the ability to specify that any requests arriving at this port are handled by the behavior of the instance of the owning classifier, rather than being forwarded to any contained instances, if any.
Semantics
A port represents an interaction point between a classifier instance and its environment or between a classifier instance and instances it may contain. A port by default has public visibility.
The required interfaces characterize services that the owning classifier expects from its environment and that it may access through this interaction point: Instances of this classifier expect that the features owned by its required interfaces will be offered by one or more instances in its environment.
The provided interfaces characterize the behavioral features that the owning classifier offers to its environment at this interaction point. The owning classifier must offer the features owned by the provided interfaces. The provided and required interfaces completely characterize any interaction that may occur between a classifier and its environment at a port with respect to the data communicated at this port and the behaviors that may be invoked through this port. The interfaces do not necessarily establish the exact sequences of interactions across the port. When an instance of a classifier is created, instances corresponding to each of its ports are created and held in the slots specified by the ports, in accordance with its multiplicity. These instances are referred to as “interaction points” and provide unique references. A link from that instance to the instance of the owning classifier is created through which communication is forwarded to the instance of the owning classifier or through which the owning classifier communicates with its environment. It is, therefore, possible for an instance to differentiate between requests for the invocation of a behavioral feature targeted at its different ports. Similarly, it is possible to direct such requests at a port, and the requests will be routed as specified by the links corresponding to connectors attached to this port. (In the following, “requests arriving at a port” shall mean “request occurrences arriving at the interaction point of this instance corresponding to this port.”)
If connectors are attached to both the port when used on a property within the internal structure of a classifier and the port on the container of an internal structure, the instance of the owning classifier will forward any requests arriving at this port along the link specified by those connectors. If there is a connector attached to only one side of a port, any requests arriving at this port will terminate at this port. For a behavior port, the instance of the owning classifier will handle requests arriving at this port, if this classifier has any behavior. If there is no behavior defined for this classifier, any communication arriving at a behavior port is lost.
Semantic Variation Points If several connectors are attached on one side of a port, then any request arriving at this port on a link derived from a connector on the other side of the port will be forwarded on links corresponding to these connectors. It is a semantic variation point whether these requests will be forwarded on all links, or on only one of those links. In the latter case, one possibility is that the link at which this request will be forwarded will be arbitrarily selected among those links leading to an instance that had been specified as being able to handle this request (i.e., this request is specified in a provided interface of the part corresponding to this instance).
A trigger for an AnyReceiveEvent is triggered by the receipt of any message that is not explicitly handled by any related trigger.
Semantics A trigger for AnyReceiveEvent may be triggered by the receipt of any message (signal send or operation call). However, if there is a related SignalEvent or CallEvent trigger that specifically matches the message, then the AnyReceiveEvent trigger is not triggered by the message. Which other triggers are related to an AnyReceiveEvent trigger depends on the context of the trigger (in particular, see 11.3.2, “AcceptEventAction (from CompleteActions)” on page 241 and 15.3.14, “Transition (from BehaviorStateMachines)”
A CallEvent models the receipt by an object of a message invoking a call of an operation.
Description A call event represents the reception of a request to invoke a specific operation. A call event is distinct from the call action that caused it. A call event may cause the invocation of a behavior that is the method of the operation referenced by the call request, if that operation is owned or inherited by the classifier that specified the receiver object.
Semantics A call event represents the reception of a request to invoke a specific operation on an object. The call event may result in the execution of the behavior that implements the called operation. A call event may, in addition, cause other responses, such as a state machine transition, as specified in the classifier behavior of the classifier that specified the receiver object. In that case, the additional behavior is invoked after the completion of the operation referenced by the call event. A call event makes available any argument values carried by the received call request to all behaviors caused by this event (such as transition actions or entry actions).
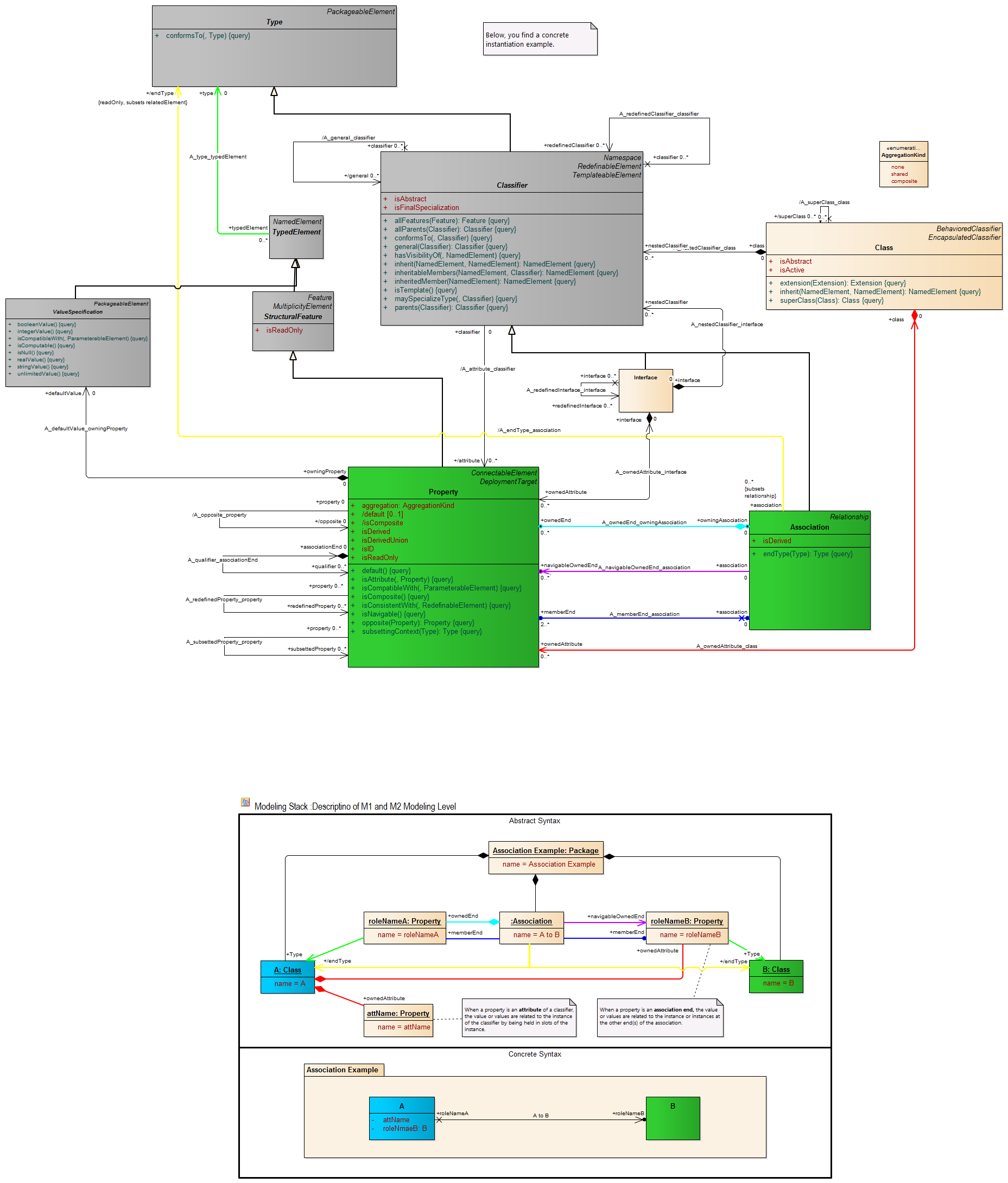
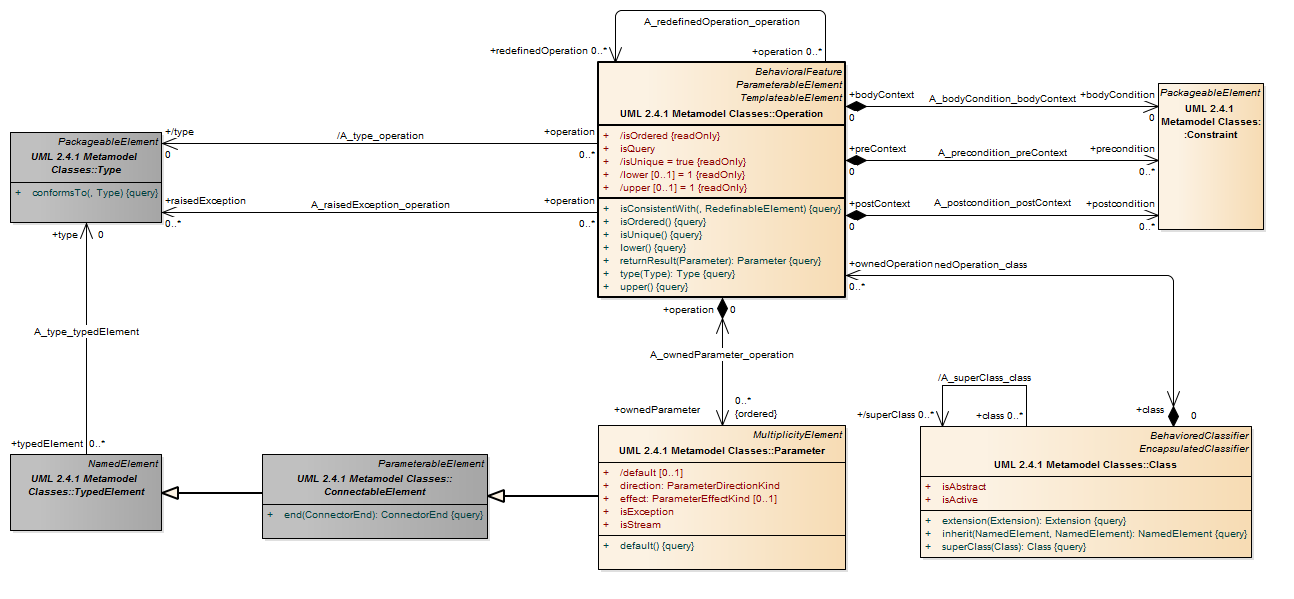
Operation (from Kernel, Interfaces) Description An operation is a behavioral feature of a classifier that specifies the name, type, parameters, and constraints for invoking an associated behavior.
Semantics An operation is invoked on an instance of the classifier for which the operation is a feature.
The preconditions for an operation define conditions that must be true when the operation is invoked. These preconditions may be assumed by an implementation of this operation. The postconditions for an operation define conditions that will be true when the invocation of the operation completes successfully, assuming the preconditions were satisfied. These postconditions must be satisfied by any implementation of the operation. The bodyCondition for an operation constrains the return result. The bodyCondition differs from postconditions in that the bodyCondition may be overridden when an operation is redefined, whereas postconditions can only be added during redefinition. An operation may raise an exception during its invocation. When an exception is raised, it should not be assumed that the postconditions or bodyCondition of the operation are satisfied. An operation may be redefined in a specialization of the featured classifier. This redefinition may specialize the types of the owned parameters, add new preconditions or postconditions, add new raised exceptions, or otherwise refine the specification of the operation. Each operation states whether or not its application will modify the state of the instance or any other element in the model (isQuery). An operation may be owned by and in the namespace of a class that provides the context for its possible redefinition. Semantic Variation Points The behavior of an invocation of an operation when a precondition is not satisfied is a semantic variation point. When operations are redefined in a specialization, rules regarding invariance, covariance, or contravariance of types and preconditions determine whether the specialized classifier is substitutable for its more general parent. Such rules constitute semantic variation points with respect to redefinition of operations.
Operation (from Communications) Description An operation may invoke both the execution of method behaviors as well as other behavioral responses. Semantics If an operation is not mentioned in a trigger of a behavior owned or inherited by the behaviored classifier owning the operation, then upon occurrence of a call event (representing the receipt of a request for the invocation of this operation) a resolution process is performed that determines the method behavior to be invoked, based on the operation and the data values corresponding to the parameters of the operation transmitted by the request; otherwise, the call event is placed into the input pool of the object (see BehavioredClassifier on page 449). If a behavior is triggered by this event, it begins with performing the resolution process and invoking the so determined method. Then the behavior continues its execution as specified. Operations specify immediate or triggered effects (see “BehavioredClassifier” )
Semantic Variation Points Resolution specifies how a particular behavior is identified to be executed in response to the invocation of an operation, using mechanisms such as inheritance. The mechanism by which the behavior to be invoked is determined from an operation and the transmitted argument data is a semantic variation point. In general, this mechanism may be complicated to include languages with features such as before-after methods, delegation, etc. In some of these variations, multiple behaviors may be executed as a result of a single call. The following defines a simple object-oriented process for this semantic variation point. • Object-oriented resolution When a call request is received, the class of the target object is examined for an owned operation with matching parameters (see “BehavioralFeature” on page 448). If such operation is found, the behavior associated as method is the result of the resolution; otherwise, the parent classifier is examined for a matching operation, and so on up the generalization hierarchy until a method is found or the root of the hierarchy is reached. If a class has multiple parents, all of them are examined for a method. If a method is found in exactly one ancestor class, then that method is the result of the resolution. If a method is found in more than one ancestor class along different paths, then the model is ill-formed under this semantic variation. If no method by the resolution process, then it is a semantic variation point what is to happen.
Description
A reception is a declaration stating that a classifier is prepared to react to the receipt of a signal. A reception designates a signal and specifies the expected behavioral response. The details of handling a signal are specified by the behavior associated with the reception or the classifier itself.
The receipt of a signal instance by the instance of the classifier owning a matching reception will cause the asynchronous invocation of the behavior specified as the method of the reception. A reception matches a signal if the received signal is a subtype of the signal referenced by the reception. The details of how the behavior responds to the received signal depend on the kind of behavior associated with the reception. (For example, if the reception is implemented by a state machine, the signal event will trigger a transition and subsequent effects as specified by that state machine.)
Receptions specify triggered effects (see “BehavioredClassifier” on page 448).
Description A protocol state machine is always defined in the context of a classifier. It specifies which operations of the classifier can be called in which state and under which condition, thus specifying the allowed call sequences on the classifier’s operations. A protocol state machine presents the possible and permitted transitions on the instances of its context classifier, together with the operations that carry the transitions. In this manner, an instance lifecycle can be created for a classifier, by specifying the order in which the operations can be activated and the states through which an instance progresses during its existence.
Semantics Protocol state machines help define the usage mode of the operations and receptions of a classifier by specifying: • In which context (under which states and pre conditions) they can be used. • If there is a protocol order between them. • What result is expected from their use. The states of a protocol state machine (protocol states) present an external view of the class that is exposed to its clients. Depending on the context, protocol states can correspond to the internal states of the instances as expressed by behavioral state machines, or they can be different. A protocol state machine expresses parts of the constraints that can be formulated for pre- and post-conditions on operations. The translation from protocol state machine to pre- and post-conditions on operations might not be straightforward, because the conditions would need to account for the operation call history on the instance, which may or may not be directly represented by its internal states. A protocol state machine provides a direct model of the state of interaction with the instance, so that constraints on interaction are more easily expressed. The protocol state machine defines all allowed transitions for each operation. The protocol state machine must represent all operations that can generate a given change of state for a class. Those operations that do not generate a transition are not represented in the protocol state machine. Protocol state machines constitute a means to formalize the interface of classes, and do not express anything except consistency rules for the implementation or dynamics of classes. Protocol state machine interpretation can vary from: 1. Declarative protocol state machines that specify the legal transitions for each operation. The exact triggering condition for the operations is not specified. This specification only defines the contract for the user of the context classifier. 2. Executable protocol state machines, that specify all events that an object may receive and handle, together with the transitions that are implied. In this case, the legal transitions for operations will exactly be the triggered transitions. The call trigger specifies the effect action, which is the call of the associated operation. The representation for both interpretations is the same, the only difference being the direct dynamic implication that the interpretation 2 provides. Elaborated forms of state machine modeling such as compound transitions, sub-state machines, composite states, and concurrent regions can also be used for protocol state machines. For example, concurrent regions make it possible to express protocol where an instance can have several active states simultaneously. Sub state machines and compound transitions are used as in behavioral state machines for factorizing complex protocol state machines.
A classifier may have several protocol state machines. This happens frequently, for example, when a class inherits several parent classes having protocol state machine, when the protocols are orthogonal. An alternative to multiple protocol state machines can always be found by having one protocol state machine, with sub state machines in concurrent regions.
Description A protocol transition (transition as specialized in the ProtocolStateMachines package) specifies a legal transition for an operation. Transitions of protocol state machines have the following information: a pre-condition (guard), on trigger, and a post-condition. Every protocol transition is associated to zero or one operation (referred BehavioralFeature) that belongs to the context classifier of the protocol state machine. The protocol transition specifies that the associated (referred) operation can be called for an instance in the origin state under the initial condition (guard), and that at the end of the transition, the destination state will be reached under the final condition (post).
Semantics No “effect” action The effect action is never specified. It is implicit, when the transition has a call trigger: the effect action will be the operation specified by the call trigger. It is unspecified in the other cases, where the transition only defines that a given event can be received under a specific state and pre-condition, and that a transition will lead to another state under a specific post-condition, whatever action will be made through this transition. Unexpected event reception The interpretation of the reception of an event in an unexpected situation (current state, state invariant, and pre-condition) is a semantic variation point: the event can be ignored, rejected, or deferred; an exception can be raised; or the application can stop on an error. It corresponds semantically to a pre-condition violation, for which no predefined behavior is defined in UML. Unexpected behavior The interpretation of an unexpected behavior, that is an unexpected result of a transition (wrong final state or final state invariant, or post-condition) is also a semantic variation point. However, this should be interpreted as an error of the implementation of the protocol state machine.
Equivalences to pre- and post-conditions of operations A protocol transition can be semantically interpreted in terms of pre- and post-conditions on the associated operation. For example, the transition in Figure 15.13 can be interpreted in the following way: 1. The operation “m1” can be called on an instance when it is in the protocol state “S1” under the condition “C1.” 2. When “m1” is called in the protocol state “S1” under the condition “C1,” then the protocol state “S2” must be reached under the condition “C2.”
Description A region is an orthogonal part of either a composite state or a state machine. It contains states and transitions.
Semantics The semantics of regions is tightly coupled with states or state machines having regions, and it is therefore defined as part of the semantics for state and state machine. When a composite state or state machine is extended, each inherited region may be extended, and regions may be added.
Description Protocol state machines can be redefined into more specific protocol state machines, or into behavioral state machines. Protocol conformance declares that the specific protocol state machine specifies a protocol that conforms to the general state machine one, or that the specific behavioral state machine abides by the protocol of the general protocol state machine. A protocol state machine is owned by a classifier. The classifiers owning a general state machine and an associated specific state machine are generally also connected by a generalization or a realization link.
Semantics Protocol conformance means that every rule and constraint specified for the general protocol state machine (state invariants, pre- and post-conditions for the operations referred by the protocol state machine) apply to the specific protocol or behavioral state machine. In most cases there are relationships between the classifier being the context of the specific state machine and the classifier being the context of the general protocol state machine. Generally, the former specializes or realizes the latter. It is also possible that the specific state machine is a behavioral state machine that implements the general protocol state machine, both state machines having the same class as a context.
A port is a property of a classifier that specifies a distinct interaction point between that classifier and its environment or between the (behavior of the) classifier and its internal parts. Ports are connected to properties of the classifier by connectors through which requests can be made to invoke the behavioral features of a classifier. A Port may specify the services a classifier provides (offers) to its environment as well as the services that a classifier expects (requires) of its environment.
Description
Ports represent interaction points between a classifier and its environment. The interfaces associated with a port specify the nature of the interactions that may occur over a port. The required interfaces of a port characterize the requests that may be made from the classifier to its environment through this port. The provided interfaces of a port characterize requests to the classifier that its environment may make through this port. A port has the ability to specify that any requests arriving at this port are handled by the behavior of the instance of the owning classifier, rather than being forwarded to any contained instances, if any.
Semantics
A port represents an interaction point between a classifier instance and its environment or between a classifier instance and instances it may contain. A port by default has public visibility.
The required interfaces characterize services that the owning classifier expects from its environment and that it may access through this interaction point: Instances of this classifier expect that the features owned by its required interfaces will be offered by one or more instances in its environment.
The provided interfaces characterize the behavioral features that the owning classifier offers to its environment at this interaction point. The owning classifier must offer the features owned by the provided interfaces. The provided and required interfaces completely characterize any interaction that may occur between a classifier and its environment at a port with respect to the data communicated at this port and the behaviors that may be invoked through this port. The interfaces do not necessarily establish the exact sequences of interactions across the port. When an instance of a classifier is created, instances corresponding to each of its ports are created and held in the slots specified by the ports, in accordance with its multiplicity. These instances are referred to as “interaction points” and provide unique references. A link from that instance to the instance of the owning classifier is created through which communication is forwarded to the instance of the owning classifier or through which the owning classifier communicates with its environment. It is, therefore, possible for an instance to differentiate between requests for the invocation of a behavioral feature targeted at its different ports. Similarly, it is possible to direct such requests at a port, and the requests will be routed as specified by the links corresponding to connectors attached to this port. (In the following, “requests arriving at a port” shall mean “request occurrences arriving at the interaction point of this instance corresponding to this port.”)
If connectors are attached to both the port when used on a property within the internal structure of a classifier and the port on the container of an internal structure, the instance of the owning classifier will forward any requests arriving at this port along the link specified by those connectors. If there is a connector attached to only one side of a port, any requests arriving at this port will terminate at this port. For a behavior port, the instance of the owning classifier will handle requests arriving at this port, if this classifier has any behavior. If there is no behavior defined for this classifier, any communication arriving at a behavior port is lost.
Semantic Variation Points If several connectors are attached on one side of a port, then any request arriving at this port on a link derived from a connector on the other side of the port will be forwarded on links corresponding to these connectors. It is a semantic variation point whether these requests will be forwarded on all links, or on only one of those links. In the latter case, one possibility is that the link at which this request will be forwarded will be arbitrarily selected among those links leading to an instance that had been specified as being able to handle this request (i.e., this request is specified in a provided interface of the part corresponding to this instance).
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
Operation (from Kernel, Interfaces) Description An operation is a behavioral feature of a classifier that specifies the name, type, parameters, and constraints for invoking an associated behavior.
Semantics An operation is invoked on an instance of the classifier for which the operation is a feature.
The preconditions for an operation define conditions that must be true when the operation is invoked. These preconditions may be assumed by an implementation of this operation. The postconditions for an operation define conditions that will be true when the invocation of the operation completes successfully, assuming the preconditions were satisfied. These postconditions must be satisfied by any implementation of the operation. The bodyCondition for an operation constrains the return result. The bodyCondition differs from postconditions in that the bodyCondition may be overridden when an operation is redefined, whereas postconditions can only be added during redefinition. An operation may raise an exception during its invocation. When an exception is raised, it should not be assumed that the postconditions or bodyCondition of the operation are satisfied. An operation may be redefined in a specialization of the featured classifier. This redefinition may specialize the types of the owned parameters, add new preconditions or postconditions, add new raised exceptions, or otherwise refine the specification of the operation. Each operation states whether or not its application will modify the state of the instance or any other element in the model (isQuery). An operation may be owned by and in the namespace of a class that provides the context for its possible redefinition. Semantic Variation Points The behavior of an invocation of an operation when a precondition is not satisfied is a semantic variation point. When operations are redefined in a specialization, rules regarding invariance, covariance, or contravariance of types and preconditions determine whether the specialized classifier is substitutable for its more general parent. Such rules constitute semantic variation points with respect to redefinition of operations.
Operation (from Communications) Description An operation may invoke both the execution of method behaviors as well as other behavioral responses. Semantics If an operation is not mentioned in a trigger of a behavior owned or inherited by the behaviored classifier owning the operation, then upon occurrence of a call event (representing the receipt of a request for the invocation of this operation) a resolution process is performed that determines the method behavior to be invoked, based on the operation and the data values corresponding to the parameters of the operation transmitted by the request; otherwise, the call event is placed into the input pool of the object (see BehavioredClassifier on page 449). If a behavior is triggered by this event, it begins with performing the resolution process and invoking the so determined method. Then the behavior continues its execution as specified. Operations specify immediate or triggered effects (see “BehavioredClassifier” )
Semantic Variation Points Resolution specifies how a particular behavior is identified to be executed in response to the invocation of an operation, using mechanisms such as inheritance. The mechanism by which the behavior to be invoked is determined from an operation and the transmitted argument data is a semantic variation point. In general, this mechanism may be complicated to include languages with features such as before-after methods, delegation, etc. In some of these variations, multiple behaviors may be executed as a result of a single call. The following defines a simple object-oriented process for this semantic variation point. • Object-oriented resolution When a call request is received, the class of the target object is examined for an owned operation with matching parameters (see “BehavioralFeature” on page 448). If such operation is found, the behavior associated as method is the result of the resolution; otherwise, the parent classifier is examined for a matching operation, and so on up the generalization hierarchy until a method is found or the root of the hierarchy is reached. If a class has multiple parents, all of them are examined for a method. If a method is found in exactly one ancestor class, then that method is the result of the resolution. If a method is found in more than one ancestor class along different paths, then the model is ill-formed under this semantic variation. If no method by the resolution process, then it is a semantic variation point what is to happen.
Description A state machine owns one or more regions, which in turn own vertices and transitions. The behaviored classifier context owning a state machine defines which signal and call triggers are defined for the state machine, and which attributes and operations are available in activities of the state machine. Signal triggers and call triggers for the state machine are defined according to the receptions and operations of this classifier. As a kind of behavior, a state machine may have an associated behavioral feature (specification) and be the method of this behavioral feature. In this case the state machine specifies the behavior of this behavioral feature. The parameters of the state machine in this case match the parameters of the behavioral feature and provide the means for accessing (within the state machine) the behavioral feature parameters. A state machine without a context classifier may use triggers that are independent of receptions or operations of a classifier, i.e., either just signal triggers or call triggers based upon operation template parameters of the (parameterized) statemachine.
Semantics The event pool for the state machine is the event pool of the instance according to the behaviored context classifier, or the classifier owning the behavioral feature for which the state machine is a method. Event processing - run-to-completion step Event occurrences are detected, dispatched, and then processed by the state machine, one at a time. The order of dequeuing is not defined, leaving open the possibility of modeling different priority-based schemes. The semantics of event occurrence processing is based on the run-to-completion assumption, interpreted as run-to-completion processing. Run-to-completion processing means that an event occurrence can only be taken from the pool and dispatched if the processing of the previous current occurrence is fully completed. Run-to-completion may be implemented in various ways. For active classes, it may be realized by an event-loop running in its own thread, and that reads event occurrences from a pool. For passive classes it may be implemented as a monitor. The processing of a single event occurrence by a state machine is known as a run-to-completion step. Before commencing on a run-to-completion step, a state machine is in a stable state configuration with all entry/exit/internal activities (but not necessarily state (do) activities) completed. The same conditions apply after the run-to-completion step is completed. Thus, an event occurrence will never be processed while the state machine is in some intermediate and inconsistent situation. The run-to-completion step is the passage between two state configurations of the state machine. The run-to-completion assumption simplifies the transition function of the state machine, since concurrency conflicts are avoided during the processing of event, allowing the state machine to safely complete its run-to-completion step.
When an event occurrence is detected and dispatched, it may result in one or more transitions being enabled for firing. If no transition is enabled and the event (type) is not in the deferred event list of the current state configuration, the event occurrence is discarded and the run-to-completion step is completed. In the presence of orthogonal regions it is possible to fire multiple transitions as a result of the same event occurrence — as many as one transition in each region in the current state configuration. In case where one or more transitions are enabled, the state machine selects a subset and fires them. Which of the enabled transitions actually fire is determined by the transition selection algorithm described below. The order in which selected transitions fire is not defined. Each orthogonal region in the active state configuration that is not decomposed into orthogonal regions (i.e., “bottom-level” region) can fire at most one transition as a result of the current event occurrence. When all orthogonal regions have finished executing the transition, the current event occurrence is fully consumed, and the run-to-completion step is completed. During a transition, a number of actions may be executed. If such an action is a synchronous operation invocation on an object executing a state machine, then the transition step is not completed until the invoked object completes its run-to-completion step.
Run-to-completion and concurrency It is possible to define state machine semantics by allowing the run-to-completion steps to be applied orthogonally to the orthogonal regions of a composite state, rather than to the whole state machine. This would allow the event serialization constraint to be relaxed. However, such semantics are quite subtle and difficult to implement. Therefore, the dynamic semantics defined in this document are based on the premise that a single run-to-completion step applies to the entire state machine and includes the steps taken by orthogonal regions in the active state configuration. In case of active objects, where each object has its own thread of execution, it is very important to clearly distinguish the notion of run to completion from the concept of thread pre-emption. Namely, run-to-completion event handling is performed by a thread that, in principle, can be pre-empted and its execution suspended in favor of another thread executing on the same processing node. (This is determined by the scheduling policy of the underlying thread environment — no assumptions are made about this policy.) When the suspended thread is assigned processor time again, it resumes its event processing from the point of pre-emption and, eventually, completes its event processing.
Conflicting transitions It was already noted that it is possible for more than one transition to be enabled within a state machine. If that happens, then such transitions may be in conflict with each other. For example, consider the case of two transitions originating from the same state, triggered by the same event, but with different guards. If that event occurs and both guard conditions are true, then only one transition will fire. In other words, in case of conflicting transitions, only one of them will fire in a single run-to-completion step. Two transitions are said to conflict if they both exit the same state, or, more precisely, that the intersection of the set of states they exit is non-empty. Only transitions that occur in mutually orthogonal regions may be fired simultaneously. This constraint guarantees that the new active state configuration resulting from executing the set of transitions is well-formed. An internal transition in a state conflicts only with transitions that cause an exit from that state.
Firing priorities In situations where there are conflicting transitions, the selection of which transitions will fire is based in part on an implicit priority. These priorities resolve some transition conflicts, but not all of them. The priorities of conflicting transitions are based on their relative position in the state hierarchy. By definition, a transition originating from a substate has higher priority than a conflicting transition originating from any of its containing states. The priority of a transition is defined based on its source state. The priority of joined transitions is based on the priority of the transition with the most transitively nested source state. In general, if t1 is a transition whose source state is s1, and t2 has source s2, then:
• If s1 is a direct or transitively nested substate of s2, then t1 has higher priority than t2.
• If s1 and s2 are not in the same state configuration, then there is no priority difference between t1 and t2.
Transition selection algorithm The set of transitions that will fire is a maximal set of transitions that satisfies the following conditions: • All transitions in the set are enabled.
• There are no conflicting transitions within the set.
• There is no transition outside the set that has higher priority than a transition in the set (that is, enabled transitions with highest priorities are in the set while conflicting transitions with lower priorities are left out). This can be easily implemented by a greedy selection algorithm, with a straightforward traversal of the active state configuration. States in the active state configuration are traversed starting with the innermost nested simple states and working outwards. For each state at a given level, all originating transitions are evaluated to determine if they are enabled. This traversal guarantees that the priority principle is not violated. The only non-trivial issue is resolving transition conflicts across orthogonal states on all levels. This is resolved by terminating the search in each orthogonal state once a transition inside any one of its components is fired.
StateMachine extension A state machine is generalizable. A specialized state machine is an extension of the general state machine, in that regions, vertices, and transitions may be added; regions and states may be redefined (extended: simple states to composite states and composite states by adding states and transitions); and transitions can be redefined. As part of a classifier generalization, the classifierBehavior state machine of the general classifier and the method state machines of behavioral features of the general classifier can be redefined (by other state machines). These state machines may be specializations (extensions) of the corresponding state machines of the general classifier or of its behavioral features. A specialized state machine will have all the elements of the general state machine, and it may have additional elements. Regions may be added. Inherited regions may be redefined by extension: States and vertices are inherited, and states and transitions of the regions of the state machine may be redefined. A simple state can be redefined (extended) to a composite state, by adding one or more regions. A composite state can be redefined (extended) by either extending inherited regions or by adding regions as well as by adding entry and exit points. A region is extended by adding vertices, states, and transitions and by redefining states and transitions.
A submachine state may be redefined. The submachine state machine may be replaced by another submachine state machine, provided that it has the same entry/exit points as the redefined submachine state machine, but it may add entry/ exit points. Transitions can have their content and target state replaced, while the source state and trigger are preserved. In case of multiple general classifiers, extension implies that the extension state machine gets orthogonal regions for each of the state machines of the general classifiers in addition to the one of the specific classifier.
Description A UseCase is a kind of behaviored classifier that represents a declaration of an offered behavior. Each use case specifies some behavior, possibly including variants, that the subject can perform in collaboration with one or more actors. Use cases define the offered behavior of the subject without reference to its internal structure. These behaviors, involving interactions between the actor and the subject, may result in changes to the state of the subject and communications with its environment. A use case can include possible variations of its basic behavior, including exceptional behavior and error handling. The subject of a use case could be a system or any other element that may have behavior, such as a component, subsystem, or class. Each use case specifies a unit of useful functionality that the subject provides to its users (i.e., a specific way of interacting with the subject). This functionality, which is initiated by an actor, must always be completed for the use case to complete. It is deemed complete if, after its execution, the subject will be in a state in which no further inputs or actions are expected and the use case can be initiated again or in an error state. Use cases can be used both for specification of the (external) requirements on a subject and for the specification of the functionality offered by a subject. Moreover, the use cases also state the requirements the specified subject poses on its environment by defining how they should interact with the subject so that it will be able to perform its services. The behavior of a use case can be described by a specification that is some kind of Behavior (through its ownedBehavior relationship), such as interactions, activities, and state machines, or by pre-conditions and post-conditions as well as by natural language text where appropriate. It may also be described indirectly through a Collaboration that uses the use case and its actors as the classifiers that type its parts. Which of these techniques to use depends on the nature of the use case behavior as well as on the intended reader. These descriptions can be combined. An example of a use case with an associated state machine description is shown in Figure 16.6.
Semantics An execution of a use case is an occurrence of emergent behavior. Every instance of a classifier realizing a use case must behave in the manner described by the use case. Use cases may have associated actors, which describes how an instance of the classifier realizing the use case and a user playing one of the roles of the actor interact. Two use cases specifying the same subject cannot be associated since each of them individually describes a complete usage of the subject. It is not possible to state anything about the internal behavior of the actor apart from its communications with the subject. When a use case has an association to an actor with a multiplicity that is greater than one at the actor end, it means that more than one actor instance is involved in initiating the use case. The manner in which multiple actors participate in the use case depends on the specific situation on hand and is not defined in this specification. For instance, a particular use case might require simultaneous (concurrent) action by two separate actors (e.g., in launching a nuclear missile) or it might require complementary and successive actions by the actors (e.g., one actor starting something and the other one stopping it).
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
BehavioredClassifier (from Interfaces) Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
A component represents a modular part of a system that encapsulates its contents and whose manifestation is replaceable within its environment. A component defines its behavior in terms of provided and required interfaces. As such, a component serves as a type whose conformance is defined by these provided and required interfaces (encompassing both their static as well as dynamic semantics). One component may therefore be substituted by another only if the two are type conformant. Larger pieces of a system’s functionality may be assembled by reusing components as parts in an encompassing component or assembly of components, and wiring them together. A component is modeled throughout the development life cycle and successively refined into deployment and run-time. A component may be manifest by one or more artifacts, and in turn, that artifact may be deployed to its execution environment. A deployment specification may define values that parameterize the component’s execution. (See Deployment clause).
Description BasicComponents A component is a subtype of Class that provides for a Component having attributes and operations, and being able to participate in Associations and Generalizations. A Component may form the abstraction for a set of realizingClassifiers that realize its behavior. In addition, because a Class itself is a subtype of an EncapsulatedClassifier, a Component may optionally have an internal structure and own a set of Ports that formalize its interaction points. A component has a number of provided and required Interfaces. A provided Interface is one that is either realized directly by the component or one of its realizingClassifiers, or it is provided by a public Port of the Component. A required interface is designated by a Usage Dependency from the Component or one of its realizingClassifiers, or it is required by a public Port.
PackagingComponents A component is extended to define the grouping aspects of packaging components. This defines the Namespace aspects of a Component through its inherited ownedMember and elementImport associations. In the namespace of a component, all model elements that are involved in or related to its definition are either owned or imported explicitly. This may include, for example, UseCases and Dependencies (e.g., mappings), Packages, Components, and Artifacts.
Semantics A component is a self contained unit that encapsulates the state and behavior of a number of classifiers. A component specifies a formal contract of the services that it provides to its clients and those that it requires from other components or services in the system in terms of its provided and required interfaces.
A component is a substitutable unit that can be replaced at design time or run-time by a component that offers equivalent functionality based on compatibility of its interfaces. As long as the environment obeys the constraints expressed by the provided and required interfaces of a component, it will be able to interact with this environment. Similarly, a system can be extended by adding new component types that add new functionality. The required and provided interfaces of a component allow for the specification of structural features such as attributes and association ends, as well as behavioral features such as operations and events. A component may implement a provided interface directly, or, its realizing classifiers may do so, or they may be inherited. The required and provided interfaces may optionally be organized through ports, these enable the definition of named sets of provided and required interfaces that are typically (but not always) addressed at run-time. A component has an external view (or “black-box” view) by means of its publicly visible properties and operations. Optionally, a behavior such as a protocol state machine may be attached to an interface, port, and to the component itself, to define the external view more precisely by making dynamic constraints in the sequence of operation calls explicit. Other behaviors may also be associated with interfaces or connectors to define the ‘contract’ between participants in a collaboration (e.g., in terms of use case, activity, or interaction specifications). The wiring between components in a system or other context can be structurally defined by using dependencies between compatible simple Ports, or between Usages and matching InterfaceRealizations that are represented by sockets and lollipops on Components on component diagrams. Creating a wiring Dependency between a Usage and a matching InterfaceRealization, or between compatible simple Ports, means that there may be some additional information, such as performance requirements, transport bindings, or other policies that determine that the interface is realized in a way that is suitable for consumption by the depending Component. Such additional information could be captured in a profile by means of stereotypes. A component also has an internal view (or “white-box” view) by means of its private properties and realizing classifiers. This view shows how the external behavior is realized internally. Dependencies on the external view provide a convenient overview of what may happen in the internal view; they do not prescribe what must happen. More detailed behavior specifications such as interactions and activities may be used to detail the mapping from external to internal behavior. A number of UML standard stereotypes exist that apply to component. For example, «subsystem» to model large-scale components, and «specification» and «realization» to model components with distinct specification and realization definitions, where one specification may have multiple realizations (see the UML Standard Elements Annex).
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
The ComponentRealization concept is specialized in the Components package to (optionally) define the Classifiers that realize the contract offered by a component in terms of its provided and required interfaces. The component forms an abstraction from these various Classifiers.
Description In the metamodel, a ComponentRealization is a subtype of Dependencies::Realization.
Semantics A component’s behavior may typically be realized (or implemented) by a number of Classifiers. In effect, it forms an abstraction for a collection of model elements. In that case, a component owns a set of Component Realization Dependencies to these Classifiers. It should be noted that for the purpose of applications that require multiple different sets of realizations for a single component specification, a set of standard stereotypes are defined in the UML Standard Profile. In particular, «specification» and «realization» are defined there for this purpose.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Description A connector end is an endpoint of a connector, which attaches the connector to a connectable element. Each connector end is part of one connector.
Semantics InternalStructures A connector end describes which connectable element is attached to the connector owning that end. Its multiplicity indicates the number of instances that may be linked to each instance of the property connected on the other end.
A Connector specifies links that enables communication between two or more instances. In contrast to Associations, which specify links between any instance of the associated Classifiers, Connectors specify links between instances playing the connected parts only. The connector concept is extended in the Components package to include contracts and notation.
A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling.
An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics
A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts.
Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only).
A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
The connector concept is extended in the Components package to include contracts and notation. A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling. An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts. Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only). A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
A component represents a modular part of a system that encapsulates its contents and whose manifestation is replaceable within its environment. A component defines its behavior in terms of provided and required interfaces. As such, a component serves as a type whose conformance is defined by these provided and required interfaces (encompassing both their static as well as dynamic semantics). One component may therefore be substituted by another only if the two are type conformant. Larger pieces of a system’s functionality may be assembled by reusing components as parts in an encompassing component or assembly of components, and wiring them together. A component is modeled throughout the development life cycle and successively refined into deployment and run-time. A component may be manifest by one or more artifacts, and in turn, that artifact may be deployed to its execution environment. A deployment specification may define values that parameterize the component’s execution. (See Deployment clause).
Description BasicComponents A component is a subtype of Class that provides for a Component having attributes and operations, and being able to participate in Associations and Generalizations. A Component may form the abstraction for a set of realizingClassifiers that realize its behavior. In addition, because a Class itself is a subtype of an EncapsulatedClassifier, a Component may optionally have an internal structure and own a set of Ports that formalize its interaction points. A component has a number of provided and required Interfaces. A provided Interface is one that is either realized directly by the component or one of its realizingClassifiers, or it is provided by a public Port of the Component. A required interface is designated by a Usage Dependency from the Component or one of its realizingClassifiers, or it is required by a public Port.
PackagingComponents A component is extended to define the grouping aspects of packaging components. This defines the Namespace aspects of a Component through its inherited ownedMember and elementImport associations. In the namespace of a component, all model elements that are involved in or related to its definition are either owned or imported explicitly. This may include, for example, UseCases and Dependencies (e.g., mappings), Packages, Components, and Artifacts.
Semantics A component is a self contained unit that encapsulates the state and behavior of a number of classifiers. A component specifies a formal contract of the services that it provides to its clients and those that it requires from other components or services in the system in terms of its provided and required interfaces.
A component is a substitutable unit that can be replaced at design time or run-time by a component that offers equivalent functionality based on compatibility of its interfaces. As long as the environment obeys the constraints expressed by the provided and required interfaces of a component, it will be able to interact with this environment. Similarly, a system can be extended by adding new component types that add new functionality. The required and provided interfaces of a component allow for the specification of structural features such as attributes and association ends, as well as behavioral features such as operations and events. A component may implement a provided interface directly, or, its realizing classifiers may do so, or they may be inherited. The required and provided interfaces may optionally be organized through ports, these enable the definition of named sets of provided and required interfaces that are typically (but not always) addressed at run-time. A component has an external view (or “black-box” view) by means of its publicly visible properties and operations. Optionally, a behavior such as a protocol state machine may be attached to an interface, port, and to the component itself, to define the external view more precisely by making dynamic constraints in the sequence of operation calls explicit. Other behaviors may also be associated with interfaces or connectors to define the ‘contract’ between participants in a collaboration (e.g., in terms of use case, activity, or interaction specifications). The wiring between components in a system or other context can be structurally defined by using dependencies between compatible simple Ports, or between Usages and matching InterfaceRealizations that are represented by sockets and lollipops on Components on component diagrams. Creating a wiring Dependency between a Usage and a matching InterfaceRealization, or between compatible simple Ports, means that there may be some additional information, such as performance requirements, transport bindings, or other policies that determine that the interface is realized in a way that is suitable for consumption by the depending Component. Such additional information could be captured in a profile by means of stereotypes. A component also has an internal view (or “white-box” view) by means of its private properties and realizing classifiers. This view shows how the external behavior is realized internally. Dependencies on the external view provide a convenient overview of what may happen in the internal view; they do not prescribe what must happen. More detailed behavior specifications such as interactions and activities may be used to detail the mapping from external to internal behavior. A number of UML standard stereotypes exist that apply to component. For example, «subsystem» to model large-scale components, and «specification» and «realization» to model components with distinct specification and realization definitions, where one specification may have multiple realizations (see the UML Standard Elements Annex).
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
The ComponentRealization concept is specialized in the Components package to (optionally) define the Classifiers that realize the contract offered by a component in terms of its provided and required interfaces. The component forms an abstraction from these various Classifiers.
Description In the metamodel, a ComponentRealization is a subtype of Dependencies::Realization.
Semantics A component’s behavior may typically be realized (or implemented) by a number of Classifiers. In effect, it forms an abstraction for a collection of model elements. In that case, a component owns a set of Component Realization Dependencies to these Classifiers. It should be noted that for the purpose of applications that require multiple different sets of realizations for a single component specification, a set of standard stereotypes are defined in the UML Standard Profile. In particular, «specification» and «realization» are defined there for this purpose.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
Description A control node is an activity node used to coordinate the flows between other nodes. It covers initial node, final node and its children, fork node, join node, decision node, and merge node.
Semantics See semantics at Activity. See subclasses for the semantics of each kind of control node.
Description An object node is an activity node that indicates an instance of a particular classifier, possibly in a particular state, may be available at a particular point in the activity. Object nodes can be used in a variety of ways, depending on where objects are flowing from and to, as described in the semantics sub clause.
Package CompleteActivities Complete object nodes add support for token selection, limitation on the number of tokens, specifying the state required for tokens, and carrying control values.
Constraints Package BasicActivities
[1] All edges coming into or going out of object nodes must be object flow edges.
Package CompleteActivities
[1] If an object node has a selection behavior, then the ordering of the object node is ordered and vice versa.
[2] A selection behavior has one input parameter and one output parameter. The input parameter must be a bag of elements of the same type as the object node or a supertype of the type of object node. The output parameter must be the same or a subtype of the type of object node. The behavior cannot have side effects.
Semantics Object nodes may only contain values at runtime that conform to the type of the object node, in the state or states specified, if any. If no type is specified, then the values may be of any type. Multiple tokens containing the same value may reside in the object node at the same time. This includes data values. A token in an object node can traverse only one of the outgoing edges. An object node may indicate that its type is to be treated as a control value, even if no type is specified for the node. Control edges may be used with the object node having control type.
Package CompleteActivities An object node may not contain more tokens than its upper bound. The upper bound must be a LiteralUnlimitedNatural. An upper bound of * means the upper bound is unlimited. See ObjectFlow for additional rules regarding when objects may traverse the edges incoming and outgoing from an object node.The ordering of an object node specifies the order in which tokens in the node are offered to the outgoing edges. This can be set to require that tokens do not overtake each other as they pass through the node (FIFO), or that they do (LIFO or modeler-defined ordering). Modeler-defined ordering is indicated by an ordering value of ordered, and a selection behavior that determines what token to offer to the edges. The selection behavior takes all the tokens in the object node as input and chooses a single token from those. It is executed whenever a token is to be offered to an edge. Because the behavior is used while offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. The selection behavior of an object node is overridden by any selection behaviors on its outgoing edges (see “ObjectFlow”). Overtaking due to ordering is distinguished from the case where each invocation of the activity is handled by a separate execution of the activity. In this case, the tokens have no interaction with each other, because they flow through separate executions of the activity (see “Activity”).
Description An activity may have more than one initial node.
Semantics An initial node is a starting point for executing an activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). A control token is placed at the initial node when the activity starts, but not in initial nodes in structured nodes contained by the activity. Tokens in an initial node are offered to all outgoing edges. If an activity has more than one initial node, then invoking the activity starts multiple flows, one at each initial node. For convenience, initial nodes are an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream, for example, by guards (see Activity). This is equivalent to interposing a CentralBufferNode between the initial node and its outgoing edges. Note that flows can also start at other nodes, see ActivityParameterNode and AcceptEventAction, so initial nodes are not required for an activity to start execution. In addition, when an activity starts, a control token is placed at each action or structured node that has no incoming edges, except if it is a handler body (see “ExceptionHandler (from ExtraStructuredActivities)” on page 373, it is the fromAction of an action input pin (see “ActionInputPin (as specialized)” on page 323), or it is contained in a structured node.
Description A join node has multiple incoming edges and one outgoing edge.
Package CompleteActivities Join nodes have a Boolean value specification using the names of the incoming edges to specify the conditions under which the join will emit a token.
Semantics If there is a token offered on all incoming edges, then tokens are offered on the outgoing edge according to the following join rules:
1. If all the tokens offered on the incoming edges are control tokens, then one control token is offered on the outgoing edge.
2. If some of the tokens offered on the incoming edges are control tokens and others are data tokens, then only the data tokens are offered on the outgoing edge. Tokens are offered on the outgoing edge in the same order they were offered to the join.
Multiple control tokens offered on the same incoming edge are combined into one before applying the above rules. No joining of tokens is necessary if there is only one incoming edge, but it is not a useful case.
Package CompleteActivities The reserved string “and” used as a join specification is equivalent to a specification that requires at least one token offered on each incoming edge. It is the default. The join specification is evaluated whenever a new token is offered on any incoming edge. The evaluation is not interrupted by any new tokens offered during the evaluation, nor are concurrent evaluations started when new tokens are offered during an evaluation. If any tokens are offered to the outgoing edge, they must be accepted or rejected for traversal before any more tokens are offered to the outgoing edge. If tokens are rejected for traversal, they are no longer offered to the outgoing edge. The join specification may contain the names of the incoming edges to refer to whether a token was offered on that edge at the time the evaluation started. If isCombinedDuplicate is true, then before object tokens are offered to the outgoing edge, those containing objects with the same identity are combined into one token.
A merge node is a control node that brings together multiple alternate flows. It is not used to synchronize concurrent flows but to accept one among several alternate flows.
Description A merge node has multiple incoming edges and a single outgoing edge.
Semantics All tokens offered on incoming edges are offered to the outgoing edge. There is no synchronization of flows or joining of tokens.
Description A fork node has one incoming edge and multiple outgoing edges.
Semantics Tokens that arrive at a fork node are duplicated across the outgoing edges of the node. Specifically, tokens offered to a fork node are offered to all outgoing edges of the node. If at least one of these offers is accepted, the offered tokens are removed from their source and a copy of the tokens traverse each edge for which the offer was accepted.
Any offer that was not accepted on an outgoing edge due to the failure of the target to accept it remains pending on that edge and may be accepted by the target at a later time. These edges effectively accept a separate copy of the offered tokens, and offers made to the edges stand to their targets in the order in which they were accepted by the edge (first in, first out). This is an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream (see “Activity (from BasicActivities, CompleteActivities, FundamentalActivities, StructuredActivities)” on page 324). Note that any outgoing edges that fail to accept an offer due to the failure of a guard do not receive copies of those tokens. If guards are used on edges outgoing from forks, the modelers should ensure that no downstream joins depend on the arrival of tokens passing through the guarded edge. If that cannot be avoided, then a decision node should be introduced to have the guard, and shunt the token to the downstream join if the guard fails. See example in Figure 12.44 on page 338.
A final node is an abstract control node at which a flow in an activity stops.
Description See descriptions at children of final node.
Semantics All tokens offered on incoming edges are accepted. See children of final node for other semantics.
A decision node is a control node that chooses between outgoing flows.
Description A decision node accepts tokens on an incoming edge and presents them to multiple outgoing edges. Which of the edges is actually traversed depends on the evaluation of the guards on the outgoing edges.
Semantics Each token arriving at a decision node can traverse only one outgoing edge. Tokens are not duplicated. Each token offered by the incoming edge is offered to the outgoing edges. Most commonly, guards of the outgoing edges are evaluated to determine which edge should be traversed. The order in which guards are evaluated is not defined, because edges in general are not required to determine which tokens they accept in any particular order. The modeler should arrange that each token only be chosen to traverse one outgoing edge; otherwise, there will be race conditions among the outgoing edges. If the implementation can ensure that only one guard will succeed, it is not required to evaluate all guards when one is found that does. For decision points, a predefined guard “else” may be defined for at most one outgoing edge. This guard succeeds for a token only if the token is not accepted by all the other edges outgoing from the decision point. Notice that the semantics only requires that the token traverse one edge, rather than be offered to only one edge. Multiple edges may be offered the token, but if only one of them has a target that accepts the token, then that edge is traversed. If multiple edges accept the token and have approval from their targets for traversal at the same time, then the semantics is not defined. If a decision input behavior is specified, then each data token is passed to the behavior before guards are evaluated on the outgoing edges. The behavior is invoked without input for control tokens. The output of the behavior is available to the guard. Because the behavior is used during the process of offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. It may not modify objects, but it may for example, navigate from one object to another or get an attribute value from an object. If there is a decision input flow, but no decision input behavior, then it is the tokens offered on the decision input flow that are made available to the guard on each outgoing edge to determine whether the offer on the regular incoming edge is passed along that outgoing edge. If there is a decision input behavior and a decision input flow, the token offered on the decision input flow is passed to the behavior (as the only argument if the regular incoming edge is control flow, as the second argument if it is an object flow). Decision nodes with the additional decision input flow offer tokens to outgoing edges only when one token is offered on each incoming edge.
Description Activity parameter nodes are object nodes at the beginning and end of flows that provide a means to accept inputs to an activity and provide outputs from the activity, through the activity parameters. Activity parameters inherit support for streaming and exceptions from Parameter.
Constraints
[1] Activity parameter nodes must have parameters from the containing activity.
[2] The type of an activity parameter node is the same as the type of its parameter.
[3] An activity parameter node may have either all incoming edges or all outgoing edges, but it must not have both incoming and outgoing edges.
[4] Activity parameter object nodes with no incoming edges and one or more outgoing edges must have a parameter with in or inout direction.
[5] Activity parameter object nodes with no outgoing edges and one or more incoming edges must have a parameter with out, inout, or return direction.
[6] A parameter with direction other than inout must have at most one activity parameter node in an activity.
[7] A parameter with direction inout must have at most two activity parameter nodes in an activity, one with incoming flows and one with outgoing flows.
See “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319.
Semantics As a kind of behavior, an activity may have owned parameters. Within the activity, in and inout parameters may be associated with activity parameter nodes that have no incoming edges—they provide a source within the activity for the overall “input values” of the activity. Similarly, inout, out, and return parameters may be associated with activity nodes that have no outgoing edges—they provide a sink within the activity for the overall “output values” of the activity.
Per the general semantics of a behavior, when the activity is invoked, its in and inout parameters may be given actual values. These input values are placed as tokens on those activity parameter nodes within the activity that are associated with the corresponding in and inout parameters, the ones which do not have incoming edges. The overall activity input values are then available within the activity via the outgoing edges of the activity parameter nodes. During the course of execution of the activity, tokens may flow into those activity parameter nodes within the activity that have incoming edges. When the execution of the activity completes, the output values held by these activity parameter nodes are given to the corresponding inout, out, and return parameters of the activity. If the parameter associated with an activity parameter node is marked as streaming, then the above semantics are extended to allow for inputs to arrive and outputs to be posted during the execution of the activity (see the semantics for Parameter). In this case, for an activity parameter node with no incoming edges, an input value is placed on the activity parameter node whenever an input arrives on the corresponding streaming in or inout parameter. For an activity parameter node with no outgoing edges, an output value is posted on the corresponding inout, out or return parameter whenever a token arrives at the activity parameter node.
A central buffer node is an object node for managing flows from multiple sources and destinations.
Description A central buffer node accepts tokens from upstream object nodes and passes them along to downstream object nodes. They act as a buffer for multiple in flows and out flows from other object nodes. They do not connect directly to actions.
Semantics See semantics at ObjectNode. All object nodes have buffer functionality, but central buffers differ in that they are not tied to an action as pins are, or to an activity as activity parameter nodes are. See example below.
Description An expansion node is an object node used to indicate a flow across the boundary of an expansion region. A flow into a region contains a collection that is broken into its individual elements inside the region, which is executed once per element. A flow out of a region combines individual elements into a collection for use outside the region.
Semantics See “ExpansionRegion (from ExtraStructuredActivities).”
Description A pin is a typed element and multiplicity element that provides values to actions and accepts result values from them.
Semantics
A pin represents an input to an action or an output from an action. The definition on an action assumes that pins are ordered. Pin multiplicity controls action execution, not the number of tokens in the pin (see upperBound on “ObjectNode (from BasicActivities, CompleteActivities)” on page 405). See “InputPin (from BasicActions)” and “OutputPin (from BasicActions)” for semantics of multiplicity. Pin multiplicity is not unique, because multiple tokens with the same value can reside in an object node.
An activity final node is a final node that stops all flows in an activity.
Description An activity may have more than one activity final node. The first one reached stops all flows in the activity.
Semantics A token reaching an activity final node terminates the activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). In particular, it stops all executing actions in the activity, and destroys all tokens in object nodes, except in the output activity parameter nodes. Terminating the execution of synchronous invocation actions also terminates whatever behaviors they are waiting on for return. Any behaviors invoked asynchronously by the activity are not affected. All tokens offered on the incoming edges are accepted. The content of output activity parameter nodes are passed out of the containing activity, using the null token for object nodes that have nothing in them. If there is more than one final node in an activity, the first one reached terminates the activity, including the flow going towards the other activity final.
If it is not desired to abort all flows in the activity, use flow final instead. For example, if the same execution of an activity is being used for all its invocations, then multiple streams of tokens will be flowing through the same activity. In this case, it is probably not desired to abort all tokens just because one reaches an activity final. Using a flow final will simply consume the tokens reaching it without aborting other flows. Or arrange for separate invocations of the activity to use separate executions of the activity, so tokens from separate invocations will not affect each other.
A flow final node is a final node that terminates a flow.
Description A flow final destroys all tokens that arrive at it. It has no effect on other flows in the activity.
Semantics Flow final destroys tokens flowing into it.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
Description An expansion node is an object node used to indicate a flow across the boundary of an expansion region. A flow into a region contains a collection that is broken into its individual elements inside the region, which is executed once per element. A flow out of a region combines individual elements into a collection for use outside the region.
Semantics See “ExpansionRegion (from ExtraStructuredActivities).”
An expansion region is a structured activity region that executes multiple times corresponding to elements of an input collection.
Description An expansion region is a strictly nested region of an activity with explicit input and outputs (modeled as ExpansionNodes). Each input is a collection of values. If there are multiple inputs, each of them must hold the same kind of collection, although the types of the elements in the different collections may vary. The expansion region is executed once for each element (or position) in the input collection. The number of output collections can differ from the number of input collections. On each execution of the region, an output value from the region is inserted into an output collection at the same position as the input elements. If the region execution ends with no output, then nothing is added to the output collection. When this happens the output collection will not have the same number of elements as the input collections, the region acts as a filter. If all the executions provide an output to the collection, then the output collections will have the same number of elements as the input collections. The inputs and outputs to an expansion region are modeled as ExpansionNodes. From “outside” of the region, the values on these nodes appear as collections. From “inside” the region the values appear as elements of the collections. Object flow edges connect pins outside the region to input and output expansion nodes as collections. Object flow edges connect pins inside the region to input and output expansion nodes as individual elements. From the inside of the region, these nodes are visible as individual values. If an expansion node has a name, it is the name of the individual element within the region. Any object flow edges that cross the boundary of the region, without passing through expansion nodes, provide values that are fixed within the different executions of the region Input pins, introduced by merge with CompleteStructuredActivities, provide values that are also constant during the execution of the region.
Semantics When an execution of an activity makes a token available to the input of an expansion region, the expansion region consumes the token and begins execution. The expansion region is executed once for each element in the collection. If there are multiple inputs, a value is taken from each for each execution of the internals of the region. The mode attribute controls how the executions proceed: • If the value is parallel, the execution may happen in parallel, or overlapping in time, but they are not required to.
• If the value is iterative, the executions of the region must happen in sequence, with one finishing before another can begin. The first iteration begins immediately. Subsequent iterations start when the previous iteration is completed. During each of these cases, one element of the collection is made available to the execution of the region as a token during each execution of the region. If the collection is ordered, the elements will be presented to the region in order; if the collection is unordered, the order of presenting elements is undefined and not necessarily repeatable. On each execution of the region, an output value from the region is inserted into an output collection at the same position as the input elements.
• If the value is stream, there is a single execution of the region, but its input place receives a stream of elements from the collection. The values in the input collection are extracted and placed into the execution of the expansion region as a stream in order, if the collection is ordered. Such a region must handle streams properly or it is ill defined. When the execution of the entire stream is complete, any output streams are assembled into collections of the same kinds as the inputs.
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
Description A control node is an activity node used to coordinate the flows between other nodes. It covers initial node, final node and its children, fork node, join node, decision node, and merge node.
Semantics See semantics at Activity. See subclasses for the semantics of each kind of control node.
Description An object node is an activity node that indicates an instance of a particular classifier, possibly in a particular state, may be available at a particular point in the activity. Object nodes can be used in a variety of ways, depending on where objects are flowing from and to, as described in the semantics sub clause.
Package CompleteActivities Complete object nodes add support for token selection, limitation on the number of tokens, specifying the state required for tokens, and carrying control values.
Constraints Package BasicActivities
[1] All edges coming into or going out of object nodes must be object flow edges.
Package CompleteActivities
[1] If an object node has a selection behavior, then the ordering of the object node is ordered and vice versa.
[2] A selection behavior has one input parameter and one output parameter. The input parameter must be a bag of elements of the same type as the object node or a supertype of the type of object node. The output parameter must be the same or a subtype of the type of object node. The behavior cannot have side effects.
Semantics Object nodes may only contain values at runtime that conform to the type of the object node, in the state or states specified, if any. If no type is specified, then the values may be of any type. Multiple tokens containing the same value may reside in the object node at the same time. This includes data values. A token in an object node can traverse only one of the outgoing edges. An object node may indicate that its type is to be treated as a control value, even if no type is specified for the node. Control edges may be used with the object node having control type.
Package CompleteActivities An object node may not contain more tokens than its upper bound. The upper bound must be a LiteralUnlimitedNatural. An upper bound of * means the upper bound is unlimited. See ObjectFlow for additional rules regarding when objects may traverse the edges incoming and outgoing from an object node.The ordering of an object node specifies the order in which tokens in the node are offered to the outgoing edges. This can be set to require that tokens do not overtake each other as they pass through the node (FIFO), or that they do (LIFO or modeler-defined ordering). Modeler-defined ordering is indicated by an ordering value of ordered, and a selection behavior that determines what token to offer to the edges. The selection behavior takes all the tokens in the object node as input and chooses a single token from those. It is executed whenever a token is to be offered to an edge. Because the behavior is used while offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. The selection behavior of an object node is overridden by any selection behaviors on its outgoing edges (see “ObjectFlow”). Overtaking due to ordering is distinguished from the case where each invocation of the activity is handled by a separate execution of the activity. In this case, the tokens have no interaction with each other, because they flow through separate executions of the activity (see “Activity”).
Description An activity may have more than one initial node.
Semantics An initial node is a starting point for executing an activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). A control token is placed at the initial node when the activity starts, but not in initial nodes in structured nodes contained by the activity. Tokens in an initial node are offered to all outgoing edges. If an activity has more than one initial node, then invoking the activity starts multiple flows, one at each initial node. For convenience, initial nodes are an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream, for example, by guards (see Activity). This is equivalent to interposing a CentralBufferNode between the initial node and its outgoing edges. Note that flows can also start at other nodes, see ActivityParameterNode and AcceptEventAction, so initial nodes are not required for an activity to start execution. In addition, when an activity starts, a control token is placed at each action or structured node that has no incoming edges, except if it is a handler body (see “ExceptionHandler (from ExtraStructuredActivities)” on page 373, it is the fromAction of an action input pin (see “ActionInputPin (as specialized)” on page 323), or it is contained in a structured node.
Description A join node has multiple incoming edges and one outgoing edge.
Package CompleteActivities Join nodes have a Boolean value specification using the names of the incoming edges to specify the conditions under which the join will emit a token.
Semantics If there is a token offered on all incoming edges, then tokens are offered on the outgoing edge according to the following join rules:
1. If all the tokens offered on the incoming edges are control tokens, then one control token is offered on the outgoing edge.
2. If some of the tokens offered on the incoming edges are control tokens and others are data tokens, then only the data tokens are offered on the outgoing edge. Tokens are offered on the outgoing edge in the same order they were offered to the join.
Multiple control tokens offered on the same incoming edge are combined into one before applying the above rules. No joining of tokens is necessary if there is only one incoming edge, but it is not a useful case.
Package CompleteActivities The reserved string “and” used as a join specification is equivalent to a specification that requires at least one token offered on each incoming edge. It is the default. The join specification is evaluated whenever a new token is offered on any incoming edge. The evaluation is not interrupted by any new tokens offered during the evaluation, nor are concurrent evaluations started when new tokens are offered during an evaluation. If any tokens are offered to the outgoing edge, they must be accepted or rejected for traversal before any more tokens are offered to the outgoing edge. If tokens are rejected for traversal, they are no longer offered to the outgoing edge. The join specification may contain the names of the incoming edges to refer to whether a token was offered on that edge at the time the evaluation started. If isCombinedDuplicate is true, then before object tokens are offered to the outgoing edge, those containing objects with the same identity are combined into one token.
A merge node is a control node that brings together multiple alternate flows. It is not used to synchronize concurrent flows but to accept one among several alternate flows.
Description A merge node has multiple incoming edges and a single outgoing edge.
Semantics All tokens offered on incoming edges are offered to the outgoing edge. There is no synchronization of flows or joining of tokens.
Description A fork node has one incoming edge and multiple outgoing edges.
Semantics Tokens that arrive at a fork node are duplicated across the outgoing edges of the node. Specifically, tokens offered to a fork node are offered to all outgoing edges of the node. If at least one of these offers is accepted, the offered tokens are removed from their source and a copy of the tokens traverse each edge for which the offer was accepted.
Any offer that was not accepted on an outgoing edge due to the failure of the target to accept it remains pending on that edge and may be accepted by the target at a later time. These edges effectively accept a separate copy of the offered tokens, and offers made to the edges stand to their targets in the order in which they were accepted by the edge (first in, first out). This is an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream (see “Activity (from BasicActivities, CompleteActivities, FundamentalActivities, StructuredActivities)” on page 324). Note that any outgoing edges that fail to accept an offer due to the failure of a guard do not receive copies of those tokens. If guards are used on edges outgoing from forks, the modelers should ensure that no downstream joins depend on the arrival of tokens passing through the guarded edge. If that cannot be avoided, then a decision node should be introduced to have the guard, and shunt the token to the downstream join if the guard fails. See example in Figure 12.44 on page 338.
A final node is an abstract control node at which a flow in an activity stops.
Description See descriptions at children of final node.
Semantics All tokens offered on incoming edges are accepted. See children of final node for other semantics.
A decision node is a control node that chooses between outgoing flows.
Description A decision node accepts tokens on an incoming edge and presents them to multiple outgoing edges. Which of the edges is actually traversed depends on the evaluation of the guards on the outgoing edges.
Semantics Each token arriving at a decision node can traverse only one outgoing edge. Tokens are not duplicated. Each token offered by the incoming edge is offered to the outgoing edges. Most commonly, guards of the outgoing edges are evaluated to determine which edge should be traversed. The order in which guards are evaluated is not defined, because edges in general are not required to determine which tokens they accept in any particular order. The modeler should arrange that each token only be chosen to traverse one outgoing edge; otherwise, there will be race conditions among the outgoing edges. If the implementation can ensure that only one guard will succeed, it is not required to evaluate all guards when one is found that does. For decision points, a predefined guard “else” may be defined for at most one outgoing edge. This guard succeeds for a token only if the token is not accepted by all the other edges outgoing from the decision point. Notice that the semantics only requires that the token traverse one edge, rather than be offered to only one edge. Multiple edges may be offered the token, but if only one of them has a target that accepts the token, then that edge is traversed. If multiple edges accept the token and have approval from their targets for traversal at the same time, then the semantics is not defined. If a decision input behavior is specified, then each data token is passed to the behavior before guards are evaluated on the outgoing edges. The behavior is invoked without input for control tokens. The output of the behavior is available to the guard. Because the behavior is used during the process of offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. It may not modify objects, but it may for example, navigate from one object to another or get an attribute value from an object. If there is a decision input flow, but no decision input behavior, then it is the tokens offered on the decision input flow that are made available to the guard on each outgoing edge to determine whether the offer on the regular incoming edge is passed along that outgoing edge. If there is a decision input behavior and a decision input flow, the token offered on the decision input flow is passed to the behavior (as the only argument if the regular incoming edge is control flow, as the second argument if it is an object flow). Decision nodes with the additional decision input flow offer tokens to outgoing edges only when one token is offered on each incoming edge.
Description Activity parameter nodes are object nodes at the beginning and end of flows that provide a means to accept inputs to an activity and provide outputs from the activity, through the activity parameters. Activity parameters inherit support for streaming and exceptions from Parameter.
Constraints
[1] Activity parameter nodes must have parameters from the containing activity.
[2] The type of an activity parameter node is the same as the type of its parameter.
[3] An activity parameter node may have either all incoming edges or all outgoing edges, but it must not have both incoming and outgoing edges.
[4] Activity parameter object nodes with no incoming edges and one or more outgoing edges must have a parameter with in or inout direction.
[5] Activity parameter object nodes with no outgoing edges and one or more incoming edges must have a parameter with out, inout, or return direction.
[6] A parameter with direction other than inout must have at most one activity parameter node in an activity.
[7] A parameter with direction inout must have at most two activity parameter nodes in an activity, one with incoming flows and one with outgoing flows.
See “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319.
Semantics As a kind of behavior, an activity may have owned parameters. Within the activity, in and inout parameters may be associated with activity parameter nodes that have no incoming edges—they provide a source within the activity for the overall “input values” of the activity. Similarly, inout, out, and return parameters may be associated with activity nodes that have no outgoing edges—they provide a sink within the activity for the overall “output values” of the activity.
Per the general semantics of a behavior, when the activity is invoked, its in and inout parameters may be given actual values. These input values are placed as tokens on those activity parameter nodes within the activity that are associated with the corresponding in and inout parameters, the ones which do not have incoming edges. The overall activity input values are then available within the activity via the outgoing edges of the activity parameter nodes. During the course of execution of the activity, tokens may flow into those activity parameter nodes within the activity that have incoming edges. When the execution of the activity completes, the output values held by these activity parameter nodes are given to the corresponding inout, out, and return parameters of the activity. If the parameter associated with an activity parameter node is marked as streaming, then the above semantics are extended to allow for inputs to arrive and outputs to be posted during the execution of the activity (see the semantics for Parameter). In this case, for an activity parameter node with no incoming edges, an input value is placed on the activity parameter node whenever an input arrives on the corresponding streaming in or inout parameter. For an activity parameter node with no outgoing edges, an output value is posted on the corresponding inout, out or return parameter whenever a token arrives at the activity parameter node.
A central buffer node is an object node for managing flows from multiple sources and destinations.
Description A central buffer node accepts tokens from upstream object nodes and passes them along to downstream object nodes. They act as a buffer for multiple in flows and out flows from other object nodes. They do not connect directly to actions.
Semantics See semantics at ObjectNode. All object nodes have buffer functionality, but central buffers differ in that they are not tied to an action as pins are, or to an activity as activity parameter nodes are. See example below.
Description An expansion node is an object node used to indicate a flow across the boundary of an expansion region. A flow into a region contains a collection that is broken into its individual elements inside the region, which is executed once per element. A flow out of a region combines individual elements into a collection for use outside the region.
Semantics See “ExpansionRegion (from ExtraStructuredActivities).”
Description A pin is a typed element and multiplicity element that provides values to actions and accepts result values from them.
Semantics
A pin represents an input to an action or an output from an action. The definition on an action assumes that pins are ordered. Pin multiplicity controls action execution, not the number of tokens in the pin (see upperBound on “ObjectNode (from BasicActivities, CompleteActivities)” on page 405). See “InputPin (from BasicActions)” and “OutputPin (from BasicActions)” for semantics of multiplicity. Pin multiplicity is not unique, because multiple tokens with the same value can reside in an object node.
An activity final node is a final node that stops all flows in an activity.
Description An activity may have more than one activity final node. The first one reached stops all flows in the activity.
Semantics A token reaching an activity final node terminates the activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). In particular, it stops all executing actions in the activity, and destroys all tokens in object nodes, except in the output activity parameter nodes. Terminating the execution of synchronous invocation actions also terminates whatever behaviors they are waiting on for return. Any behaviors invoked asynchronously by the activity are not affected. All tokens offered on the incoming edges are accepted. The content of output activity parameter nodes are passed out of the containing activity, using the null token for object nodes that have nothing in them. If there is more than one final node in an activity, the first one reached terminates the activity, including the flow going towards the other activity final.
If it is not desired to abort all flows in the activity, use flow final instead. For example, if the same execution of an activity is being used for all its invocations, then multiple streams of tokens will be flowing through the same activity. In this case, it is probably not desired to abort all tokens just because one reaches an activity final. Using a flow final will simply consume the tokens reaching it without aborting other flows. Or arrange for separate invocations of the activity to use separate executions of the activity, so tokens from separate invocations will not affect each other.
A flow final node is a final node that terminates a flow.
Description A flow final destroys all tokens that arrive at it. It has no effect on other flows in the activity.
Semantics Flow final destroys tokens flowing into it.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
An interruptible activity region is an activity group that supports termination of tokens flowing in the portions of an activity.
An interruptible region contains activity nodes. When a token leaves an interruptible region via edges designated by the region as interrupting edges, all tokens and behaviors in the region are terminated.
The region is interrupted, including accept event actions in the region, when a token traverses an interrupting edge. At this point the interrupting token has left the region and is not terminated. AcceptEventActions in the region that do not have incoming edges are enabled only when a token enters the region, even if the token is not directed at the accept event action.
Token transfer is still atomic, even when using interrupting regions. If a non-interrupting edge is passing a token from a source node in the region to target node outside the region, then the transfer is completed and the token arrives at the target even if an interruption occurs during the traversal. In other words, a token transition is never partial; it is either complete or it does not happen at all.
Do not use an interrupting region if it is not desired to abort all flows in the region in some cases. For example, if the same execution of an activity is being used for all its invocations, then multiple streams of tokens will be flowing through the same activity. In this case, it is probably not desired to abort all tokens just because one leaves the region. Arrange for separate invocations of the activity to use separate executions of the activity when employing interruptible regions, so tokens from each invocation will not affect each other.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
Description A pin is a typed element and multiplicity element that provides values to actions and accepts result values from them.
Semantics
A pin represents an input to an action or an output from an action. The definition on an action assumes that pins are ordered. Pin multiplicity controls action execution, not the number of tokens in the pin (see upperBound on “ObjectNode (from BasicActivities, CompleteActivities)” on page 405). See “InputPin (from BasicActions)” and “OutputPin (from BasicActions)” for semantics of multiplicity. Pin multiplicity is not unique, because multiple tokens with the same value can reside in an object node.
A data store keeps all tokens that enter it, copying them when they are chosen to move downstream. Incoming tokens containing a particular object replace any tokens in the object node containing that object.
Description A join node has multiple incoming edges and one outgoing edge.
Package CompleteActivities Join nodes have a Boolean value specification using the names of the incoming edges to specify the conditions under which the join will emit a token.
Semantics If there is a token offered on all incoming edges, then tokens are offered on the outgoing edge according to the following join rules:
1. If all the tokens offered on the incoming edges are control tokens, then one control token is offered on the outgoing edge.
2. If some of the tokens offered on the incoming edges are control tokens and others are data tokens, then only the data tokens are offered on the outgoing edge. Tokens are offered on the outgoing edge in the same order they were offered to the join.
Multiple control tokens offered on the same incoming edge are combined into one before applying the above rules. No joining of tokens is necessary if there is only one incoming edge, but it is not a useful case.
Package CompleteActivities The reserved string “and” used as a join specification is equivalent to a specification that requires at least one token offered on each incoming edge. It is the default. The join specification is evaluated whenever a new token is offered on any incoming edge. The evaluation is not interrupted by any new tokens offered during the evaluation, nor are concurrent evaluations started when new tokens are offered during an evaluation. If any tokens are offered to the outgoing edge, they must be accepted or rejected for traversal before any more tokens are offered to the outgoing edge. If tokens are rejected for traversal, they are no longer offered to the outgoing edge. The join specification may contain the names of the incoming edges to refer to whether a token was offered on that edge at the time the evaluation started. If isCombinedDuplicate is true, then before object tokens are offered to the outgoing edge, those containing objects with the same identity are combined into one token.
Description An object node is an activity node that indicates an instance of a particular classifier, possibly in a particular state, may be available at a particular point in the activity. Object nodes can be used in a variety of ways, depending on where objects are flowing from and to, as described in the semantics sub clause.
Package CompleteActivities Complete object nodes add support for token selection, limitation on the number of tokens, specifying the state required for tokens, and carrying control values.
Constraints Package BasicActivities
[1] All edges coming into or going out of object nodes must be object flow edges.
Package CompleteActivities
[1] If an object node has a selection behavior, then the ordering of the object node is ordered and vice versa.
[2] A selection behavior has one input parameter and one output parameter. The input parameter must be a bag of elements of the same type as the object node or a supertype of the type of object node. The output parameter must be the same or a subtype of the type of object node. The behavior cannot have side effects.
Semantics Object nodes may only contain values at runtime that conform to the type of the object node, in the state or states specified, if any. If no type is specified, then the values may be of any type. Multiple tokens containing the same value may reside in the object node at the same time. This includes data values. A token in an object node can traverse only one of the outgoing edges. An object node may indicate that its type is to be treated as a control value, even if no type is specified for the node. Control edges may be used with the object node having control type.
Package CompleteActivities An object node may not contain more tokens than its upper bound. The upper bound must be a LiteralUnlimitedNatural. An upper bound of * means the upper bound is unlimited. See ObjectFlow for additional rules regarding when objects may traverse the edges incoming and outgoing from an object node.The ordering of an object node specifies the order in which tokens in the node are offered to the outgoing edges. This can be set to require that tokens do not overtake each other as they pass through the node (FIFO), or that they do (LIFO or modeler-defined ordering). Modeler-defined ordering is indicated by an ordering value of ordered, and a selection behavior that determines what token to offer to the edges. The selection behavior takes all the tokens in the object node as input and chooses a single token from those. It is executed whenever a token is to be offered to an edge. Because the behavior is used while offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. The selection behavior of an object node is overridden by any selection behaviors on its outgoing edges (see “ObjectFlow”). Overtaking due to ordering is distinguished from the case where each invocation of the activity is handled by a separate execution of the activity. In this case, the tokens have no interaction with each other, because they flow through separate executions of the activity (see “Activity”).
Description A parameter is a specification of an argument used to pass information into or out of an invocation of a behavioral feature. It has a type, and may have a multiplicity and an optional default value.
Semantics A parameter specifies how arguments are passed into or out of an invocation of a behavioral feature like an operation. The type and multiplicity of a parameter restrict what values can be passed, how many, and whether the values are ordered. If a default is specified for a parameter, then it is evaluated at invocation time and used as the argument for this parameter if and only if no argument is supplied at invocation of the behavioral feature. A parameter may be given a name, which then identifies the parameter uniquely within the parameters of the same behavioral feature. If it is unnamed, it is distinguished only by its position in the ordered list of parameters. The parameter direction specifies whether its value is passed into, out of, or both into and out of the owning behavioral feature. A single parameter may be distinguished as a return parameter. If the behavioral feature is an operation, then the type and multiplicity of this parameter is the same as the type and multiplicity of the operation itself.
A feature declares a behavioral or structural characteristic of instances of classifiers. Feature is an abstract metaclass.
Semantics A feature represents some characteristic for its featuring classifiers; this characteristic may be of the classifier’s instances considered individually (not static), or of the classifier itself (static). A Feature can be a feature of multiple classifiers. The same feature cannot be static in one context but not another.
Semantic Variation Points With regard to static features, two alternative semantics are recognized. A static feature may have different values for different featuring classifiers, or the same value for all featuring classifiers. In accord with this semantic variation point, inheritance of values for static features is permitted but not required by UML 2. Such inheritance is encouraged when modeling systems will be coded in languages, such as C++, Java, and C#, which stipulate inheritance of values for static features.
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
Description An object node is an activity node that indicates an instance of a particular classifier, possibly in a particular state, may be available at a particular point in the activity. Object nodes can be used in a variety of ways, depending on where objects are flowing from and to, as described in the semantics sub clause.
Package CompleteActivities Complete object nodes add support for token selection, limitation on the number of tokens, specifying the state required for tokens, and carrying control values.
Constraints Package BasicActivities
[1] All edges coming into or going out of object nodes must be object flow edges.
Package CompleteActivities
[1] If an object node has a selection behavior, then the ordering of the object node is ordered and vice versa.
[2] A selection behavior has one input parameter and one output parameter. The input parameter must be a bag of elements of the same type as the object node or a supertype of the type of object node. The output parameter must be the same or a subtype of the type of object node. The behavior cannot have side effects.
Semantics Object nodes may only contain values at runtime that conform to the type of the object node, in the state or states specified, if any. If no type is specified, then the values may be of any type. Multiple tokens containing the same value may reside in the object node at the same time. This includes data values. A token in an object node can traverse only one of the outgoing edges. An object node may indicate that its type is to be treated as a control value, even if no type is specified for the node. Control edges may be used with the object node having control type.
Package CompleteActivities An object node may not contain more tokens than its upper bound. The upper bound must be a LiteralUnlimitedNatural. An upper bound of * means the upper bound is unlimited. See ObjectFlow for additional rules regarding when objects may traverse the edges incoming and outgoing from an object node.The ordering of an object node specifies the order in which tokens in the node are offered to the outgoing edges. This can be set to require that tokens do not overtake each other as they pass through the node (FIFO), or that they do (LIFO or modeler-defined ordering). Modeler-defined ordering is indicated by an ordering value of ordered, and a selection behavior that determines what token to offer to the edges. The selection behavior takes all the tokens in the object node as input and chooses a single token from those. It is executed whenever a token is to be offered to an edge. Because the behavior is used while offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. The selection behavior of an object node is overridden by any selection behaviors on its outgoing edges (see “ObjectFlow”). Overtaking due to ordering is distinguished from the case where each invocation of the activity is handled by a separate execution of the activity. In this case, the tokens have no interaction with each other, because they flow through separate executions of the activity (see “Activity”).
Description Activity parameter nodes are object nodes at the beginning and end of flows that provide a means to accept inputs to an activity and provide outputs from the activity, through the activity parameters. Activity parameters inherit support for streaming and exceptions from Parameter.
Constraints
[1] Activity parameter nodes must have parameters from the containing activity.
[2] The type of an activity parameter node is the same as the type of its parameter.
[3] An activity parameter node may have either all incoming edges or all outgoing edges, but it must not have both incoming and outgoing edges.
[4] Activity parameter object nodes with no incoming edges and one or more outgoing edges must have a parameter with in or inout direction.
[5] Activity parameter object nodes with no outgoing edges and one or more incoming edges must have a parameter with out, inout, or return direction.
[6] A parameter with direction other than inout must have at most one activity parameter node in an activity.
[7] A parameter with direction inout must have at most two activity parameter nodes in an activity, one with incoming flows and one with outgoing flows.
See “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319.
Semantics As a kind of behavior, an activity may have owned parameters. Within the activity, in and inout parameters may be associated with activity parameter nodes that have no incoming edges—they provide a source within the activity for the overall “input values” of the activity. Similarly, inout, out, and return parameters may be associated with activity nodes that have no outgoing edges—they provide a sink within the activity for the overall “output values” of the activity.
Per the general semantics of a behavior, when the activity is invoked, its in and inout parameters may be given actual values. These input values are placed as tokens on those activity parameter nodes within the activity that are associated with the corresponding in and inout parameters, the ones which do not have incoming edges. The overall activity input values are then available within the activity via the outgoing edges of the activity parameter nodes. During the course of execution of the activity, tokens may flow into those activity parameter nodes within the activity that have incoming edges. When the execution of the activity completes, the output values held by these activity parameter nodes are given to the corresponding inout, out, and return parameters of the activity. If the parameter associated with an activity parameter node is marked as streaming, then the above semantics are extended to allow for inputs to arrive and outputs to be posted during the execution of the activity (see the semantics for Parameter). In this case, for an activity parameter node with no incoming edges, an input value is placed on the activity parameter node whenever an input arrives on the corresponding streaming in or inout parameter. For an activity parameter node with no outgoing edges, an output value is posted on the corresponding inout, out or return parameter whenever a token arrives at the activity parameter node.
A central buffer node is an object node for managing flows from multiple sources and destinations.
Description A central buffer node accepts tokens from upstream object nodes and passes them along to downstream object nodes. They act as a buffer for multiple in flows and out flows from other object nodes. They do not connect directly to actions.
Semantics See semantics at ObjectNode. All object nodes have buffer functionality, but central buffers differ in that they are not tied to an action as pins are, or to an activity as activity parameter nodes are. See example below.
Description An expansion node is an object node used to indicate a flow across the boundary of an expansion region. A flow into a region contains a collection that is broken into its individual elements inside the region, which is executed once per element. A flow out of a region combines individual elements into a collection for use outside the region.
Semantics See “ExpansionRegion (from ExtraStructuredActivities).”
Description A pin is a typed element and multiplicity element that provides values to actions and accepts result values from them.
Semantics
A pin represents an input to an action or an output from an action. The definition on an action assumes that pins are ordered. Pin multiplicity controls action execution, not the number of tokens in the pin (see upperBound on “ObjectNode (from BasicActivities, CompleteActivities)” on page 405). See “InputPin (from BasicActions)” and “OutputPin (from BasicActions)” for semantics of multiplicity. Pin multiplicity is not unique, because multiple tokens with the same value can reside in an object node.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::A of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Class
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::roleNameB of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Property
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::attName of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Property
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::B of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Class
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::roleNameA of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Property
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::Association Example of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Package
An Association specifies a semantic relationship that can occur between typed instances. It has at least two memberEnds represented by Properties, each of which has the type of the end. More than one end of the Association may have the same type.
An Association declares that there can be links between instances of the associated types. A link is a tuple with one value for each memberEnd of the Association, where each value is an instance of the type of the end.
Not all links need to be classified by an Association.
When one or more ends of the Association have isUnique=false, it is possible to have several links associating the same set of instances. In such a case, links carry an additional identifier apart from their end values.
When one or more ends of the Association are ordered, links carry ordering information in addition to their end values.
For an Association with N memberEnds, choose any N-1 ends and associate specific instances with those ends. Then the collection of links of the Association that refer to these specific instances will identify a collection of instances at the other end. The multiplicity of the other end constrains the size of this collection. If the other end is marked as isOrdered, this collection will be ordered. If the other end is marked as isUnique, this collection is a set; otherwise, it allows duplicate elements.
Subsetting represents the familiar set-theoretic concept. It applies to the collections represented by Association ends, not to the Association itself. It means that the subsetting Association end represents a collection that is either equal to or a proper subset of the collection that it is subsetting. Subsetting is a relationship in the domain of extensional semantics.
Specialization is, in contrast to subsetting, a relationship in the domain of intentional semantics, which is to say it characterizes the criteria whereby membership in the collection is defined, not by the membership. In the case of Associations, specialization means that a link classified by the specializing association is also classified by the specialized association. Semantically this implies that the collections representing the ends of the specializing association are subsets of the corresponding collections representing the ends of the specialized association; this fact of subsetting may or may not be explicitly declared in a model.
Note – For n-ary Associations, the lower multiplicity of an end is typically 0. A lower multiplicity for an end of an n-ary Association of 1 (or more) implies that one link (or more) must exist for every possible combination of values for the other ends.
A binary Association may represent a composite aggregation (i.e., a whole/part relationship). Composition is represented by the isComposite attribute on the part end of the Association being set to true. See the semantics of composition in 9.5.3.
An end Property of an Association that is owned by an end Class or that is a navigableOwnedEnd of the Association indicates that the Association is navigable from the opposite ends; otherwise, the Association is not navigable from the opposite ends. Navigability means that instances participating in links at runtime (instances of an Association) can be accessed efficiently from instances at the other ends of the Association. The precise mechanism by which such efficient access is achieved is implementation specific. If an end is not navigable, access from the other ends may or may not be possible, and if it is, it might not be efficient. Note that tools operating on UML models are not prevented from navigating Associations from non-navigable ends.
The existence of an association may be derived from other information in the model. The logical relationship between the derivation of an Association and the derivation of its ends is model-specific.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Properties are StructuralFeatures that represent the attributes of Classifiers, the memberEnds of Associations, and the parts of StructuredClassifiers.
Description Property represents a declared state of one or more instances in terms of a named relationship to a value or values. When a property is an attribute of a classifier, the value or values are related to the instance of the classifier by being held in slots of the instance. When a property is an association end, the value or values are related to the instance or instances at the other end(s) of the association (see semantics of Association). Property is indirectly a subclass of Constructs::TypedElement. The range of valid values represented by the property can be controlled by setting the property’s type.
Semantics When a property is owned by a classifier other than an association via ownedAttribute, then it represents an attribute of the class or data type. When related to an association via memberEnd or one of its specializations, it represents an end of the association. In either case, when instantiated a property represents a value or collection of values associated with an instance of one (or in the case of a ternary or higher-order association, more than one) type. This set of classifiers is called the context for the property; in the case of an attribute the context is the owning classifier, and in the case of an association end the context is the set of types at the other end or ends of the association. The value or collection of values instantiated for a property in an instance of its context conforms to the property’s type. Property inherits from MultiplicityElement and thus allows multiplicity bounds to be specified. These bounds constrain the size of the collection. Typically and by default the maximum bound is 1. Property also inherits the isUnique and isOrdered meta-attributes. When isUnique is true (the default) the collection of values may not contain duplicates. When isOrdered is true (false being the default) the collection of values is ordered. In combination these two allow the type of a property to represent a collection in the following way:
If there is a default specified for a property, this default is evaluated when an instance of the property is created in the absence of a specific setting for the property or a constraint in the model that requires the property to have a specific value. The evaluated default then becomes the initial value (or values) of the property. If a property is derived, then its value or values can be computed from other information. Actions involving a derived property behave the same as for a nonderived property. Derived properties are often specified to be read-only (i.e., clients cannot directly change values). But where a derived property is changeable, an implementation is expected to make appropriate changes to the model in order for all the constraints to be met, in particular the derivation constraint for the derived property. The derivation for a derived property may be specified by a constraint. The name and visibility of a property are not required to match those of any property it redefines. A derived property can redefine one which is not derived. An implementation must ensure that the constraints implied by the derivation are maintained if the property is updated. If a property has a specified default, and the property redefines another property with a specified default, then the redefining property’s default is used in place of the more general default from the redefined property. If a navigable property is marked as readOnly, then it cannot be updated once it has been assigned an initial value.
A property may be marked as the subset of another, as long as every element in the context of subsetting property conforms to the corresponding element in the context of the subsetted property. In this case, the collection associated with an instance of the subsetting property must be included in (or the same as) the collection associated with the corresponding instance of the subsetted property. A property may be marked as being a derived union. This means that the collection of values denoted by the property in some context is derived by being the strict union of all of the values denoted, in the same context, by properties defined to subset it. If the property has a multiplicity upper bound of 1, then this means that the values of all the subsets must be null or the same. A property may be owned by and in the namespace of a datatype A property may be marked as being (part of) the identifier (if any) for classes of which it is a member. The interpretation of this is left open but this could be mapped to implementations such as primary keys for relational database tables or ID attributes in XML. If multiple properties are marked (possibly in superclasses), then it is the combination of the (property, value) tuples that will logically provide the uniqueness for any instance. Hence there is no need for any specification of order and it is possible for some (but not all) of the property values to be empty. If the property is multivalued, then all values are included.
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
Description A type constrains the values represented by a typed element.
Semantics A type serves as a constraint on the range of values represented by a typed element. Type is an abstract metaclass.
Description A typed element is an element that has a type that serves as a constraint on the range of values the element can represent. Typed element is an abstract metaclass.
Semantics Values represented by the element are constrained to be instances of the type. A typed element with no associated type may represent values of any type.
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
A Connector specifies links that enables communication between two or more instances. In contrast to Associations, which specify links between any instance of the associated Classifiers, Connectors specify links between instances playing the connected parts only. The connector concept is extended in the Components package to include contracts and notation.
A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling.
An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics
A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts.
Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only).
A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
Description A connector end is an endpoint of a connector, which attaches the connector to a connectable element. Each connector end is part of one connector.
Semantics InternalStructures A connector end describes which connectable element is attached to the connector owning that end. Its multiplicity indicates the number of instances that may be linked to each instance of the property connected on the other end.
Properties are StructuralFeatures that represent the attributes of Classifiers, the memberEnds of Associations, and the parts of StructuredClassifiers.
Description Property represents a declared state of one or more instances in terms of a named relationship to a value or values. When a property is an attribute of a classifier, the value or values are related to the instance of the classifier by being held in slots of the instance. When a property is an association end, the value or values are related to the instance or instances at the other end(s) of the association (see semantics of Association). Property is indirectly a subclass of Constructs::TypedElement. The range of valid values represented by the property can be controlled by setting the property’s type.
Semantics When a property is owned by a classifier other than an association via ownedAttribute, then it represents an attribute of the class or data type. When related to an association via memberEnd or one of its specializations, it represents an end of the association. In either case, when instantiated a property represents a value or collection of values associated with an instance of one (or in the case of a ternary or higher-order association, more than one) type. This set of classifiers is called the context for the property; in the case of an attribute the context is the owning classifier, and in the case of an association end the context is the set of types at the other end or ends of the association. The value or collection of values instantiated for a property in an instance of its context conforms to the property’s type. Property inherits from MultiplicityElement and thus allows multiplicity bounds to be specified. These bounds constrain the size of the collection. Typically and by default the maximum bound is 1. Property also inherits the isUnique and isOrdered meta-attributes. When isUnique is true (the default) the collection of values may not contain duplicates. When isOrdered is true (false being the default) the collection of values is ordered. In combination these two allow the type of a property to represent a collection in the following way:
If there is a default specified for a property, this default is evaluated when an instance of the property is created in the absence of a specific setting for the property or a constraint in the model that requires the property to have a specific value. The evaluated default then becomes the initial value (or values) of the property. If a property is derived, then its value or values can be computed from other information. Actions involving a derived property behave the same as for a nonderived property. Derived properties are often specified to be read-only (i.e., clients cannot directly change values). But where a derived property is changeable, an implementation is expected to make appropriate changes to the model in order for all the constraints to be met, in particular the derivation constraint for the derived property. The derivation for a derived property may be specified by a constraint. The name and visibility of a property are not required to match those of any property it redefines. A derived property can redefine one which is not derived. An implementation must ensure that the constraints implied by the derivation are maintained if the property is updated. If a property has a specified default, and the property redefines another property with a specified default, then the redefining property’s default is used in place of the more general default from the redefined property. If a navigable property is marked as readOnly, then it cannot be updated once it has been assigned an initial value.
A property may be marked as the subset of another, as long as every element in the context of subsetting property conforms to the corresponding element in the context of the subsetted property. In this case, the collection associated with an instance of the subsetting property must be included in (or the same as) the collection associated with the corresponding instance of the subsetted property. A property may be marked as being a derived union. This means that the collection of values denoted by the property in some context is derived by being the strict union of all of the values denoted, in the same context, by properties defined to subset it. If the property has a multiplicity upper bound of 1, then this means that the values of all the subsets must be null or the same. A property may be owned by and in the namespace of a datatype A property may be marked as being (part of) the identifier (if any) for classes of which it is a member. The interpretation of this is left open but this could be mapped to implementations such as primary keys for relational database tables or ID attributes in XML. If multiple properties are marked (possibly in superclasses), then it is the combination of the (property, value) tuples that will logically provide the uniqueness for any instance. Hence there is no need for any specification of order and it is possible for some (but not all) of the property values to be empty. If the property is multivalued, then all values are included.
An Association specifies a semantic relationship that can occur between typed instances. It has at least two memberEnds represented by Properties, each of which has the type of the end. More than one end of the Association may have the same type.
An Association declares that there can be links between instances of the associated types. A link is a tuple with one value for each memberEnd of the Association, where each value is an instance of the type of the end.
Not all links need to be classified by an Association.
When one or more ends of the Association have isUnique=false, it is possible to have several links associating the same set of instances. In such a case, links carry an additional identifier apart from their end values.
When one or more ends of the Association are ordered, links carry ordering information in addition to their end values.
For an Association with N memberEnds, choose any N-1 ends and associate specific instances with those ends. Then the collection of links of the Association that refer to these specific instances will identify a collection of instances at the other end. The multiplicity of the other end constrains the size of this collection. If the other end is marked as isOrdered, this collection will be ordered. If the other end is marked as isUnique, this collection is a set; otherwise, it allows duplicate elements.
Subsetting represents the familiar set-theoretic concept. It applies to the collections represented by Association ends, not to the Association itself. It means that the subsetting Association end represents a collection that is either equal to or a proper subset of the collection that it is subsetting. Subsetting is a relationship in the domain of extensional semantics.
Specialization is, in contrast to subsetting, a relationship in the domain of intentional semantics, which is to say it characterizes the criteria whereby membership in the collection is defined, not by the membership. In the case of Associations, specialization means that a link classified by the specializing association is also classified by the specialized association. Semantically this implies that the collections representing the ends of the specializing association are subsets of the corresponding collections representing the ends of the specialized association; this fact of subsetting may or may not be explicitly declared in a model.
Note – For n-ary Associations, the lower multiplicity of an end is typically 0. A lower multiplicity for an end of an n-ary Association of 1 (or more) implies that one link (or more) must exist for every possible combination of values for the other ends.
A binary Association may represent a composite aggregation (i.e., a whole/part relationship). Composition is represented by the isComposite attribute on the part end of the Association being set to true. See the semantics of composition in 9.5.3.
An end Property of an Association that is owned by an end Class or that is a navigableOwnedEnd of the Association indicates that the Association is navigable from the opposite ends; otherwise, the Association is not navigable from the opposite ends. Navigability means that instances participating in links at runtime (instances of an Association) can be accessed efficiently from instances at the other ends of the Association. The precise mechanism by which such efficient access is achieved is implementation specific. If an end is not navigable, access from the other ends may or may not be possible, and if it is, it might not be efficient. Note that tools operating on UML models are not prevented from navigating Associations from non-navigable ends.
The existence of an association may be derived from other information in the model. The logical relationship between the derivation of an Association and the derivation of its ends is model-specific.
The connector concept is extended in the Components package to include contracts and notation. A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling. An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts. Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only). A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
A port is a property of a classifier that specifies a distinct interaction point between that classifier and its environment or between the (behavior of the) classifier and its internal parts. Ports are connected to properties of the classifier by connectors through which requests can be made to invoke the behavioral features of a classifier. A Port may specify the services a classifier provides (offers) to its environment as well as the services that a classifier expects (requires) of its environment.
Description
Ports represent interaction points between a classifier and its environment. The interfaces associated with a port specify the nature of the interactions that may occur over a port. The required interfaces of a port characterize the requests that may be made from the classifier to its environment through this port. The provided interfaces of a port characterize requests to the classifier that its environment may make through this port. A port has the ability to specify that any requests arriving at this port are handled by the behavior of the instance of the owning classifier, rather than being forwarded to any contained instances, if any.
Semantics
A port represents an interaction point between a classifier instance and its environment or between a classifier instance and instances it may contain. A port by default has public visibility.
The required interfaces characterize services that the owning classifier expects from its environment and that it may access through this interaction point: Instances of this classifier expect that the features owned by its required interfaces will be offered by one or more instances in its environment.
The provided interfaces characterize the behavioral features that the owning classifier offers to its environment at this interaction point. The owning classifier must offer the features owned by the provided interfaces. The provided and required interfaces completely characterize any interaction that may occur between a classifier and its environment at a port with respect to the data communicated at this port and the behaviors that may be invoked through this port. The interfaces do not necessarily establish the exact sequences of interactions across the port. When an instance of a classifier is created, instances corresponding to each of its ports are created and held in the slots specified by the ports, in accordance with its multiplicity. These instances are referred to as “interaction points” and provide unique references. A link from that instance to the instance of the owning classifier is created through which communication is forwarded to the instance of the owning classifier or through which the owning classifier communicates with its environment. It is, therefore, possible for an instance to differentiate between requests for the invocation of a behavioral feature targeted at its different ports. Similarly, it is possible to direct such requests at a port, and the requests will be routed as specified by the links corresponding to connectors attached to this port. (In the following, “requests arriving at a port” shall mean “request occurrences arriving at the interaction point of this instance corresponding to this port.”)
If connectors are attached to both the port when used on a property within the internal structure of a classifier and the port on the container of an internal structure, the instance of the owning classifier will forward any requests arriving at this port along the link specified by those connectors. If there is a connector attached to only one side of a port, any requests arriving at this port will terminate at this port. For a behavior port, the instance of the owning classifier will handle requests arriving at this port, if this classifier has any behavior. If there is no behavior defined for this classifier, any communication arriving at a behavior port is lost.
Semantic Variation Points If several connectors are attached on one side of a port, then any request arriving at this port on a link derived from a connector on the other side of the port will be forwarded on links corresponding to these connectors. It is a semantic variation point whether these requests will be forwarded on all links, or on only one of those links. In the latter case, one possibility is that the link at which this request will be forwarded will be arbitrarily selected among those links leading to an instance that had been specified as being able to handle this request (i.e., this request is specified in a provided interface of the part corresponding to this instance).
An extension end is used to tie an extension to a stereotype when extending a metaclass.
Description ExtensionEnd is a kind of Property that is always typed by a Stereotype. An ExtensionEnd is a navigable ownedEnd, owned by an Extension. This allows a stereotype instance to be attached to an instance of the extended classifier without adding a property to the classifier. The aggregation of an ExtensionEnd is always composite. The default multiplicity of an ExtensionEnd is 0..1.
Semantics No additional semantics
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
Description A parameter is a specification of an argument used to pass information into or out of an invocation of a behavioral feature. It has a type, and may have a multiplicity and an optional default value.
Semantics A parameter specifies how arguments are passed into or out of an invocation of a behavioral feature like an operation. The type and multiplicity of a parameter restrict what values can be passed, how many, and whether the values are ordered. If a default is specified for a parameter, then it is evaluated at invocation time and used as the argument for this parameter if and only if no argument is supplied at invocation of the behavioral feature. A parameter may be given a name, which then identifies the parameter uniquely within the parameters of the same behavioral feature. If it is unnamed, it is distinguished only by its position in the ordered list of parameters. The parameter direction specifies whether its value is passed into, out of, or both into and out of the owning behavioral feature. A single parameter may be distinguished as a return parameter. If the behavioral feature is an operation, then the type and multiplicity of this parameter is the same as the type and multiplicity of the operation itself.
A feature declares a behavioral or structural characteristic of instances of classifiers. Feature is an abstract metaclass.
Semantics A feature represents some characteristic for its featuring classifiers; this characteristic may be of the classifier’s instances considered individually (not static), or of the classifier itself (static). A Feature can be a feature of multiple classifiers. The same feature cannot be static in one context but not another.
Semantic Variation Points With regard to static features, two alternative semantics are recognized. A static feature may have different values for different featuring classifiers, or the same value for all featuring classifiers. In accord with this semantic variation point, inheritance of values for static features is permitted but not required by UML 2. Such inheritance is encouraged when modeling systems will be coded in languages, such as C++, Java, and C#, which stipulate inheritance of values for static features.
An Association specifies a semantic relationship that can occur between typed instances. It has at least two memberEnds represented by Properties, each of which has the type of the end. More than one end of the Association may have the same type.
An Association declares that there can be links between instances of the associated types. A link is a tuple with one value for each memberEnd of the Association, where each value is an instance of the type of the end.
Not all links need to be classified by an Association.
When one or more ends of the Association have isUnique=false, it is possible to have several links associating the same set of instances. In such a case, links carry an additional identifier apart from their end values.
When one or more ends of the Association are ordered, links carry ordering information in addition to their end values.
For an Association with N memberEnds, choose any N-1 ends and associate specific instances with those ends. Then the collection of links of the Association that refer to these specific instances will identify a collection of instances at the other end. The multiplicity of the other end constrains the size of this collection. If the other end is marked as isOrdered, this collection will be ordered. If the other end is marked as isUnique, this collection is a set; otherwise, it allows duplicate elements.
Subsetting represents the familiar set-theoretic concept. It applies to the collections represented by Association ends, not to the Association itself. It means that the subsetting Association end represents a collection that is either equal to or a proper subset of the collection that it is subsetting. Subsetting is a relationship in the domain of extensional semantics.
Specialization is, in contrast to subsetting, a relationship in the domain of intentional semantics, which is to say it characterizes the criteria whereby membership in the collection is defined, not by the membership. In the case of Associations, specialization means that a link classified by the specializing association is also classified by the specialized association. Semantically this implies that the collections representing the ends of the specializing association are subsets of the corresponding collections representing the ends of the specialized association; this fact of subsetting may or may not be explicitly declared in a model.
Note – For n-ary Associations, the lower multiplicity of an end is typically 0. A lower multiplicity for an end of an n-ary Association of 1 (or more) implies that one link (or more) must exist for every possible combination of values for the other ends.
A binary Association may represent a composite aggregation (i.e., a whole/part relationship). Composition is represented by the isComposite attribute on the part end of the Association being set to true. See the semantics of composition in 9.5.3.
An end Property of an Association that is owned by an end Class or that is a navigableOwnedEnd of the Association indicates that the Association is navigable from the opposite ends; otherwise, the Association is not navigable from the opposite ends. Navigability means that instances participating in links at runtime (instances of an Association) can be accessed efficiently from instances at the other ends of the Association. The precise mechanism by which such efficient access is achieved is implementation specific. If an end is not navigable, access from the other ends may or may not be possible, and if it is, it might not be efficient. Note that tools operating on UML models are not prevented from navigating Associations from non-navigable ends.
The existence of an association may be derived from other information in the model. The logical relationship between the derivation of an Association and the derivation of its ends is model-specific.
Properties are StructuralFeatures that represent the attributes of Classifiers, the memberEnds of Associations, and the parts of StructuredClassifiers.
Description Property represents a declared state of one or more instances in terms of a named relationship to a value or values. When a property is an attribute of a classifier, the value or values are related to the instance of the classifier by being held in slots of the instance. When a property is an association end, the value or values are related to the instance or instances at the other end(s) of the association (see semantics of Association). Property is indirectly a subclass of Constructs::TypedElement. The range of valid values represented by the property can be controlled by setting the property’s type.
Semantics When a property is owned by a classifier other than an association via ownedAttribute, then it represents an attribute of the class or data type. When related to an association via memberEnd or one of its specializations, it represents an end of the association. In either case, when instantiated a property represents a value or collection of values associated with an instance of one (or in the case of a ternary or higher-order association, more than one) type. This set of classifiers is called the context for the property; in the case of an attribute the context is the owning classifier, and in the case of an association end the context is the set of types at the other end or ends of the association. The value or collection of values instantiated for a property in an instance of its context conforms to the property’s type. Property inherits from MultiplicityElement and thus allows multiplicity bounds to be specified. These bounds constrain the size of the collection. Typically and by default the maximum bound is 1. Property also inherits the isUnique and isOrdered meta-attributes. When isUnique is true (the default) the collection of values may not contain duplicates. When isOrdered is true (false being the default) the collection of values is ordered. In combination these two allow the type of a property to represent a collection in the following way:
If there is a default specified for a property, this default is evaluated when an instance of the property is created in the absence of a specific setting for the property or a constraint in the model that requires the property to have a specific value. The evaluated default then becomes the initial value (or values) of the property. If a property is derived, then its value or values can be computed from other information. Actions involving a derived property behave the same as for a nonderived property. Derived properties are often specified to be read-only (i.e., clients cannot directly change values). But where a derived property is changeable, an implementation is expected to make appropriate changes to the model in order for all the constraints to be met, in particular the derivation constraint for the derived property. The derivation for a derived property may be specified by a constraint. The name and visibility of a property are not required to match those of any property it redefines. A derived property can redefine one which is not derived. An implementation must ensure that the constraints implied by the derivation are maintained if the property is updated. If a property has a specified default, and the property redefines another property with a specified default, then the redefining property’s default is used in place of the more general default from the redefined property. If a navigable property is marked as readOnly, then it cannot be updated once it has been assigned an initial value.
A property may be marked as the subset of another, as long as every element in the context of subsetting property conforms to the corresponding element in the context of the subsetted property. In this case, the collection associated with an instance of the subsetting property must be included in (or the same as) the collection associated with the corresponding instance of the subsetted property. A property may be marked as being a derived union. This means that the collection of values denoted by the property in some context is derived by being the strict union of all of the values denoted, in the same context, by properties defined to subset it. If the property has a multiplicity upper bound of 1, then this means that the values of all the subsets must be null or the same. A property may be owned by and in the namespace of a datatype A property may be marked as being (part of) the identifier (if any) for classes of which it is a member. The interpretation of this is left open but this could be mapped to implementations such as primary keys for relational database tables or ID attributes in XML. If multiple properties are marked (possibly in superclasses), then it is the combination of the (property, value) tuples that will logically provide the uniqueness for any instance. Hence there is no need for any specification of order and it is possible for some (but not all) of the property values to be empty. If the property is multivalued, then all values are included.
Description A type constrains the values represented by a typed element.
Semantics A type serves as a constraint on the range of values represented by a typed element. Type is an abstract metaclass.
A usage is a relationship in which one element requires another element (or set of elements) for its full implementation or operation. In the metamodel, a Usage is a Dependency in which the client requires the presence of the supplier.
The usage dependency does not specify how the client uses the supplier other than the fact that the supplier is used by the definition or implementation of the client.
Predefined Stereotypes:
A Dependency implies that the semantics of the clients are not complete without the suppliers. The presence of Dependency relationships in a model does not have any runtime semantic implications. The semantics are all given in terms of the NamedElements that participate in the relationship, not in terms of their instances.
A Dependency is a Relationship that signifies that a single or a set of model Elements requires other model Elements for their specification or implementation. This means that the complete semantics of the client Element(s) are either semantically or structurally dependent on the definition of the supplier Element(s).
An Abstraction is a Dependency that relates two NamedElements or sets of NamedElements that represent the same concept at different levels of abstraction or from different viewpoints. The relationship may be defined as a mapping between the suppliers and the clients. Depending on the specific stereotype of Abstraction, the mapping may be formal or informal, and it may be unidirectional or bidirectional. Abstraction has predefined stereotypes (such as «derive», «refine», and «trace») that are defined in the Standard Profile (see Clause 22). If an Abstraction has more than one client, the supplier maps into the set of clients as a group. For example, an analysis-level Class might be split into several design-level Classes. The situation is similar if there is more than one supplier.
Predefined Stereotypes:
A Deployment captures the relationship between a particular conceptual or physical element of a modeled system and the information assets assigned to it. System elements are represented as DeployedTargets, and information assets, as DeployedArtifacts. DeploymentTargets and DeploymentArtifacts are abstract classes that cannot be directly instantiated. They are, however, elaborated as concrete classes as described in the Artifacts and Nodes subclauses that follow.
Individual Deployment relationships can be tailored for specific uses by adding DeploymentSpecifications containing configurational and/or parametric information and may be extended in specific component profiles. For example, standard, non-normative stereotypes that a profile might add to DeploymentSpecification include «concurrencyMode», with tagged values {thread, process, none}, and «transactionMode», with tagged values {transaction, nestedTransaction, none}.
DeploymentSpecification information becomes execution-time input to components associated with DeploymentTargets via their deployedElements links. Using these links, DeploymentSpecifications can be targeted at specific container types, as long as the containers are kinds of Components. As shown in Figure 19-1, DeploymentSpecifications can be captured as elements of the Deployment relationships because they are Artifacts (described in the following subclause). Furthermore, 702
DeploymentSpecifications can only be associated with DeploymentTargets that are ExecutionEnvironments (described in the Nodes subclause, below).
The Deployment relationship between a DeployedArtifact and a DeploymentTarget can be defined at the “type” level and at the “instance” level. At the “type” level, the Deployment connects kinds of DeploymentTargets to kinds of DeployedArtifacts. Whereas, at the “instance” level, the Deployment connects particular DeploymentTargets instances to particular DeployedArtifacts instances. For example, a ”type” level Deployment might connect an “application server” with an “order entry request handler.” In contrast, at the ”instance” level, three specific application services (say, “app-server1”, “app-server-2” and “app-server3”) may be the DeploymentTargets for six different “request handler” instances.
For modeling complex models consisting of composite structures, a Property, functioning as a part (i.e., owned by a composition), may be the target of a Deployment. Likewise, InstanceSpecifications can be DeploymentTargets in a Deployment relationship, if they represent a Node that functions as a part within an encompassing Node composition hierarchy, or if they represent an Artifact.
Description Realization is a specialized abstraction relationship between two sets of model elements, one representing a specification (the supplier) and the other represents an implementation of the latter (the client). Realization can be used to model stepwise refinement, optimizations, transformations, templates, model synthesis, framework composition, etc.
Semantics A Realization signifies that the client set of elements are an implementation of the supplier set, which serves as the specification. The meaning of ‘implementation’ is not strictly defined, but rather implies a more refined or elaborate form in respect to a certain modeling context. It is possible to specify a mapping between the specification and implementation elements, although it is not necessarily computable.
Description A substitution is a relationship between two classifiers which signifies that the substitutingClassifier complies with the contract specified by the contract classifier. This implies that instances of the substitutingClassifier are runtime substitutable where instances of the contract classifier are expected.
A Generalization is a taxonomic relationship between a more general Classifier and a more specific Classifier. Each instance of the specific Classifier is also an instance of the general Classifier. The specific Classifier inherits the features of the more general Classifier. A Generalization is owned by the specific Classifier.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
An InformationFlow specifies that one or more information items circulates from its sources to its targets. Information flows require some kind of “information channel” for transmitting information items from the source to the destination. An information channel is represented in various ways depending on the nature of its sources and targets. It may be represented by connectors, links, associations, or even dependencies. For example, if the source and destination are parts in some composite structure such as a collaboration, then the information channel is likely to be represented by a connector between them. Or, if the source and target are objects (which are a kind of InstanceSpecification), they may be represented by a link that joins the two, and so on.
Semantics An information flow is an abstraction of the communication of an information item from its sources to its targets. It is used to abstract the communication of information between entities of a system. Sources or targets of an information flow designate sets of objects that can send or receive the conveyed information item. When a source or a target is a classifier, it represents all the potential instances of the classifier; when it is a part, it represents all instances that can play the role specified by the part; when it is a package, it represents all potential instances of the directly or indirectly owned classifiers of the package. An information flow may directly indicate a concrete classifier, such as a class, that is conveyed instead of using an information item.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
A Connector specifies links that enables communication between two or more instances. In contrast to Associations, which specify links between any instance of the associated Classifiers, Connectors specify links between instances playing the connected parts only. The connector concept is extended in the Components package to include contracts and notation.
A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling.
An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics
A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts.
Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only).
A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
A Message defines a particular communication between Lifelines of an Interaction.
A Message is a NamedElement that defines one specific kind of communication in an Interaction. A communication can be, for example, raising a signal, invoking an Operation, creating or destroying an Instance. The Message specifies not only the kind of communication given by the dispatching ExecutionSpecification, but also the sender and the receiver. A Message associates normally two OccurrenceSpecifications - one sending OccurrenceSpecification and one receiving OccurrenceSpecification.
Semantics
The semantics of a complete Message is simply the trace <sendEvent, receiveEvent>. A lost message is a message where the sending event occurrence is known, but there is no receiving event occurrence. We interpret this to be because the message never reached its destination. The semantics is simply the trace <sendEvent>. A found message is a message where the receiving event occurrence is known, but there is no (known) sending event occurrence. We interpret this to be because the origin of the message is outside the scope of the description. This may for example be noise or other activity that we do not want to describe in detail. The semantics is simply the trace <receiveEvent>. A Message reflects either an Operation call and start of execution or a sending and reception of a Signal.When a Message represents an Operation, the arguments of the Message are the arguments of the Operation. When a Message represents a Signal, the arguments of the Message are the attributes of the Signal.
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
A decision node is a control node that chooses between outgoing flows.
Description A decision node accepts tokens on an incoming edge and presents them to multiple outgoing edges. Which of the edges is actually traversed depends on the evaluation of the guards on the outgoing edges.
Semantics Each token arriving at a decision node can traverse only one outgoing edge. Tokens are not duplicated. Each token offered by the incoming edge is offered to the outgoing edges. Most commonly, guards of the outgoing edges are evaluated to determine which edge should be traversed. The order in which guards are evaluated is not defined, because edges in general are not required to determine which tokens they accept in any particular order. The modeler should arrange that each token only be chosen to traverse one outgoing edge; otherwise, there will be race conditions among the outgoing edges. If the implementation can ensure that only one guard will succeed, it is not required to evaluate all guards when one is found that does. For decision points, a predefined guard “else” may be defined for at most one outgoing edge. This guard succeeds for a token only if the token is not accepted by all the other edges outgoing from the decision point. Notice that the semantics only requires that the token traverse one edge, rather than be offered to only one edge. Multiple edges may be offered the token, but if only one of them has a target that accepts the token, then that edge is traversed. If multiple edges accept the token and have approval from their targets for traversal at the same time, then the semantics is not defined. If a decision input behavior is specified, then each data token is passed to the behavior before guards are evaluated on the outgoing edges. The behavior is invoked without input for control tokens. The output of the behavior is available to the guard. Because the behavior is used during the process of offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. It may not modify objects, but it may for example, navigate from one object to another or get an attribute value from an object. If there is a decision input flow, but no decision input behavior, then it is the tokens offered on the decision input flow that are made available to the guard on each outgoing edge to determine whether the offer on the regular incoming edge is passed along that outgoing edge. If there is a decision input behavior and a decision input flow, the token offered on the decision input flow is passed to the behavior (as the only argument if the regular incoming edge is control flow, as the second argument if it is an object flow). Decision nodes with the additional decision input flow offer tokens to outgoing edges only when one token is offered on each incoming edge.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
An InformationFlow specifies that one or more information items circulates from its sources to its targets. Information flows require some kind of “information channel” for transmitting information items from the source to the destination. An information channel is represented in various ways depending on the nature of its sources and targets. It may be represented by connectors, links, associations, or even dependencies. For example, if the source and destination are parts in some composite structure such as a collaboration, then the information channel is likely to be represented by a connector between them. Or, if the source and target are objects (which are a kind of InstanceSpecification), they may be represented by a link that joins the two, and so on.
Semantics An information flow is an abstraction of the communication of an information item from its sources to its targets. It is used to abstract the communication of information between entities of a system. Sources or targets of an information flow designate sets of objects that can send or receive the conveyed information item. When a source or a target is a classifier, it represents all the potential instances of the classifier; when it is a part, it represents all instances that can play the role specified by the part; when it is a package, it represents all potential instances of the directly or indirectly owned classifiers of the package. An information flow may directly indicate a concrete classifier, such as a class, that is conveyed instead of using an information item.
An interruptible activity region is an activity group that supports termination of tokens flowing in the portions of an activity.
An interruptible region contains activity nodes. When a token leaves an interruptible region via edges designated by the region as interrupting edges, all tokens and behaviors in the region are terminated.
The region is interrupted, including accept event actions in the region, when a token traverses an interrupting edge. At this point the interrupting token has left the region and is not terminated. AcceptEventActions in the region that do not have incoming edges are enabled only when a token enters the region, even if the token is not directed at the accept event action.
Token transfer is still atomic, even when using interrupting regions. If a non-interrupting edge is passing a token from a source node in the region to target node outside the region, then the transfer is completed and the token arrives at the target even if an interruption occurs during the traversal. In other words, a token transition is never partial; it is either complete or it does not happen at all.
Do not use an interrupting region if it is not desired to abort all flows in the region in some cases. For example, if the same execution of an activity is being used for all its invocations, then multiple streams of tokens will be flowing through the same activity. In this case, it is probably not desired to abort all tokens just because one leaves the region. Arrange for separate invocations of the activity to use separate executions of the activity when employing interruptible regions, so tokens from each invocation will not affect each other.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description Activity parameter nodes are object nodes at the beginning and end of flows that provide a means to accept inputs to an activity and provide outputs from the activity, through the activity parameters. Activity parameters inherit support for streaming and exceptions from Parameter.
Constraints
[1] Activity parameter nodes must have parameters from the containing activity.
[2] The type of an activity parameter node is the same as the type of its parameter.
[3] An activity parameter node may have either all incoming edges or all outgoing edges, but it must not have both incoming and outgoing edges.
[4] Activity parameter object nodes with no incoming edges and one or more outgoing edges must have a parameter with in or inout direction.
[5] Activity parameter object nodes with no outgoing edges and one or more incoming edges must have a parameter with out, inout, or return direction.
[6] A parameter with direction other than inout must have at most one activity parameter node in an activity.
[7] A parameter with direction inout must have at most two activity parameter nodes in an activity, one with incoming flows and one with outgoing flows.
See “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319.
Semantics As a kind of behavior, an activity may have owned parameters. Within the activity, in and inout parameters may be associated with activity parameter nodes that have no incoming edges—they provide a source within the activity for the overall “input values” of the activity. Similarly, inout, out, and return parameters may be associated with activity nodes that have no outgoing edges—they provide a sink within the activity for the overall “output values” of the activity.
Per the general semantics of a behavior, when the activity is invoked, its in and inout parameters may be given actual values. These input values are placed as tokens on those activity parameter nodes within the activity that are associated with the corresponding in and inout parameters, the ones which do not have incoming edges. The overall activity input values are then available within the activity via the outgoing edges of the activity parameter nodes. During the course of execution of the activity, tokens may flow into those activity parameter nodes within the activity that have incoming edges. When the execution of the activity completes, the output values held by these activity parameter nodes are given to the corresponding inout, out, and return parameters of the activity. If the parameter associated with an activity parameter node is marked as streaming, then the above semantics are extended to allow for inputs to arrive and outputs to be posted during the execution of the activity (see the semantics for Parameter). In this case, for an activity parameter node with no incoming edges, an input value is placed on the activity parameter node whenever an input arrives on the corresponding streaming in or inout parameter. For an activity parameter node with no outgoing edges, an output value is posted on the corresponding inout, out or return parameter whenever a token arrives at the activity parameter node.
Description A UseCase is a kind of behaviored classifier that represents a declaration of an offered behavior. Each use case specifies some behavior, possibly including variants, that the subject can perform in collaboration with one or more actors. Use cases define the offered behavior of the subject without reference to its internal structure. These behaviors, involving interactions between the actor and the subject, may result in changes to the state of the subject and communications with its environment. A use case can include possible variations of its basic behavior, including exceptional behavior and error handling. The subject of a use case could be a system or any other element that may have behavior, such as a component, subsystem, or class. Each use case specifies a unit of useful functionality that the subject provides to its users (i.e., a specific way of interacting with the subject). This functionality, which is initiated by an actor, must always be completed for the use case to complete. It is deemed complete if, after its execution, the subject will be in a state in which no further inputs or actions are expected and the use case can be initiated again or in an error state. Use cases can be used both for specification of the (external) requirements on a subject and for the specification of the functionality offered by a subject. Moreover, the use cases also state the requirements the specified subject poses on its environment by defining how they should interact with the subject so that it will be able to perform its services. The behavior of a use case can be described by a specification that is some kind of Behavior (through its ownedBehavior relationship), such as interactions, activities, and state machines, or by pre-conditions and post-conditions as well as by natural language text where appropriate. It may also be described indirectly through a Collaboration that uses the use case and its actors as the classifiers that type its parts. Which of these techniques to use depends on the nature of the use case behavior as well as on the intended reader. These descriptions can be combined. An example of a use case with an associated state machine description is shown in Figure 16.6.
Semantics An execution of a use case is an occurrence of emergent behavior. Every instance of a classifier realizing a use case must behave in the manner described by the use case. Use cases may have associated actors, which describes how an instance of the classifier realizing the use case and a user playing one of the roles of the actor interact. Two use cases specifying the same subject cannot be associated since each of them individually describes a complete usage of the subject. It is not possible to state anything about the internal behavior of the actor apart from its communications with the subject. When a use case has an association to an actor with a multiplicity that is greater than one at the actor end, it means that more than one actor instance is involved in initiating the use case. The manner in which multiple actors participate in the use case depends on the specific situation on hand and is not defined in this specification. For instance, a particular use case might require simultaneous (concurrent) action by two separate actors (e.g., in launching a nuclear missile) or it might require complementary and successive actions by the actors (e.g., one actor starting something and the other one stopping it).
Description A UseCase is a kind of behaviored classifier that represents a declaration of an offered behavior. Each use case specifies some behavior, possibly including variants, that the subject can perform in collaboration with one or more actors. Use cases define the offered behavior of the subject without reference to its internal structure. These behaviors, involving interactions between the actor and the subject, may result in changes to the state of the subject and communications with its environment. A use case can include possible variations of its basic behavior, including exceptional behavior and error handling. The subject of a use case could be a system or any other element that may have behavior, such as a component, subsystem, or class. Each use case specifies a unit of useful functionality that the subject provides to its users (i.e., a specific way of interacting with the subject). This functionality, which is initiated by an actor, must always be completed for the use case to complete. It is deemed complete if, after its execution, the subject will be in a state in which no further inputs or actions are expected and the use case can be initiated again or in an error state. Use cases can be used both for specification of the (external) requirements on a subject and for the specification of the functionality offered by a subject. Moreover, the use cases also state the requirements the specified subject poses on its environment by defining how they should interact with the subject so that it will be able to perform its services. The behavior of a use case can be described by a specification that is some kind of Behavior (through its ownedBehavior relationship), such as interactions, activities, and state machines, or by pre-conditions and post-conditions as well as by natural language text where appropriate. It may also be described indirectly through a Collaboration that uses the use case and its actors as the classifiers that type its parts. Which of these techniques to use depends on the nature of the use case behavior as well as on the intended reader. These descriptions can be combined. An example of a use case with an associated state machine description is shown in Figure 16.6.
Semantics An execution of a use case is an occurrence of emergent behavior. Every instance of a classifier realizing a use case must behave in the manner described by the use case. Use cases may have associated actors, which describes how an instance of the classifier realizing the use case and a user playing one of the roles of the actor interact. Two use cases specifying the same subject cannot be associated since each of them individually describes a complete usage of the subject. It is not possible to state anything about the internal behavior of the actor apart from its communications with the subject. When a use case has an association to an actor with a multiplicity that is greater than one at the actor end, it means that more than one actor instance is involved in initiating the use case. The manner in which multiple actors participate in the use case depends on the specific situation on hand and is not defined in this specification. For instance, a particular use case might require simultaneous (concurrent) action by two separate actors (e.g., in launching a nuclear missile) or it might require complementary and successive actions by the actors (e.g., one actor starting something and the other one stopping it).
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description Activity groups are a generic grouping construct for nodes and edges. Nodes and edges can belong to more than one group. They have no inherent semantics and can be used for various purposes. Subclasses of ActivityGroup may add semantics.
Rationale Activity groups provide a generic grouping mechanism that can be used for various purposes, as defined in the subclasses of ActivityGroup, and in extensions and profiles.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
An InformationFlow specifies that one or more information items circulates from its sources to its targets. Information flows require some kind of “information channel” for transmitting information items from the source to the destination. An information channel is represented in various ways depending on the nature of its sources and targets. It may be represented by connectors, links, associations, or even dependencies. For example, if the source and destination are parts in some composite structure such as a collaboration, then the information channel is likely to be represented by a connector between them. Or, if the source and target are objects (which are a kind of InstanceSpecification), they may be represented by a link that joins the two, and so on.
Semantics An information flow is an abstraction of the communication of an information item from its sources to its targets. It is used to abstract the communication of information between entities of a system. Sources or targets of an information flow designate sets of objects that can send or receive the conveyed information item. When a source or a target is a classifier, it represents all the potential instances of the classifier; when it is a part, it represents all instances that can play the role specified by the part; when it is a package, it represents all potential instances of the directly or indirectly owned classifiers of the package. An information flow may directly indicate a concrete classifier, such as a class, that is conveyed instead of using an information item.
An interruptible activity region is an activity group that supports termination of tokens flowing in the portions of an activity.
An interruptible region contains activity nodes. When a token leaves an interruptible region via edges designated by the region as interrupting edges, all tokens and behaviors in the region are terminated.
The region is interrupted, including accept event actions in the region, when a token traverses an interrupting edge. At this point the interrupting token has left the region and is not terminated. AcceptEventActions in the region that do not have incoming edges are enabled only when a token enters the region, even if the token is not directed at the accept event action.
Token transfer is still atomic, even when using interrupting regions. If a non-interrupting edge is passing a token from a source node in the region to target node outside the region, then the transfer is completed and the token arrives at the target even if an interruption occurs during the traversal. In other words, a token transition is never partial; it is either complete or it does not happen at all.
Do not use an interrupting region if it is not desired to abort all flows in the region in some cases. For example, if the same execution of an activity is being used for all its invocations, then multiple streams of tokens will be flowing through the same activity. In this case, it is probably not desired to abort all tokens just because one leaves the region. Arrange for separate invocations of the activity to use separate executions of the activity when employing interruptible regions, so tokens from each invocation will not affect each other.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
Trigger (from InvocationActions) Description A trigger specification may be qualified by the port on which the event occurred.
Semantics Specifying one or more ports for an event implies that the event triggers the execution of an associated behavior only if the event was received via one of the specified ports.
Trigger (from Communications) Description A trigger specifies an event that may cause the execution of an associated behavior. An event is often ultimately caused by the execution of an action, but need not be.
Semantics Events may cause execution of behavior (e.g., the execution of the effect activity of a transition in a state machine). A trigger specifies the event that may trigger a behavior execution as well as any constraints on the event to filter out events not of interest. Events are often generated as a result of some action either within the system or in the environment surrounding the system. Upon their occurrence, events are placed into the input pool of the object where they occurred (see BehavioredClassifier on page 449). An event is dispatched when it is taken from the input pool and is processed by the classifier. At this point, the event is considered consumed and referred to as the current event. A consumed event is no longer available for processing. (Note that an event identified as deferred by a state that does not fire any trigger is not dispatched and is therefore never consumed; see “State (from BehaviorStateMachines, ProtocolStateMachines)”
Semantic Variation Points No assumptions are made about the time intervals between event occurrence, event dispatching, and consumption. This leaves open the possibility of different semantic variations such as zero-time semantics.
A trigger for an AnyReceiveEvent is triggered by the receipt of any message that is not explicitly handled by any related trigger.
Semantics A trigger for AnyReceiveEvent may be triggered by the receipt of any message (signal send or operation call). However, if there is a related SignalEvent or CallEvent trigger that specifically matches the message, then the AnyReceiveEvent trigger is not triggered by the message. Which other triggers are related to an AnyReceiveEvent trigger depends on the context of the trigger (in particular, see 11.3.2, “AcceptEventAction (from CompleteActions)” on page 241 and 15.3.14, “Transition (from BehaviorStateMachines)”
A CallEvent models the receipt by an object of a message invoking a call of an operation.
Description A call event represents the reception of a request to invoke a specific operation. A call event is distinct from the call action that caused it. A call event may cause the invocation of a behavior that is the method of the operation referenced by the call request, if that operation is owned or inherited by the classifier that specified the receiver object.
Semantics A call event represents the reception of a request to invoke a specific operation on an object. The call event may result in the execution of the behavior that implements the called operation. A call event may, in addition, cause other responses, such as a state machine transition, as specified in the classifier behavior of the classifier that specified the receiver object. In that case, the additional behavior is invoked after the completion of the operation referenced by the call event. A call event makes available any argument values carried by the received call request to all behaviors caused by this event (such as transition actions or entry actions).
Description A transition is a directed relationship between a source vertex and a target vertex. It may be part of a compound transition, which takes the state machine from one state configuration to another, representing the complete response of the state machine to an occurrence of an event of a particular type.
Semantics High-level transitions Transitions originating from composite states themselves are called high-level or group transitions. If triggered, they result in exiting of all the substates of the composite state executing their exit activities starting with the innermost states in the active state configuration. Note that in terms of execution semantics, a high-level transition does not add specialized semantics, but rather reflects the semantics of exiting a composite state. A high-level transition with a target outside the composite state will imply the execution of the exit action of the composite state, while a high-level transition with a target inside the composite state will not imply execution of the exit action of the composite state. Compound transitions A compound transition is a derived semantic concept, represents a “semantically complete” path made of one or more transitions, originating from a set of states (as opposed to pseudo-state) and targeting a set of states. The transition execution semantics described below refer to compound transitions. In general, a compound transition is an acyclical unbroken chain of transitions joined via join, junction, choice, or fork pseudostates that define path from a set of source states (possibly a singleton) to a set of destination states, (possibly a singleton). For self-transitions, the same state acts as both the source and the destination set. A (simple) transition connecting two states is therefore a special common case of a compound transition. The tail of a compound transition may have multiple transitions originating from a set of mutually orthogonal regions that are joined by a join point. The head of a compound transition may have multiple transitions originating from a fork pseudostate targeted to a set of mutually orthogonal regions.
In a compound transition multiple outgoing transitions may emanate from a common junction point. In that case, only one of the outgoing transitions whose guard is true is taken. If multiple transitions have guards that are true, a transition from this set is chosen. The algorithm for selecting such a transition is not specified. Note that in this case, the guards are evaluated before the compound transition is taken. In a compound transition where multiple outgoing transitions emanate from a common choice point, the outgoing transition whose guard is true at the time the choice point is reached, will be taken. If multiple transitions have guards that are true, one transition from this set is chosen. The algorithm for selecting this transition is not specified. If no guards are true after the choice point has been reached, the model is ill-formed. The owner of a transition is not explicitly constrained, though the region must be owned directly or indirectly by the owning state machine context. A suggested owner of a transition is the LCA of the source and target vertices. Internal transitions An internal transition executes without exiting or re-entering the state in which it is defined. This is true even if the state machine is in a nested state within this state. Completion transitions and completion events A completion transition is a transition originating from a state or an exit point but which does not have an explicit trigger, although it may have a guard defined. A completion transition is implicitly triggered by a completion event. In case of a leaf state, a completion event is generated once the entry actions and the internal activities (“do” activities) have been completed. If no actions or activities exist, the completion event is generated upon entering the state. If the state is a composite state or a submachine state, a completion event is generated if either the submachine or the contained region has reached a final state and the state’s internal activities have been completed. This event is the implicit trigger for a completion transition. The completion event is dispatched before any other events in the pool and has no associated parameters. For instance, a completion transition emanating from an orthogonal composite state will be taken automatically as soon as all the orthogonal regions have reached their final state. If multiple completion transitions are defined for a state, then they should have mutually exclusive guard conditions.
Enabled (compound) transitions A transition is enabled if and only if: • All of its source states are in the active state configuration. • One of the triggers of the transition is satisfied by the event (type) of the current occurrence. An event satisfies a trigger if it matches the event specified by the trigger. In case of signal events, since signals are generalized concepts, a signal event satisfies a signal event associated with the same signal or a generalization thereof. If one of the triggers is for an AnyReceiveEvent, then a signal or call event satisfies this trigger if there is no other signal or call event trigger on the same transition, or any other transition having the same source vertex as the transition with the AnyReceiveEvent trigger (see also “AnyReceiveEvent (from Communications)” on page 444). • If there exists at least one full path from the source state configuration to either the target state configuration or to a dynamic choice point in which all guard conditions are true (transitions without guards are treated as if their guards are always true). Since more than one transition may be enabled by the same event, being enabled is a necessary but not sufficient condition for the firing of a transition.
Guards In a simple transition with a guard, the guard is evaluated before the transition is triggered. In compound transitions involving multiple guards, all guards are evaluated before a transition is triggered, unless there are choice points along one or more of the paths. The order in which the guards are evaluated is not defined. If there are choice points in a compound transition, only guards that precede the choice point are evaluated according to the above rule. Guards downstream of a choice point are evaluated if and when the choice point is reached (using the same rule as above). In other words, for guard evaluation, a choice point has the same effect as a state. Guards should not include expressions causing side effects. Models that violate this are considered ill-formed. Transition execution sequence Every transition, except for internal and local transitions, causes exiting of a source state, and entering of the target state. These two states, which may be composite, are designated as the main source and the main target of a transition. The least common ancestor (LCA) state of a (compound) transition is a region or an orthogonal state that is the LCA of the source and target states of the (compound) transition. The LCA operation is an operation defined for the StateMachine class. If the LCA is a Region, then the main source is a direct subvertex of the region that contains the source states, and the main target is the subvertex of the region that contains the target states. In the case where the LCA is an orthogonal state, the main source and the main target are both represented by the orthogonal state itself. The reason is that a transition crossing regions of an orthogonal state forces exit from the entire orthogonal state and re-entering of all of its regions.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description
An interaction is a unit of behavior that focuses on the observable exchange of information between ConnectableElements. An Interaction is a specialization of InteractionFragment and of Behavior.
Semantics
Interactions are units of behavior of an enclosing Classifier. Interactions focus on the passing of information with Messages between the ConnectableElements of the Classifier. The semantics of an Interaction is given as a pair of sets of traces. The two trace sets represent valid traces and invalid traces. The union of these two sets need not necessarily cover the whole universe of traces. The traces that are not included are not described by this Interaction at all, and we cannot know whether they are valid or invalid. A trace is a sequence of event occurrences, each of which is described by an OccurrenceSpecification in a model. The semantics of Interactions are compositional in the sense that the semantics of an Interaction is mechanically built from the semantics of its constituent InteractionFragments. The constituent InteractionFragments are ordered and combined by the seq operation (weak sequencing) as explained in “Weak Sequencing” on page 483. The invalid set of traces are associated only with the use of a Negative CombinedInteraction. For simplicity we describe only valid traces for all other constructs.
those of the original. The traces defined by the specialization is combined with those of the inherited Interaction with a union. The classifier owning an Interaction may be specialized, and in the specialization the Interaction may be redefined. Redefining an Interaction simply means to exchange the redefining Interaction for the redefined one, and this exchange takes effect also for InteractionUses within the supertype of the owner. This is similar to redefinition of other kinds of Behavior.
Basic trace model: The semantics of an Interaction is given by a pair [P, I] where P is the set of valid traces and I is the set of invalid traces. need not be the whole universe of traces. A trace is a sequence of event occurrences denoted <e1, e2, ... , en>. An event occurrence will also include information about the values of all relevant objects at this point in time. Each construct of Interactions (such as CombinedFragments of different kinds) are expressed in terms of how it relates to a pair of sets of traces. For simplicity we normally refer only to the set of valid traces as these traces are those mostly modeled. Two Interactions are equivalent if their pair of trace-sets are equal.
Relation of trace model to execution model: In Chapter 13, “Common Behaviors” we find an Execution model, and this is how the Interactions Trace Model relates to the Execution model. An Interaction is an Emergent Behavior. An InvocationOccurrence in the Execution model corresponds with an (event) Occurrence in a trace. Occurrences are modeled in an Interaction by OccurrenceSpecifications. Normally in Interaction the action leading to the invocation as such is not described (such as the sending action). However, if it is desirable to go into details, a Behavior (such as an Activity) may be associated with an OccurrenceSpecification. An occurrence in Interactions is normally interpreted to take zero time. Duration is always between occurrences. Likewise a ReceiveOccurrence in the Execution model is modeled by an OccurrenceSpecification. Similarly the detailed actions following immediately from this reception are often omitted in Interactions, but may also be described explicitly with a Behavior associated with that OccurrenceSpecification. A Request in the Execution model is modeled by the Message in Interactions. An Execution in the Execution model is modeled by an ExecutionSpecification in Interactions. An Execution is defined in the trace by two Occurrences, one at the start and one at the end. This corresponds to the StartOccurrence and the CompletionOccurrence of the Execution model.
Description A state machine owns one or more regions, which in turn own vertices and transitions. The behaviored classifier context owning a state machine defines which signal and call triggers are defined for the state machine, and which attributes and operations are available in activities of the state machine. Signal triggers and call triggers for the state machine are defined according to the receptions and operations of this classifier. As a kind of behavior, a state machine may have an associated behavioral feature (specification) and be the method of this behavioral feature. In this case the state machine specifies the behavior of this behavioral feature. The parameters of the state machine in this case match the parameters of the behavioral feature and provide the means for accessing (within the state machine) the behavioral feature parameters. A state machine without a context classifier may use triggers that are independent of receptions or operations of a classifier, i.e., either just signal triggers or call triggers based upon operation template parameters of the (parameterized) statemachine.
Semantics The event pool for the state machine is the event pool of the instance according to the behaviored context classifier, or the classifier owning the behavioral feature for which the state machine is a method. Event processing - run-to-completion step Event occurrences are detected, dispatched, and then processed by the state machine, one at a time. The order of dequeuing is not defined, leaving open the possibility of modeling different priority-based schemes. The semantics of event occurrence processing is based on the run-to-completion assumption, interpreted as run-to-completion processing. Run-to-completion processing means that an event occurrence can only be taken from the pool and dispatched if the processing of the previous current occurrence is fully completed. Run-to-completion may be implemented in various ways. For active classes, it may be realized by an event-loop running in its own thread, and that reads event occurrences from a pool. For passive classes it may be implemented as a monitor. The processing of a single event occurrence by a state machine is known as a run-to-completion step. Before commencing on a run-to-completion step, a state machine is in a stable state configuration with all entry/exit/internal activities (but not necessarily state (do) activities) completed. The same conditions apply after the run-to-completion step is completed. Thus, an event occurrence will never be processed while the state machine is in some intermediate and inconsistent situation. The run-to-completion step is the passage between two state configurations of the state machine. The run-to-completion assumption simplifies the transition function of the state machine, since concurrency conflicts are avoided during the processing of event, allowing the state machine to safely complete its run-to-completion step.
When an event occurrence is detected and dispatched, it may result in one or more transitions being enabled for firing. If no transition is enabled and the event (type) is not in the deferred event list of the current state configuration, the event occurrence is discarded and the run-to-completion step is completed. In the presence of orthogonal regions it is possible to fire multiple transitions as a result of the same event occurrence — as many as one transition in each region in the current state configuration. In case where one or more transitions are enabled, the state machine selects a subset and fires them. Which of the enabled transitions actually fire is determined by the transition selection algorithm described below. The order in which selected transitions fire is not defined. Each orthogonal region in the active state configuration that is not decomposed into orthogonal regions (i.e., “bottom-level” region) can fire at most one transition as a result of the current event occurrence. When all orthogonal regions have finished executing the transition, the current event occurrence is fully consumed, and the run-to-completion step is completed. During a transition, a number of actions may be executed. If such an action is a synchronous operation invocation on an object executing a state machine, then the transition step is not completed until the invoked object completes its run-to-completion step.
Run-to-completion and concurrency It is possible to define state machine semantics by allowing the run-to-completion steps to be applied orthogonally to the orthogonal regions of a composite state, rather than to the whole state machine. This would allow the event serialization constraint to be relaxed. However, such semantics are quite subtle and difficult to implement. Therefore, the dynamic semantics defined in this document are based on the premise that a single run-to-completion step applies to the entire state machine and includes the steps taken by orthogonal regions in the active state configuration. In case of active objects, where each object has its own thread of execution, it is very important to clearly distinguish the notion of run to completion from the concept of thread pre-emption. Namely, run-to-completion event handling is performed by a thread that, in principle, can be pre-empted and its execution suspended in favor of another thread executing on the same processing node. (This is determined by the scheduling policy of the underlying thread environment — no assumptions are made about this policy.) When the suspended thread is assigned processor time again, it resumes its event processing from the point of pre-emption and, eventually, completes its event processing.
Conflicting transitions It was already noted that it is possible for more than one transition to be enabled within a state machine. If that happens, then such transitions may be in conflict with each other. For example, consider the case of two transitions originating from the same state, triggered by the same event, but with different guards. If that event occurs and both guard conditions are true, then only one transition will fire. In other words, in case of conflicting transitions, only one of them will fire in a single run-to-completion step. Two transitions are said to conflict if they both exit the same state, or, more precisely, that the intersection of the set of states they exit is non-empty. Only transitions that occur in mutually orthogonal regions may be fired simultaneously. This constraint guarantees that the new active state configuration resulting from executing the set of transitions is well-formed. An internal transition in a state conflicts only with transitions that cause an exit from that state.
Firing priorities In situations where there are conflicting transitions, the selection of which transitions will fire is based in part on an implicit priority. These priorities resolve some transition conflicts, but not all of them. The priorities of conflicting transitions are based on their relative position in the state hierarchy. By definition, a transition originating from a substate has higher priority than a conflicting transition originating from any of its containing states. The priority of a transition is defined based on its source state. The priority of joined transitions is based on the priority of the transition with the most transitively nested source state. In general, if t1 is a transition whose source state is s1, and t2 has source s2, then:
• If s1 is a direct or transitively nested substate of s2, then t1 has higher priority than t2.
• If s1 and s2 are not in the same state configuration, then there is no priority difference between t1 and t2.
Transition selection algorithm The set of transitions that will fire is a maximal set of transitions that satisfies the following conditions: • All transitions in the set are enabled.
• There are no conflicting transitions within the set.
• There is no transition outside the set that has higher priority than a transition in the set (that is, enabled transitions with highest priorities are in the set while conflicting transitions with lower priorities are left out). This can be easily implemented by a greedy selection algorithm, with a straightforward traversal of the active state configuration. States in the active state configuration are traversed starting with the innermost nested simple states and working outwards. For each state at a given level, all originating transitions are evaluated to determine if they are enabled. This traversal guarantees that the priority principle is not violated. The only non-trivial issue is resolving transition conflicts across orthogonal states on all levels. This is resolved by terminating the search in each orthogonal state once a transition inside any one of its components is fired.
StateMachine extension A state machine is generalizable. A specialized state machine is an extension of the general state machine, in that regions, vertices, and transitions may be added; regions and states may be redefined (extended: simple states to composite states and composite states by adding states and transitions); and transitions can be redefined. As part of a classifier generalization, the classifierBehavior state machine of the general classifier and the method state machines of behavioral features of the general classifier can be redefined (by other state machines). These state machines may be specializations (extensions) of the corresponding state machines of the general classifier or of its behavioral features. A specialized state machine will have all the elements of the general state machine, and it may have additional elements. Regions may be added. Inherited regions may be redefined by extension: States and vertices are inherited, and states and transitions of the regions of the state machine may be redefined. A simple state can be redefined (extended) to a composite state, by adding one or more regions. A composite state can be redefined (extended) by either extending inherited regions or by adding regions as well as by adding entry and exit points. A region is extended by adding vertices, states, and transitions and by redefining states and transitions.
A submachine state may be redefined. The submachine state machine may be replaced by another submachine state machine, provided that it has the same entry/exit points as the redefined submachine state machine, but it may add entry/ exit points. Transitions can have their content and target state replaced, while the source state and trigger are preserved. In case of multiple general classifiers, extension implies that the extension state machine gets orthogonal regions for each of the state machines of the general classifiers in addition to the one of the specific classifier.
4. Views
Views
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Views::Different Kinds of Actions
A port is a property of a classifier that specifies a distinct interaction point between that classifier and its environment or between the (behavior of the) classifier and its internal parts. Ports are connected to properties of the classifier by connectors through which requests can be made to invoke the behavioral features of a classifier. A Port may specify the services a classifier provides (offers) to its environment as well as the services that a classifier expects (requires) of its environment.
Description
Ports represent interaction points between a classifier and its environment. The interfaces associated with a port specify the nature of the interactions that may occur over a port. The required interfaces of a port characterize the requests that may be made from the classifier to its environment through this port. The provided interfaces of a port characterize requests to the classifier that its environment may make through this port. A port has the ability to specify that any requests arriving at this port are handled by the behavior of the instance of the owning classifier, rather than being forwarded to any contained instances, if any.
Semantics
A port represents an interaction point between a classifier instance and its environment or between a classifier instance and instances it may contain. A port by default has public visibility.
The required interfaces characterize services that the owning classifier expects from its environment and that it may access through this interaction point: Instances of this classifier expect that the features owned by its required interfaces will be offered by one or more instances in its environment.
The provided interfaces characterize the behavioral features that the owning classifier offers to its environment at this interaction point. The owning classifier must offer the features owned by the provided interfaces. The provided and required interfaces completely characterize any interaction that may occur between a classifier and its environment at a port with respect to the data communicated at this port and the behaviors that may be invoked through this port. The interfaces do not necessarily establish the exact sequences of interactions across the port. When an instance of a classifier is created, instances corresponding to each of its ports are created and held in the slots specified by the ports, in accordance with its multiplicity. These instances are referred to as “interaction points” and provide unique references. A link from that instance to the instance of the owning classifier is created through which communication is forwarded to the instance of the owning classifier or through which the owning classifier communicates with its environment. It is, therefore, possible for an instance to differentiate between requests for the invocation of a behavioral feature targeted at its different ports. Similarly, it is possible to direct such requests at a port, and the requests will be routed as specified by the links corresponding to connectors attached to this port. (In the following, “requests arriving at a port” shall mean “request occurrences arriving at the interaction point of this instance corresponding to this port.”)
If connectors are attached to both the port when used on a property within the internal structure of a classifier and the port on the container of an internal structure, the instance of the owning classifier will forward any requests arriving at this port along the link specified by those connectors. If there is a connector attached to only one side of a port, any requests arriving at this port will terminate at this port. For a behavior port, the instance of the owning classifier will handle requests arriving at this port, if this classifier has any behavior. If there is no behavior defined for this classifier, any communication arriving at a behavior port is lost.
Semantic Variation Points If several connectors are attached on one side of a port, then any request arriving at this port on a link derived from a connector on the other side of the port will be forwarded on links corresponding to these connectors. It is a semantic variation point whether these requests will be forwarded on all links, or on only one of those links. In the latter case, one possibility is that the link at which this request will be forwarded will be arbitrarily selected among those links leading to an instance that had been specified as being able to handle this request (i.e., this request is specified in a provided interface of the part corresponding to this instance).
Properties are StructuralFeatures that represent the attributes of Classifiers, the memberEnds of Associations, and the parts of StructuredClassifiers.
Description Property represents a declared state of one or more instances in terms of a named relationship to a value or values. When a property is an attribute of a classifier, the value or values are related to the instance of the classifier by being held in slots of the instance. When a property is an association end, the value or values are related to the instance or instances at the other end(s) of the association (see semantics of Association). Property is indirectly a subclass of Constructs::TypedElement. The range of valid values represented by the property can be controlled by setting the property’s type.
Semantics When a property is owned by a classifier other than an association via ownedAttribute, then it represents an attribute of the class or data type. When related to an association via memberEnd or one of its specializations, it represents an end of the association. In either case, when instantiated a property represents a value or collection of values associated with an instance of one (or in the case of a ternary or higher-order association, more than one) type. This set of classifiers is called the context for the property; in the case of an attribute the context is the owning classifier, and in the case of an association end the context is the set of types at the other end or ends of the association. The value or collection of values instantiated for a property in an instance of its context conforms to the property’s type. Property inherits from MultiplicityElement and thus allows multiplicity bounds to be specified. These bounds constrain the size of the collection. Typically and by default the maximum bound is 1. Property also inherits the isUnique and isOrdered meta-attributes. When isUnique is true (the default) the collection of values may not contain duplicates. When isOrdered is true (false being the default) the collection of values is ordered. In combination these two allow the type of a property to represent a collection in the following way:
If there is a default specified for a property, this default is evaluated when an instance of the property is created in the absence of a specific setting for the property or a constraint in the model that requires the property to have a specific value. The evaluated default then becomes the initial value (or values) of the property. If a property is derived, then its value or values can be computed from other information. Actions involving a derived property behave the same as for a nonderived property. Derived properties are often specified to be read-only (i.e., clients cannot directly change values). But where a derived property is changeable, an implementation is expected to make appropriate changes to the model in order for all the constraints to be met, in particular the derivation constraint for the derived property. The derivation for a derived property may be specified by a constraint. The name and visibility of a property are not required to match those of any property it redefines. A derived property can redefine one which is not derived. An implementation must ensure that the constraints implied by the derivation are maintained if the property is updated. If a property has a specified default, and the property redefines another property with a specified default, then the redefining property’s default is used in place of the more general default from the redefined property. If a navigable property is marked as readOnly, then it cannot be updated once it has been assigned an initial value.
A property may be marked as the subset of another, as long as every element in the context of subsetting property conforms to the corresponding element in the context of the subsetted property. In this case, the collection associated with an instance of the subsetting property must be included in (or the same as) the collection associated with the corresponding instance of the subsetted property. A property may be marked as being a derived union. This means that the collection of values denoted by the property in some context is derived by being the strict union of all of the values denoted, in the same context, by properties defined to subset it. If the property has a multiplicity upper bound of 1, then this means that the values of all the subsets must be null or the same. A property may be owned by and in the namespace of a datatype A property may be marked as being (part of) the identifier (if any) for classes of which it is a member. The interpretation of this is left open but this could be mapped to implementations such as primary keys for relational database tables or ID attributes in XML. If multiple properties are marked (possibly in superclasses), then it is the combination of the (property, value) tuples that will logically provide the uniqueness for any instance. Hence there is no need for any specification of order and it is possible for some (but not all) of the property values to be empty. If the property is multivalued, then all values are included.
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
A component represents a modular part of a system that encapsulates its contents and whose manifestation is replaceable within its environment. A component defines its behavior in terms of provided and required interfaces. As such, a component serves as a type whose conformance is defined by these provided and required interfaces (encompassing both their static as well as dynamic semantics). One component may therefore be substituted by another only if the two are type conformant. Larger pieces of a system’s functionality may be assembled by reusing components as parts in an encompassing component or assembly of components, and wiring them together. A component is modeled throughout the development life cycle and successively refined into deployment and run-time. A component may be manifest by one or more artifacts, and in turn, that artifact may be deployed to its execution environment. A deployment specification may define values that parameterize the component’s execution. (See Deployment clause).
Description BasicComponents A component is a subtype of Class that provides for a Component having attributes and operations, and being able to participate in Associations and Generalizations. A Component may form the abstraction for a set of realizingClassifiers that realize its behavior. In addition, because a Class itself is a subtype of an EncapsulatedClassifier, a Component may optionally have an internal structure and own a set of Ports that formalize its interaction points. A component has a number of provided and required Interfaces. A provided Interface is one that is either realized directly by the component or one of its realizingClassifiers, or it is provided by a public Port of the Component. A required interface is designated by a Usage Dependency from the Component or one of its realizingClassifiers, or it is required by a public Port.
PackagingComponents A component is extended to define the grouping aspects of packaging components. This defines the Namespace aspects of a Component through its inherited ownedMember and elementImport associations. In the namespace of a component, all model elements that are involved in or related to its definition are either owned or imported explicitly. This may include, for example, UseCases and Dependencies (e.g., mappings), Packages, Components, and Artifacts.
Semantics A component is a self contained unit that encapsulates the state and behavior of a number of classifiers. A component specifies a formal contract of the services that it provides to its clients and those that it requires from other components or services in the system in terms of its provided and required interfaces.
A component is a substitutable unit that can be replaced at design time or run-time by a component that offers equivalent functionality based on compatibility of its interfaces. As long as the environment obeys the constraints expressed by the provided and required interfaces of a component, it will be able to interact with this environment. Similarly, a system can be extended by adding new component types that add new functionality. The required and provided interfaces of a component allow for the specification of structural features such as attributes and association ends, as well as behavioral features such as operations and events. A component may implement a provided interface directly, or, its realizing classifiers may do so, or they may be inherited. The required and provided interfaces may optionally be organized through ports, these enable the definition of named sets of provided and required interfaces that are typically (but not always) addressed at run-time. A component has an external view (or “black-box” view) by means of its publicly visible properties and operations. Optionally, a behavior such as a protocol state machine may be attached to an interface, port, and to the component itself, to define the external view more precisely by making dynamic constraints in the sequence of operation calls explicit. Other behaviors may also be associated with interfaces or connectors to define the ‘contract’ between participants in a collaboration (e.g., in terms of use case, activity, or interaction specifications). The wiring between components in a system or other context can be structurally defined by using dependencies between compatible simple Ports, or between Usages and matching InterfaceRealizations that are represented by sockets and lollipops on Components on component diagrams. Creating a wiring Dependency between a Usage and a matching InterfaceRealization, or between compatible simple Ports, means that there may be some additional information, such as performance requirements, transport bindings, or other policies that determine that the interface is realized in a way that is suitable for consumption by the depending Component. Such additional information could be captured in a profile by means of stereotypes. A component also has an internal view (or “white-box” view) by means of its private properties and realizing classifiers. This view shows how the external behavior is realized internally. Dependencies on the external view provide a convenient overview of what may happen in the internal view; they do not prescribe what must happen. More detailed behavior specifications such as interactions and activities may be used to detail the mapping from external to internal behavior. A number of UML standard stereotypes exist that apply to component. For example, «subsystem» to model large-scale components, and «specification» and «realization» to model components with distinct specification and realization definitions, where one specification may have multiple realizations (see the UML Standard Elements Annex).
A port is a property of a classifier that specifies a distinct interaction point between that classifier and its environment or between the (behavior of the) classifier and its internal parts. Ports are connected to properties of the classifier by connectors through which requests can be made to invoke the behavioral features of a classifier. A Port may specify the services a classifier provides (offers) to its environment as well as the services that a classifier expects (requires) of its environment.
Description
Ports represent interaction points between a classifier and its environment. The interfaces associated with a port specify the nature of the interactions that may occur over a port. The required interfaces of a port characterize the requests that may be made from the classifier to its environment through this port. The provided interfaces of a port characterize requests to the classifier that its environment may make through this port. A port has the ability to specify that any requests arriving at this port are handled by the behavior of the instance of the owning classifier, rather than being forwarded to any contained instances, if any.
Semantics
A port represents an interaction point between a classifier instance and its environment or between a classifier instance and instances it may contain. A port by default has public visibility.
The required interfaces characterize services that the owning classifier expects from its environment and that it may access through this interaction point: Instances of this classifier expect that the features owned by its required interfaces will be offered by one or more instances in its environment.
The provided interfaces characterize the behavioral features that the owning classifier offers to its environment at this interaction point. The owning classifier must offer the features owned by the provided interfaces. The provided and required interfaces completely characterize any interaction that may occur between a classifier and its environment at a port with respect to the data communicated at this port and the behaviors that may be invoked through this port. The interfaces do not necessarily establish the exact sequences of interactions across the port. When an instance of a classifier is created, instances corresponding to each of its ports are created and held in the slots specified by the ports, in accordance with its multiplicity. These instances are referred to as “interaction points” and provide unique references. A link from that instance to the instance of the owning classifier is created through which communication is forwarded to the instance of the owning classifier or through which the owning classifier communicates with its environment. It is, therefore, possible for an instance to differentiate between requests for the invocation of a behavioral feature targeted at its different ports. Similarly, it is possible to direct such requests at a port, and the requests will be routed as specified by the links corresponding to connectors attached to this port. (In the following, “requests arriving at a port” shall mean “request occurrences arriving at the interaction point of this instance corresponding to this port.”)
If connectors are attached to both the port when used on a property within the internal structure of a classifier and the port on the container of an internal structure, the instance of the owning classifier will forward any requests arriving at this port along the link specified by those connectors. If there is a connector attached to only one side of a port, any requests arriving at this port will terminate at this port. For a behavior port, the instance of the owning classifier will handle requests arriving at this port, if this classifier has any behavior. If there is no behavior defined for this classifier, any communication arriving at a behavior port is lost.
Semantic Variation Points If several connectors are attached on one side of a port, then any request arriving at this port on a link derived from a connector on the other side of the port will be forwarded on links corresponding to these connectors. It is a semantic variation point whether these requests will be forwarded on all links, or on only one of those links. In the latter case, one possibility is that the link at which this request will be forwarded will be arbitrarily selected among those links leading to an instance that had been specified as being able to handle this request (i.e., this request is specified in a provided interface of the part corresponding to this instance).
Properties are StructuralFeatures that represent the attributes of Classifiers, the memberEnds of Associations, and the parts of StructuredClassifiers.
Description Property represents a declared state of one or more instances in terms of a named relationship to a value or values. When a property is an attribute of a classifier, the value or values are related to the instance of the classifier by being held in slots of the instance. When a property is an association end, the value or values are related to the instance or instances at the other end(s) of the association (see semantics of Association). Property is indirectly a subclass of Constructs::TypedElement. The range of valid values represented by the property can be controlled by setting the property’s type.
Semantics When a property is owned by a classifier other than an association via ownedAttribute, then it represents an attribute of the class or data type. When related to an association via memberEnd or one of its specializations, it represents an end of the association. In either case, when instantiated a property represents a value or collection of values associated with an instance of one (or in the case of a ternary or higher-order association, more than one) type. This set of classifiers is called the context for the property; in the case of an attribute the context is the owning classifier, and in the case of an association end the context is the set of types at the other end or ends of the association. The value or collection of values instantiated for a property in an instance of its context conforms to the property’s type. Property inherits from MultiplicityElement and thus allows multiplicity bounds to be specified. These bounds constrain the size of the collection. Typically and by default the maximum bound is 1. Property also inherits the isUnique and isOrdered meta-attributes. When isUnique is true (the default) the collection of values may not contain duplicates. When isOrdered is true (false being the default) the collection of values is ordered. In combination these two allow the type of a property to represent a collection in the following way:
If there is a default specified for a property, this default is evaluated when an instance of the property is created in the absence of a specific setting for the property or a constraint in the model that requires the property to have a specific value. The evaluated default then becomes the initial value (or values) of the property. If a property is derived, then its value or values can be computed from other information. Actions involving a derived property behave the same as for a nonderived property. Derived properties are often specified to be read-only (i.e., clients cannot directly change values). But where a derived property is changeable, an implementation is expected to make appropriate changes to the model in order for all the constraints to be met, in particular the derivation constraint for the derived property. The derivation for a derived property may be specified by a constraint. The name and visibility of a property are not required to match those of any property it redefines. A derived property can redefine one which is not derived. An implementation must ensure that the constraints implied by the derivation are maintained if the property is updated. If a property has a specified default, and the property redefines another property with a specified default, then the redefining property’s default is used in place of the more general default from the redefined property. If a navigable property is marked as readOnly, then it cannot be updated once it has been assigned an initial value.
A property may be marked as the subset of another, as long as every element in the context of subsetting property conforms to the corresponding element in the context of the subsetted property. In this case, the collection associated with an instance of the subsetting property must be included in (or the same as) the collection associated with the corresponding instance of the subsetted property. A property may be marked as being a derived union. This means that the collection of values denoted by the property in some context is derived by being the strict union of all of the values denoted, in the same context, by properties defined to subset it. If the property has a multiplicity upper bound of 1, then this means that the values of all the subsets must be null or the same. A property may be owned by and in the namespace of a datatype A property may be marked as being (part of) the identifier (if any) for classes of which it is a member. The interpretation of this is left open but this could be mapped to implementations such as primary keys for relational database tables or ID attributes in XML. If multiple properties are marked (possibly in superclasses), then it is the combination of the (property, value) tuples that will logically provide the uniqueness for any instance. Hence there is no need for any specification of order and it is possible for some (but not all) of the property values to be empty. If the property is multivalued, then all values are included.
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
Description A type constrains the values represented by a typed element.
Semantics A type serves as a constraint on the range of values represented by a typed element. Type is an abstract metaclass.
Description A typed element is an element that has a type that serves as a constraint on the range of values the element can represent. Typed element is an abstract metaclass.
Semantics Values represented by the element are constrained to be instances of the type. A typed element with no associated type may represent values of any type.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Description Realization is a specialized abstraction relationship between two sets of model elements, one representing a specification (the supplier) and the other represents an implementation of the latter (the client). Realization can be used to model stepwise refinement, optimizations, transformations, templates, model synthesis, framework composition, etc.
Semantics A Realization signifies that the client set of elements are an implementation of the supplier set, which serves as the specification. The meaning of ‘implementation’ is not strictly defined, but rather implies a more refined or elaborate form in respect to a certain modeling context. It is possible to specify a mapping between the specification and implementation elements, although it is not necessarily computable.
An Abstraction is a Dependency that relates two NamedElements or sets of NamedElements that represent the same concept at different levels of abstraction or from different viewpoints. The relationship may be defined as a mapping between the suppliers and the clients. Depending on the specific stereotype of Abstraction, the mapping may be formal or informal, and it may be unidirectional or bidirectional. Abstraction has predefined stereotypes (such as «derive», «refine», and «trace») that are defined in the Standard Profile (see Clause 22). If an Abstraction has more than one client, the supplier maps into the set of clients as a group. For example, an analysis-level Class might be split into several design-level Classes. The situation is similar if there is more than one supplier.
Predefined Stereotypes:
A Dependency implies that the semantics of the clients are not complete without the suppliers. The presence of Dependency relationships in a model does not have any runtime semantic implications. The semantics are all given in terms of the NamedElements that participate in the relationship, not in terms of their instances.
A Dependency is a Relationship that signifies that a single or a set of model Elements requires other model Elements for their specification or implementation. This means that the complete semantics of the client Element(s) are either semantically or structurally dependent on the definition of the supplier Element(s).
Description
AcceptEventAction is an action that waits for the occurrence of an event meeting specified condition.
Semantics
Accept event actions handle event occurrences detected by the object owning the behavior (also see “InterruptibleActivityRegion (from CompleteActivities)”).
Event occurrences are detected by objects independently of actions and the occurrences are stored by the object. The arrangement of detected event occurrences is not defined, but it is expected that extensions or profiles will specify such arrangements.
If the accept event action is executed and the object detected an event occurrence matching one of the triggers on the action and the occurrence has not been accepted by another action or otherwise consumed by another behavior, then the accept event action completes and outputs a value describing the occurrence.
If such a matching occurrence is not available, the action waits until such an occurrence becomes available, at which point the action may accept it.
In a system with concurrency, several actions or other behaviors might contend for an available event occurrence. Unless otherwise specified by an extension or profile, only one action accepts a given occurrence, even if the occurrence would satisfy multiple concurrently executing actions.
If the occurrence is a signal event occurrence and isUnmarshall is false, the result value contains a signal object whose reception by the owning object caused the occurrence.
If the occurrence is a signal event occurrence and isUnmarshall is true, the attribute values of the signal are placed on the result output pins of the action.
Signal objects may be copied in transmission and storage by the owning object, so identity might not be preserved.
An action whose trigger is a signal event is informally called an accept signal action. If the occurrence is a time event occurrence, the result value contains the time at which the occurrence transpired. Such an action is informally called a wait time action. If the occurrences are all occurrences of ChangeEvent, or all CallEvent, or a combination of these, there are no output pins (however, see “AcceptCallAction (from CompleteActions)” ).
See CommonBehavior for a description of Event specifications. If the triggers are a combination of SignalEvents and ChangeEvents, the result is a null value if a change event occurrence or a call event occurrence is accepted. If one of the triggers is an AnyReceiveEvent, and the event occurrence is for a message that is not matched by any specific SignalEvent or CallEvent trigger on the same action, then the event occurrence matches the AnyReceiveEvent (see also , “AnyReceiveEvent (from Communications)”).
This action handles asynchronous messages, including asynchronous calls. It cannot be used with synchronous calls (except see “AcceptCallAction (from CompleteActions)”).
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description CallAction is an abstract class for actions that invoke behavior and receive return values.
Semantics Parameters on behaviors and operations are totally ordered lists. To match parameters to pins on call actions, select the sublist of that list that corresponds to in and inout owned parameters (i.e., Behavior.ownedParameter). The input pins on Action::input are matched in order against these parameters in the sublist order. Then take the sublist of the parameter list that corresponds to out, inout, and return parameters. The output pins on Action::output are matched in order against these parameters in sublist order. If the behavior invoked by a call action is not reentrant, then no more than one execution of it will exist at any given time. An invocation of a non-reentrant behavior does not start the behavior when the behavior is already executing.
An invocation of a reentrant behavior may start a new execution of the behavior when offered the required tokens, even if the behavior is already executing. However, it will not invoke the behavior if there is an ongoing behavior execution invocated by the same action within the same activity execution, and the action has isLocallyReentrant=false (see “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319). See children of CallAction.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
Description A control node is an activity node used to coordinate the flows between other nodes. It covers initial node, final node and its children, fork node, join node, decision node, and merge node.
Semantics See semantics at Activity. See subclasses for the semantics of each kind of control node.
Description An object node is an activity node that indicates an instance of a particular classifier, possibly in a particular state, may be available at a particular point in the activity. Object nodes can be used in a variety of ways, depending on where objects are flowing from and to, as described in the semantics sub clause.
Package CompleteActivities Complete object nodes add support for token selection, limitation on the number of tokens, specifying the state required for tokens, and carrying control values.
Constraints Package BasicActivities
[1] All edges coming into or going out of object nodes must be object flow edges.
Package CompleteActivities
[1] If an object node has a selection behavior, then the ordering of the object node is ordered and vice versa.
[2] A selection behavior has one input parameter and one output parameter. The input parameter must be a bag of elements of the same type as the object node or a supertype of the type of object node. The output parameter must be the same or a subtype of the type of object node. The behavior cannot have side effects.
Semantics Object nodes may only contain values at runtime that conform to the type of the object node, in the state or states specified, if any. If no type is specified, then the values may be of any type. Multiple tokens containing the same value may reside in the object node at the same time. This includes data values. A token in an object node can traverse only one of the outgoing edges. An object node may indicate that its type is to be treated as a control value, even if no type is specified for the node. Control edges may be used with the object node having control type.
Package CompleteActivities An object node may not contain more tokens than its upper bound. The upper bound must be a LiteralUnlimitedNatural. An upper bound of * means the upper bound is unlimited. See ObjectFlow for additional rules regarding when objects may traverse the edges incoming and outgoing from an object node.The ordering of an object node specifies the order in which tokens in the node are offered to the outgoing edges. This can be set to require that tokens do not overtake each other as they pass through the node (FIFO), or that they do (LIFO or modeler-defined ordering). Modeler-defined ordering is indicated by an ordering value of ordered, and a selection behavior that determines what token to offer to the edges. The selection behavior takes all the tokens in the object node as input and chooses a single token from those. It is executed whenever a token is to be offered to an edge. Because the behavior is used while offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. The selection behavior of an object node is overridden by any selection behaviors on its outgoing edges (see “ObjectFlow”). Overtaking due to ordering is distinguished from the case where each invocation of the activity is handled by a separate execution of the activity. In this case, the tokens have no interaction with each other, because they flow through separate executions of the activity (see “Activity”).
Description Activity parameter nodes are object nodes at the beginning and end of flows that provide a means to accept inputs to an activity and provide outputs from the activity, through the activity parameters. Activity parameters inherit support for streaming and exceptions from Parameter.
Constraints
[1] Activity parameter nodes must have parameters from the containing activity.
[2] The type of an activity parameter node is the same as the type of its parameter.
[3] An activity parameter node may have either all incoming edges or all outgoing edges, but it must not have both incoming and outgoing edges.
[4] Activity parameter object nodes with no incoming edges and one or more outgoing edges must have a parameter with in or inout direction.
[5] Activity parameter object nodes with no outgoing edges and one or more incoming edges must have a parameter with out, inout, or return direction.
[6] A parameter with direction other than inout must have at most one activity parameter node in an activity.
[7] A parameter with direction inout must have at most two activity parameter nodes in an activity, one with incoming flows and one with outgoing flows.
See “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319.
Semantics As a kind of behavior, an activity may have owned parameters. Within the activity, in and inout parameters may be associated with activity parameter nodes that have no incoming edges—they provide a source within the activity for the overall “input values” of the activity. Similarly, inout, out, and return parameters may be associated with activity nodes that have no outgoing edges—they provide a sink within the activity for the overall “output values” of the activity.
Per the general semantics of a behavior, when the activity is invoked, its in and inout parameters may be given actual values. These input values are placed as tokens on those activity parameter nodes within the activity that are associated with the corresponding in and inout parameters, the ones which do not have incoming edges. The overall activity input values are then available within the activity via the outgoing edges of the activity parameter nodes. During the course of execution of the activity, tokens may flow into those activity parameter nodes within the activity that have incoming edges. When the execution of the activity completes, the output values held by these activity parameter nodes are given to the corresponding inout, out, and return parameters of the activity. If the parameter associated with an activity parameter node is marked as streaming, then the above semantics are extended to allow for inputs to arrive and outputs to be posted during the execution of the activity (see the semantics for Parameter). In this case, for an activity parameter node with no incoming edges, an input value is placed on the activity parameter node whenever an input arrives on the corresponding streaming in or inout parameter. For an activity parameter node with no outgoing edges, an output value is posted on the corresponding inout, out or return parameter whenever a token arrives at the activity parameter node.
A central buffer node is an object node for managing flows from multiple sources and destinations.
Description A central buffer node accepts tokens from upstream object nodes and passes them along to downstream object nodes. They act as a buffer for multiple in flows and out flows from other object nodes. They do not connect directly to actions.
Semantics See semantics at ObjectNode. All object nodes have buffer functionality, but central buffers differ in that they are not tied to an action as pins are, or to an activity as activity parameter nodes are. See example below.
Description An expansion node is an object node used to indicate a flow across the boundary of an expansion region. A flow into a region contains a collection that is broken into its individual elements inside the region, which is executed once per element. A flow out of a region combines individual elements into a collection for use outside the region.
Semantics See “ExpansionRegion (from ExtraStructuredActivities).”
Description A pin is a typed element and multiplicity element that provides values to actions and accepts result values from them.
Semantics
A pin represents an input to an action or an output from an action. The definition on an action assumes that pins are ordered. Pin multiplicity controls action execution, not the number of tokens in the pin (see upperBound on “ObjectNode (from BasicActivities, CompleteActivities)” on page 405). See “InputPin (from BasicActions)” and “OutputPin (from BasicActions)” for semantics of multiplicity. Pin multiplicity is not unique, because multiple tokens with the same value can reside in an object node.
Description A typed element is an element that has a type that serves as a constraint on the range of values the element can represent. Typed element is an abstract metaclass.
Semantics Values represented by the element are constrained to be instances of the type. A typed element with no associated type may represent values of any type.
A decision node is a control node that chooses between outgoing flows.
Description A decision node accepts tokens on an incoming edge and presents them to multiple outgoing edges. Which of the edges is actually traversed depends on the evaluation of the guards on the outgoing edges.
Semantics Each token arriving at a decision node can traverse only one outgoing edge. Tokens are not duplicated. Each token offered by the incoming edge is offered to the outgoing edges. Most commonly, guards of the outgoing edges are evaluated to determine which edge should be traversed. The order in which guards are evaluated is not defined, because edges in general are not required to determine which tokens they accept in any particular order. The modeler should arrange that each token only be chosen to traverse one outgoing edge; otherwise, there will be race conditions among the outgoing edges. If the implementation can ensure that only one guard will succeed, it is not required to evaluate all guards when one is found that does. For decision points, a predefined guard “else” may be defined for at most one outgoing edge. This guard succeeds for a token only if the token is not accepted by all the other edges outgoing from the decision point. Notice that the semantics only requires that the token traverse one edge, rather than be offered to only one edge. Multiple edges may be offered the token, but if only one of them has a target that accepts the token, then that edge is traversed. If multiple edges accept the token and have approval from their targets for traversal at the same time, then the semantics is not defined. If a decision input behavior is specified, then each data token is passed to the behavior before guards are evaluated on the outgoing edges. The behavior is invoked without input for control tokens. The output of the behavior is available to the guard. Because the behavior is used during the process of offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. It may not modify objects, but it may for example, navigate from one object to another or get an attribute value from an object. If there is a decision input flow, but no decision input behavior, then it is the tokens offered on the decision input flow that are made available to the guard on each outgoing edge to determine whether the offer on the regular incoming edge is passed along that outgoing edge. If there is a decision input behavior and a decision input flow, the token offered on the decision input flow is passed to the behavior (as the only argument if the regular incoming edge is control flow, as the second argument if it is an object flow). Decision nodes with the additional decision input flow offer tokens to outgoing edges only when one token is offered on each incoming edge.
A final node is an abstract control node at which a flow in an activity stops.
Description See descriptions at children of final node.
Semantics All tokens offered on incoming edges are accepted. See children of final node for other semantics.
Description A fork node has one incoming edge and multiple outgoing edges.
Semantics Tokens that arrive at a fork node are duplicated across the outgoing edges of the node. Specifically, tokens offered to a fork node are offered to all outgoing edges of the node. If at least one of these offers is accepted, the offered tokens are removed from their source and a copy of the tokens traverse each edge for which the offer was accepted.
Any offer that was not accepted on an outgoing edge due to the failure of the target to accept it remains pending on that edge and may be accepted by the target at a later time. These edges effectively accept a separate copy of the offered tokens, and offers made to the edges stand to their targets in the order in which they were accepted by the edge (first in, first out). This is an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream (see “Activity (from BasicActivities, CompleteActivities, FundamentalActivities, StructuredActivities)” on page 324). Note that any outgoing edges that fail to accept an offer due to the failure of a guard do not receive copies of those tokens. If guards are used on edges outgoing from forks, the modelers should ensure that no downstream joins depend on the arrival of tokens passing through the guarded edge. If that cannot be avoided, then a decision node should be introduced to have the guard, and shunt the token to the downstream join if the guard fails. See example in Figure 12.44 on page 338.
Description An activity may have more than one initial node.
Semantics An initial node is a starting point for executing an activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). A control token is placed at the initial node when the activity starts, but not in initial nodes in structured nodes contained by the activity. Tokens in an initial node are offered to all outgoing edges. If an activity has more than one initial node, then invoking the activity starts multiple flows, one at each initial node. For convenience, initial nodes are an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream, for example, by guards (see Activity). This is equivalent to interposing a CentralBufferNode between the initial node and its outgoing edges. Note that flows can also start at other nodes, see ActivityParameterNode and AcceptEventAction, so initial nodes are not required for an activity to start execution. In addition, when an activity starts, a control token is placed at each action or structured node that has no incoming edges, except if it is a handler body (see “ExceptionHandler (from ExtraStructuredActivities)” on page 373, it is the fromAction of an action input pin (see “ActionInputPin (as specialized)” on page 323), or it is contained in a structured node.
Description A join node has multiple incoming edges and one outgoing edge.
Package CompleteActivities Join nodes have a Boolean value specification using the names of the incoming edges to specify the conditions under which the join will emit a token.
Semantics If there is a token offered on all incoming edges, then tokens are offered on the outgoing edge according to the following join rules:
1. If all the tokens offered on the incoming edges are control tokens, then one control token is offered on the outgoing edge.
2. If some of the tokens offered on the incoming edges are control tokens and others are data tokens, then only the data tokens are offered on the outgoing edge. Tokens are offered on the outgoing edge in the same order they were offered to the join.
Multiple control tokens offered on the same incoming edge are combined into one before applying the above rules. No joining of tokens is necessary if there is only one incoming edge, but it is not a useful case.
Package CompleteActivities The reserved string “and” used as a join specification is equivalent to a specification that requires at least one token offered on each incoming edge. It is the default. The join specification is evaluated whenever a new token is offered on any incoming edge. The evaluation is not interrupted by any new tokens offered during the evaluation, nor are concurrent evaluations started when new tokens are offered during an evaluation. If any tokens are offered to the outgoing edge, they must be accepted or rejected for traversal before any more tokens are offered to the outgoing edge. If tokens are rejected for traversal, they are no longer offered to the outgoing edge. The join specification may contain the names of the incoming edges to refer to whether a token was offered on that edge at the time the evaluation started. If isCombinedDuplicate is true, then before object tokens are offered to the outgoing edge, those containing objects with the same identity are combined into one token.
A merge node is a control node that brings together multiple alternate flows. It is not used to synchronize concurrent flows but to accept one among several alternate flows.
Description A merge node has multiple incoming edges and a single outgoing edge.
Semantics All tokens offered on incoming edges are offered to the outgoing edge. There is no synchronization of flows or joining of tokens.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
A data store keeps all tokens that enter it, copying them when they are chosen to move downstream. Incoming tokens containing a particular object replace any tokens in the object node containing that object.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
An activity final node is a final node that stops all flows in an activity.
Description An activity may have more than one activity final node. The first one reached stops all flows in the activity.
Semantics A token reaching an activity final node terminates the activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). In particular, it stops all executing actions in the activity, and destroys all tokens in object nodes, except in the output activity parameter nodes. Terminating the execution of synchronous invocation actions also terminates whatever behaviors they are waiting on for return. Any behaviors invoked asynchronously by the activity are not affected. All tokens offered on the incoming edges are accepted. The content of output activity parameter nodes are passed out of the containing activity, using the null token for object nodes that have nothing in them. If there is more than one final node in an activity, the first one reached terminates the activity, including the flow going towards the other activity final.
If it is not desired to abort all flows in the activity, use flow final instead. For example, if the same execution of an activity is being used for all its invocations, then multiple streams of tokens will be flowing through the same activity. In this case, it is probably not desired to abort all tokens just because one reaches an activity final. Using a flow final will simply consume the tokens reaching it without aborting other flows. Or arrange for separate invocations of the activity to use separate executions of the activity, so tokens from separate invocations will not affect each other.
A flow final node is a final node that terminates a flow.
Description A flow final destroys all tokens that arrive at it. It has no effect on other flows in the activity.
Semantics Flow final destroys tokens flowing into it.
Description A pin is a typed element and multiplicity element that provides values to actions and accepts result values from them.
Semantics
A pin represents an input to an action or an output from an action. The definition on an action assumes that pins are ordered. Pin multiplicity controls action execution, not the number of tokens in the pin (see upperBound on “ObjectNode (from BasicActivities, CompleteActivities)” on page 405). See “InputPin (from BasicActions)” and “OutputPin (from BasicActions)” for semantics of multiplicity. Pin multiplicity is not unique, because multiple tokens with the same value can reside in an object node.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description An object node is an activity node that indicates an instance of a particular classifier, possibly in a particular state, may be available at a particular point in the activity. Object nodes can be used in a variety of ways, depending on where objects are flowing from and to, as described in the semantics sub clause.
Package CompleteActivities Complete object nodes add support for token selection, limitation on the number of tokens, specifying the state required for tokens, and carrying control values.
Constraints Package BasicActivities
[1] All edges coming into or going out of object nodes must be object flow edges.
Package CompleteActivities
[1] If an object node has a selection behavior, then the ordering of the object node is ordered and vice versa.
[2] A selection behavior has one input parameter and one output parameter. The input parameter must be a bag of elements of the same type as the object node or a supertype of the type of object node. The output parameter must be the same or a subtype of the type of object node. The behavior cannot have side effects.
Semantics Object nodes may only contain values at runtime that conform to the type of the object node, in the state or states specified, if any. If no type is specified, then the values may be of any type. Multiple tokens containing the same value may reside in the object node at the same time. This includes data values. A token in an object node can traverse only one of the outgoing edges. An object node may indicate that its type is to be treated as a control value, even if no type is specified for the node. Control edges may be used with the object node having control type.
Package CompleteActivities An object node may not contain more tokens than its upper bound. The upper bound must be a LiteralUnlimitedNatural. An upper bound of * means the upper bound is unlimited. See ObjectFlow for additional rules regarding when objects may traverse the edges incoming and outgoing from an object node.The ordering of an object node specifies the order in which tokens in the node are offered to the outgoing edges. This can be set to require that tokens do not overtake each other as they pass through the node (FIFO), or that they do (LIFO or modeler-defined ordering). Modeler-defined ordering is indicated by an ordering value of ordered, and a selection behavior that determines what token to offer to the edges. The selection behavior takes all the tokens in the object node as input and chooses a single token from those. It is executed whenever a token is to be offered to an edge. Because the behavior is used while offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. The selection behavior of an object node is overridden by any selection behaviors on its outgoing edges (see “ObjectFlow”). Overtaking due to ordering is distinguished from the case where each invocation of the activity is handled by a separate execution of the activity. In this case, the tokens have no interaction with each other, because they flow through separate executions of the activity (see “Activity”).
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
Description A typed element is an element that has a type that serves as a constraint on the range of values the element can represent. Typed element is an abstract metaclass.
Semantics Values represented by the element are constrained to be instances of the type. A typed element with no associated type may represent values of any type.
An action input pin is a kind of pin that executes an action to determine the values to input to another.
Semantics
If an action is otherwise enabled, the fromActions on action input pins are enabled. The outputs of these are used as the values of the corresponding input pins. The process recurs on the input pins of the fromActions, if they also have action input pins. The recursion bottoms out at actions that have no inputs, such as for read variables or the self object. This forms a tree that is an action model for nested expressions.
Description A value pin is an input pin that provides a value by evaluating a value specification.
Semantics The value of the pin is the result of evaluating the value specification.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description A type constrains the values represented by a typed element.
Semantics A type serves as a constraint on the range of values represented by a typed element. Type is an abstract metaclass.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
QualifierValue is not an action. It is an element that identifies links. It gives a single qualifier within a link end data specification. See LinkEndData.
Description A link cannot be passed as a runtime value to or from an action. Instead, a link is identified by its end objects and qualifier values, as required. This requires more than one piece of data, namely, the end in the user model, the object on the end, and the qualifier values for that end. These pieces are brought together around LinkEndData. Each association end is identified separately with an instance of the LinkEndData class.
Semantics See LinkAction and its children.
Rationale QualifierValue is introduced to indicate which inputs are for which link end qualifiers.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
An Association specifies a semantic relationship that can occur between typed instances. It has at least two memberEnds represented by Properties, each of which has the type of the end. More than one end of the Association may have the same type.
An Association declares that there can be links between instances of the associated types. A link is a tuple with one value for each memberEnd of the Association, where each value is an instance of the type of the end.
Not all links need to be classified by an Association.
When one or more ends of the Association have isUnique=false, it is possible to have several links associating the same set of instances. In such a case, links carry an additional identifier apart from their end values.
When one or more ends of the Association are ordered, links carry ordering information in addition to their end values.
For an Association with N memberEnds, choose any N-1 ends and associate specific instances with those ends. Then the collection of links of the Association that refer to these specific instances will identify a collection of instances at the other end. The multiplicity of the other end constrains the size of this collection. If the other end is marked as isOrdered, this collection will be ordered. If the other end is marked as isUnique, this collection is a set; otherwise, it allows duplicate elements.
Subsetting represents the familiar set-theoretic concept. It applies to the collections represented by Association ends, not to the Association itself. It means that the subsetting Association end represents a collection that is either equal to or a proper subset of the collection that it is subsetting. Subsetting is a relationship in the domain of extensional semantics.
Specialization is, in contrast to subsetting, a relationship in the domain of intentional semantics, which is to say it characterizes the criteria whereby membership in the collection is defined, not by the membership. In the case of Associations, specialization means that a link classified by the specializing association is also classified by the specialized association. Semantically this implies that the collections representing the ends of the specializing association are subsets of the corresponding collections representing the ends of the specialized association; this fact of subsetting may or may not be explicitly declared in a model.
Note – For n-ary Associations, the lower multiplicity of an end is typically 0. A lower multiplicity for an end of an n-ary Association of 1 (or more) implies that one link (or more) must exist for every possible combination of values for the other ends.
A binary Association may represent a composite aggregation (i.e., a whole/part relationship). Composition is represented by the isComposite attribute on the part end of the Association being set to true. See the semantics of composition in 9.5.3.
An end Property of an Association that is owned by an end Class or that is a navigableOwnedEnd of the Association indicates that the Association is navigable from the opposite ends; otherwise, the Association is not navigable from the opposite ends. Navigability means that instances participating in links at runtime (instances of an Association) can be accessed efficiently from instances at the other ends of the Association. The precise mechanism by which such efficient access is achieved is implementation specific. If an end is not navigable, access from the other ends may or may not be possible, and if it is, it might not be efficient. Note that tools operating on UML models are not prevented from navigating Associations from non-navigable ends.
The existence of an association may be derived from other information in the model. The logical relationship between the derivation of an Association and the derivation of its ends is model-specific.
BehavioredClassifier (from Interfaces) Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
Description A type constrains the values represented by a typed element.
Semantics A type serves as a constraint on the range of values represented by a typed element. Type is an abstract metaclass.
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
BehavioredClassifier (from Interfaces) Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Description
An interaction is a unit of behavior that focuses on the observable exchange of information between ConnectableElements. An Interaction is a specialization of InteractionFragment and of Behavior.
Semantics
Interactions are units of behavior of an enclosing Classifier. Interactions focus on the passing of information with Messages between the ConnectableElements of the Classifier. The semantics of an Interaction is given as a pair of sets of traces. The two trace sets represent valid traces and invalid traces. The union of these two sets need not necessarily cover the whole universe of traces. The traces that are not included are not described by this Interaction at all, and we cannot know whether they are valid or invalid. A trace is a sequence of event occurrences, each of which is described by an OccurrenceSpecification in a model. The semantics of Interactions are compositional in the sense that the semantics of an Interaction is mechanically built from the semantics of its constituent InteractionFragments. The constituent InteractionFragments are ordered and combined by the seq operation (weak sequencing) as explained in “Weak Sequencing” on page 483. The invalid set of traces are associated only with the use of a Negative CombinedInteraction. For simplicity we describe only valid traces for all other constructs.
those of the original. The traces defined by the specialization is combined with those of the inherited Interaction with a union. The classifier owning an Interaction may be specialized, and in the specialization the Interaction may be redefined. Redefining an Interaction simply means to exchange the redefining Interaction for the redefined one, and this exchange takes effect also for InteractionUses within the supertype of the owner. This is similar to redefinition of other kinds of Behavior.
Basic trace model: The semantics of an Interaction is given by a pair [P, I] where P is the set of valid traces and I is the set of invalid traces. need not be the whole universe of traces. A trace is a sequence of event occurrences denoted <e1, e2, ... , en>. An event occurrence will also include information about the values of all relevant objects at this point in time. Each construct of Interactions (such as CombinedFragments of different kinds) are expressed in terms of how it relates to a pair of sets of traces. For simplicity we normally refer only to the set of valid traces as these traces are those mostly modeled. Two Interactions are equivalent if their pair of trace-sets are equal.
Relation of trace model to execution model: In Chapter 13, “Common Behaviors” we find an Execution model, and this is how the Interactions Trace Model relates to the Execution model. An Interaction is an Emergent Behavior. An InvocationOccurrence in the Execution model corresponds with an (event) Occurrence in a trace. Occurrences are modeled in an Interaction by OccurrenceSpecifications. Normally in Interaction the action leading to the invocation as such is not described (such as the sending action). However, if it is desirable to go into details, a Behavior (such as an Activity) may be associated with an OccurrenceSpecification. An occurrence in Interactions is normally interpreted to take zero time. Duration is always between occurrences. Likewise a ReceiveOccurrence in the Execution model is modeled by an OccurrenceSpecification. Similarly the detailed actions following immediately from this reception are often omitted in Interactions, but may also be described explicitly with a Behavior associated with that OccurrenceSpecification. A Request in the Execution model is modeled by the Message in Interactions. An Execution in the Execution model is modeled by an ExecutionSpecification in Interactions. An Execution is defined in the trace by two Occurrences, one at the start and one at the end. This corresponds to the StartOccurrence and the CompletionOccurrence of the Execution model.
Specifies the occurrence of events, such as sending and receiving of signals or invoking or receiving of operation calls. A message occurrence specification is a kind of message end. Messages are generated either by synchronous operation calls or asynchronous signal sends. They are received by the execution of corresponding accept event actions.
A MessageEnd is an abstract NamedElement that represents what can occur at the end of a Message.
Semantics
Subclasses of MessageEnd define the specific semantics appropriate to the concept they represent.
A lifeline represents an individual participant in the Interaction. While Parts and StructuralFeatures may have multiplicity greater than 1, Lifelines represent only one interacting entity. Lifeline is a specialization of NamedElement. If the referenced ConnectableElement is multivalued (i.e, has a multiplicity > 1), then the Lifeline may have an expression (the ‘selector’) that specifies which particular part is represented by this Lifeline. If the selector is omitted, this means that an arbitrary representative of the multivalued ConnectableElement is chosen.
Semantics
The order of OccurrenceSpecifications along a Lifeline is significant denoting the order in which these OccurrenceSpecifications will occur. The absolute distances between the OccurrenceSpecifications on the Lifeline are, however, irrelevant for the semantics. The semantics of the Lifeline (within an Interaction) is the semantics of the Interaction selecting only OccurrenceSpecifications of this Lifeline.
The connector concept is extended in the Components package to include contracts and notation. A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling. An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts. Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only). A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
An OccurrenceSpecification is the basic semantic unit of Interactions. The sequences of occurrences specified by them are the meanings of Interactions. OccurrenceSpecifications are ordered along a Lifeline. The namespace of an OccurrenceSpecification is the Interaction in which it is contained.
A GeneralOrdering represents a binary relation between two OccurrenceSpecifications, to describe that one OccurrenceSpecification must occur before the other in a valid trace. This mechanism provides the ability to define partial orders of OccurrenceSpecifications that may otherwise not have a specified order.
A GeneralOrdering is a specialization of NamedElement.
A GeneralOrdering may appear anywhere in an Interaction, but only between OccurrenceSpecifications.
Description
A combined fragment defines an expression of interaction fragments. A combined fragment is defined by an interaction operator and corresponding interaction operands. Through the use of CombinedFragments the user will be able to describe a number of traces in a compact and concise manner. CombinedFragment is a specialization of InteractionFragment.
Semantics
The semantics of a CombinedFragment is dependent upon the interactionOperator as explained below.
Alternatives The interactionOperator alt designates that the CombinedFragment represents a choice of behavior. At most one of the operands will be chosen. The chosen operand must have an explicit or implicit guard expression that evaluates to true at this point in the interaction. An implicit true guard is implied if the operand has no guard. The set of traces that defines a choice is the union of the (guarded) traces of the operands. An operand guarded by else designates a guard that is the negation of the disjunction of all other guards in the enclosing CombinedFragment. If none of the operands has a guard that evaluates to true, none of the operands are executed and the remainder of the enclosing InteractionFragment is executed.
Option The interactionOperator opt designates that the CombinedFragment represents a choice of behavior where either the (sole) operand happens or nothing happens. An option is semantically equivalent to an alternative CombinedFragment where there is one operand with non-empty content and the second operand is empty.
Break The interactionOperator break designates that the CombinedFragment represents a breaking scenario in the sense that the operand is a scenario that is performed instead of the remainder of the enclosing InteractionFragment. A break operator with a guard is chosen when the guard is true and the rest of the enclosing Interaction Fragment is ignored. When the guard of the break operand is false, the break operand is ignored and the rest of the enclosing InteractionFragment is chosen. The choice between a break operand without a guard and the rest of the enclosing InteractionFragment is done non-deterministically. A CombinedFragment with interactionOperator break should cover all Lifelines of the enclosing InteractionFragment.
Parallel The interactionOperator par designates that the CombinedFragment represents a parallel merge between the behaviors of the operands. The OccurrenceSpecifications of the different operands can be interleaved in any way as long as the ordering imposed by each operand as such is preserved. A parallel merge defines a set of traces that describes all the ways that OccurrenceSpecifications of the operands may be interleaved without obstructing the order of the OccurrenceSpecifications within the operand.
Weak Sequencing The interactionOperator seq designates that the CombinedFragment represents a weak sequencing between the behaviors of the operands. Weak sequencing is defined by the set of traces with these properties:
The ordering of OccurrenceSpecifications within each of the operands are maintained in the result.
OccurrenceSpecifications on different lifelines from different operands may come in any order.
OccurrenceSpecifications on the same lifeline from different operands are ordered such that an OccurrenceSpecification of the first operand comes before that of the second operand.
Thus weak sequencing reduces to a parallel merge when the operands are on disjunct sets of participants. Weak sequencing reduces to strict sequencing when the operands work on only one participant.
Strict Sequencing The interactionOperator strict designates that the CombinedFragment represents a strict sequencing between the behaviors of the operands. The semantics of strict sequencing defines a strict ordering of the operands on the first level within the CombinedFragment with interactionOperator strict. Therefore OccurrenceSpecifications within contained CombinedFragment will not directly be compared with other OccurrenceSpecifications of the enclosing CombinedFragment.
Negative The interactionOperator neg designates that the CombinedFragment represents traces that are defined to be invalid. The set of traces that defined a CombinedFragment with interactionOperator negative is equal to the set of traces given by its (sole) operand, only that this set is a set of invalid rather than valid traces. All InteractionFragments that are different from Negative are considered positive meaning that they describe traces that are valid and should be possible.
Critical Region The interactionOperator critical designates that the CombinedFragment represents a critical region. A critical region means that the traces of the region cannot be interleaved by other OccurrenceSpecifications (on those Lifelines covered by the region). This means that the region is treated atomically by the enclosing fragment when determining the set of valid traces. Even though enclosing CombinedFragments may imply that some OccurrenceSpecifications may interleave into the region, such as with par-operator, this is prevented by defining a region. Thus the set of traces of enclosing constructs are restricted by critical regions.
Ignore / Consider See the semantics of 14.3.4, “ConsiderIgnoreFragment (from Fragments),” on page 488.
Assertion The interactionOperator assert designates that the CombinedFragment represents an assertion. The sequences of the operand of the assertion are the only valid continuations. All other continuations result in an invalid trace. Assertions are often combined with Ignore or Consider as shown in Figure 14.24.
Loop The interactionOperator loop designates that the CombinedFragment represents a loop. The loop operand will be repeated a number of times. The Guard may include a lower and an upper number of iterations of the loop as well as a Boolean expression. The semantics is such that a loop will iterate minimum the ‘minint’ number of times (given by the iteration expression in the guard) and at most the ‘maxint’ number of times. After the minimum number of iterations have executed and the Boolean expression is false the loop will terminate. The loop construct represents a recursive application of the seq operator where the loop operand is sequenced after the result of earlier iterations.
486 UML Superstructure Specification, v2.4 If the loop contains a separate InteractionConstraint with a specification, the loop will only continue if that specification evaluates to true during execution regardless of the minimum number of iterations specified in the loop.
The Semantics of Gates (see also “Gate (from Fragments)” on page 494) The gates of a CombinedFragment represent the syntactic interface between the CombinedFragment and its surroundings, which means the interface towards other InteractionFragments. The only purpose of gates is to define the source and the target of Messages.
A Deployment captures the relationship between a particular conceptual or physical element of a modeled system and the information assets assigned to it. System elements are represented as DeployedTargets, and information assets, as DeployedArtifacts. DeploymentTargets and DeploymentArtifacts are abstract classes that cannot be directly instantiated. They are, however, elaborated as concrete classes as described in the Artifacts and Nodes subclauses that follow.
Individual Deployment relationships can be tailored for specific uses by adding DeploymentSpecifications containing configurational and/or parametric information and may be extended in specific component profiles. For example, standard, non-normative stereotypes that a profile might add to DeploymentSpecification include «concurrencyMode», with tagged values {thread, process, none}, and «transactionMode», with tagged values {transaction, nestedTransaction, none}.
DeploymentSpecification information becomes execution-time input to components associated with DeploymentTargets via their deployedElements links. Using these links, DeploymentSpecifications can be targeted at specific container types, as long as the containers are kinds of Components. As shown in Figure 19-1, DeploymentSpecifications can be captured as elements of the Deployment relationships because they are Artifacts (described in the following subclause). Furthermore, 702
DeploymentSpecifications can only be associated with DeploymentTargets that are ExecutionEnvironments (described in the Nodes subclause, below).
The Deployment relationship between a DeployedArtifact and a DeploymentTarget can be defined at the “type” level and at the “instance” level. At the “type” level, the Deployment connects kinds of DeploymentTargets to kinds of DeployedArtifacts. Whereas, at the “instance” level, the Deployment connects particular DeploymentTargets instances to particular DeployedArtifacts instances. For example, a ”type” level Deployment might connect an “application server” with an “order entry request handler.” In contrast, at the ”instance” level, three specific application services (say, “app-server1”, “app-server-2” and “app-server3”) may be the DeploymentTargets for six different “request handler” instances.
For modeling complex models consisting of composite structures, a Property, functioning as a part (i.e., owned by a composition), may be the target of a Deployment. Likewise, InstanceSpecifications can be DeploymentTargets in a Deployment relationship, if they represent a Node that functions as a part within an encompassing Node composition hierarchy, or if they represent an Artifact.
Operation (from Kernel, Interfaces) Description An operation is a behavioral feature of a classifier that specifies the name, type, parameters, and constraints for invoking an associated behavior.
Semantics An operation is invoked on an instance of the classifier for which the operation is a feature.
The preconditions for an operation define conditions that must be true when the operation is invoked. These preconditions may be assumed by an implementation of this operation. The postconditions for an operation define conditions that will be true when the invocation of the operation completes successfully, assuming the preconditions were satisfied. These postconditions must be satisfied by any implementation of the operation. The bodyCondition for an operation constrains the return result. The bodyCondition differs from postconditions in that the bodyCondition may be overridden when an operation is redefined, whereas postconditions can only be added during redefinition. An operation may raise an exception during its invocation. When an exception is raised, it should not be assumed that the postconditions or bodyCondition of the operation are satisfied. An operation may be redefined in a specialization of the featured classifier. This redefinition may specialize the types of the owned parameters, add new preconditions or postconditions, add new raised exceptions, or otherwise refine the specification of the operation. Each operation states whether or not its application will modify the state of the instance or any other element in the model (isQuery). An operation may be owned by and in the namespace of a class that provides the context for its possible redefinition. Semantic Variation Points The behavior of an invocation of an operation when a precondition is not satisfied is a semantic variation point. When operations are redefined in a specialization, rules regarding invariance, covariance, or contravariance of types and preconditions determine whether the specialized classifier is substitutable for its more general parent. Such rules constitute semantic variation points with respect to redefinition of operations.
Operation (from Communications) Description An operation may invoke both the execution of method behaviors as well as other behavioral responses. Semantics If an operation is not mentioned in a trigger of a behavior owned or inherited by the behaviored classifier owning the operation, then upon occurrence of a call event (representing the receipt of a request for the invocation of this operation) a resolution process is performed that determines the method behavior to be invoked, based on the operation and the data values corresponding to the parameters of the operation transmitted by the request; otherwise, the call event is placed into the input pool of the object (see BehavioredClassifier on page 449). If a behavior is triggered by this event, it begins with performing the resolution process and invoking the so determined method. Then the behavior continues its execution as specified. Operations specify immediate or triggered effects (see “BehavioredClassifier” )
Semantic Variation Points Resolution specifies how a particular behavior is identified to be executed in response to the invocation of an operation, using mechanisms such as inheritance. The mechanism by which the behavior to be invoked is determined from an operation and the transmitted argument data is a semantic variation point. In general, this mechanism may be complicated to include languages with features such as before-after methods, delegation, etc. In some of these variations, multiple behaviors may be executed as a result of a single call. The following defines a simple object-oriented process for this semantic variation point. • Object-oriented resolution When a call request is received, the class of the target object is examined for an owned operation with matching parameters (see “BehavioralFeature” on page 448). If such operation is found, the behavior associated as method is the result of the resolution; otherwise, the parent classifier is examined for a matching operation, and so on up the generalization hierarchy until a method is found or the root of the hierarchy is reached. If a class has multiple parents, all of them are examined for a method. If a method is found in exactly one ancestor class, then that method is the result of the resolution. If a method is found in more than one ancestor class along different paths, then the model is ill-formed under this semantic variation. If no method by the resolution process, then it is a semantic variation point what is to happen.
The connector concept is extended in the Components package to include contracts and notation. A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling. An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts. Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only). A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Classifier (from Kernel, Dependencies, PowerTypes, Interfaces) Description A classifier is a namespace whose members can include features. Classifier is an abstract metaclass. A classifier is a type and can own generalizations, thereby making it possible to define generalization relationships to other classifiers. A classifier can specify a generalization hierarchy by referencing its general classifiers. A classifier is a redefinable element, meaning that it is possible to redefine nested classifiers.
Semantics A classifier is a classification of instances according to their features. A Classifier may participate in generalization relationships with other Classifiers. An instance of a specific Classifier is also an (indirect) instance of each of the general Classifiers. Therefore, features specified for instances of the general classifier are implicitly specified for instances of the specific classifier. Any constraint applying to instances of the general classifier also applies to instances of the specific classifier. The specific semantics of how generalization affects each concrete subtype of Classifier varies. All instances of a classifier have values corresponding to the classifier’s attributes. A Classifier defines a type. Type conformance between generalizable Classifiers is defined so that a Classifier conforms to itself and to all of its ancestors in the generalization hierarchy.
Package PowerTypes The notion of power type was inspired by the notion of power set. A power set is defined as a set whose instances are subsets. In essence, then, a power type is a class whose instances are subclasses. The powertypeExtent association relates a Classifier with a set of generalizations that a) have a common specific Classifier, and b) represent a collection of subsets for that class.
Semantic Variation Points The precise lifecycle semantics of aggregation is a semantic variation point.
Classifier (from InternalStructures, Collaborations) Description Package Collaborations Classifier is extended with the capability to own collaboration uses. The collaboration uses link a collaboration with the classifier to give a description of the workings of the classifier.
Semantics A classifier can own collaboration uses that relate (aspects of) this classifier to a collaboration. The collaboration describes those aspects of this classifier. One of the collaboration uses owned by a classifier may be singled out as representing the behavior of the classifier as a whole. The collaboration that is related to the classifier by this collaboration use shows how the instances corresponding to the structural features of this classifier (e.g., its attributes and parts) interact to generate the overall behavior of the classifier. The representing collaboration may be used to provide a description of the behavior of the classifier at a different level of abstraction than is offered by the internal structure of the classifier. The properties of the classifier are mapped to roles in the collaboration by the role bindings of the collaboration use.
Classifier (from UseCases) Description Extends a classifier with the capability to own use cases. Although the owning classifier typically represents the subject to which the owned use cases apply, this is not necessarily the case. In principle, the same use case can be applied to multiple subjects, as identified by the subject association role of a UseCase (see “UseCase (from UseCases)” ).
Semantics See “UseCase (from UseCases)” .
Description A state machine owns one or more regions, which in turn own vertices and transitions. The behaviored classifier context owning a state machine defines which signal and call triggers are defined for the state machine, and which attributes and operations are available in activities of the state machine. Signal triggers and call triggers for the state machine are defined according to the receptions and operations of this classifier. As a kind of behavior, a state machine may have an associated behavioral feature (specification) and be the method of this behavioral feature. In this case the state machine specifies the behavior of this behavioral feature. The parameters of the state machine in this case match the parameters of the behavioral feature and provide the means for accessing (within the state machine) the behavioral feature parameters. A state machine without a context classifier may use triggers that are independent of receptions or operations of a classifier, i.e., either just signal triggers or call triggers based upon operation template parameters of the (parameterized) statemachine.
Semantics The event pool for the state machine is the event pool of the instance according to the behaviored context classifier, or the classifier owning the behavioral feature for which the state machine is a method. Event processing - run-to-completion step Event occurrences are detected, dispatched, and then processed by the state machine, one at a time. The order of dequeuing is not defined, leaving open the possibility of modeling different priority-based schemes. The semantics of event occurrence processing is based on the run-to-completion assumption, interpreted as run-to-completion processing. Run-to-completion processing means that an event occurrence can only be taken from the pool and dispatched if the processing of the previous current occurrence is fully completed. Run-to-completion may be implemented in various ways. For active classes, it may be realized by an event-loop running in its own thread, and that reads event occurrences from a pool. For passive classes it may be implemented as a monitor. The processing of a single event occurrence by a state machine is known as a run-to-completion step. Before commencing on a run-to-completion step, a state machine is in a stable state configuration with all entry/exit/internal activities (but not necessarily state (do) activities) completed. The same conditions apply after the run-to-completion step is completed. Thus, an event occurrence will never be processed while the state machine is in some intermediate and inconsistent situation. The run-to-completion step is the passage between two state configurations of the state machine. The run-to-completion assumption simplifies the transition function of the state machine, since concurrency conflicts are avoided during the processing of event, allowing the state machine to safely complete its run-to-completion step.
When an event occurrence is detected and dispatched, it may result in one or more transitions being enabled for firing. If no transition is enabled and the event (type) is not in the deferred event list of the current state configuration, the event occurrence is discarded and the run-to-completion step is completed. In the presence of orthogonal regions it is possible to fire multiple transitions as a result of the same event occurrence — as many as one transition in each region in the current state configuration. In case where one or more transitions are enabled, the state machine selects a subset and fires them. Which of the enabled transitions actually fire is determined by the transition selection algorithm described below. The order in which selected transitions fire is not defined. Each orthogonal region in the active state configuration that is not decomposed into orthogonal regions (i.e., “bottom-level” region) can fire at most one transition as a result of the current event occurrence. When all orthogonal regions have finished executing the transition, the current event occurrence is fully consumed, and the run-to-completion step is completed. During a transition, a number of actions may be executed. If such an action is a synchronous operation invocation on an object executing a state machine, then the transition step is not completed until the invoked object completes its run-to-completion step.
Run-to-completion and concurrency It is possible to define state machine semantics by allowing the run-to-completion steps to be applied orthogonally to the orthogonal regions of a composite state, rather than to the whole state machine. This would allow the event serialization constraint to be relaxed. However, such semantics are quite subtle and difficult to implement. Therefore, the dynamic semantics defined in this document are based on the premise that a single run-to-completion step applies to the entire state machine and includes the steps taken by orthogonal regions in the active state configuration. In case of active objects, where each object has its own thread of execution, it is very important to clearly distinguish the notion of run to completion from the concept of thread pre-emption. Namely, run-to-completion event handling is performed by a thread that, in principle, can be pre-empted and its execution suspended in favor of another thread executing on the same processing node. (This is determined by the scheduling policy of the underlying thread environment — no assumptions are made about this policy.) When the suspended thread is assigned processor time again, it resumes its event processing from the point of pre-emption and, eventually, completes its event processing.
Conflicting transitions It was already noted that it is possible for more than one transition to be enabled within a state machine. If that happens, then such transitions may be in conflict with each other. For example, consider the case of two transitions originating from the same state, triggered by the same event, but with different guards. If that event occurs and both guard conditions are true, then only one transition will fire. In other words, in case of conflicting transitions, only one of them will fire in a single run-to-completion step. Two transitions are said to conflict if they both exit the same state, or, more precisely, that the intersection of the set of states they exit is non-empty. Only transitions that occur in mutually orthogonal regions may be fired simultaneously. This constraint guarantees that the new active state configuration resulting from executing the set of transitions is well-formed. An internal transition in a state conflicts only with transitions that cause an exit from that state.
Firing priorities In situations where there are conflicting transitions, the selection of which transitions will fire is based in part on an implicit priority. These priorities resolve some transition conflicts, but not all of them. The priorities of conflicting transitions are based on their relative position in the state hierarchy. By definition, a transition originating from a substate has higher priority than a conflicting transition originating from any of its containing states. The priority of a transition is defined based on its source state. The priority of joined transitions is based on the priority of the transition with the most transitively nested source state. In general, if t1 is a transition whose source state is s1, and t2 has source s2, then:
• If s1 is a direct or transitively nested substate of s2, then t1 has higher priority than t2.
• If s1 and s2 are not in the same state configuration, then there is no priority difference between t1 and t2.
Transition selection algorithm The set of transitions that will fire is a maximal set of transitions that satisfies the following conditions: • All transitions in the set are enabled.
• There are no conflicting transitions within the set.
• There is no transition outside the set that has higher priority than a transition in the set (that is, enabled transitions with highest priorities are in the set while conflicting transitions with lower priorities are left out). This can be easily implemented by a greedy selection algorithm, with a straightforward traversal of the active state configuration. States in the active state configuration are traversed starting with the innermost nested simple states and working outwards. For each state at a given level, all originating transitions are evaluated to determine if they are enabled. This traversal guarantees that the priority principle is not violated. The only non-trivial issue is resolving transition conflicts across orthogonal states on all levels. This is resolved by terminating the search in each orthogonal state once a transition inside any one of its components is fired.
StateMachine extension A state machine is generalizable. A specialized state machine is an extension of the general state machine, in that regions, vertices, and transitions may be added; regions and states may be redefined (extended: simple states to composite states and composite states by adding states and transitions); and transitions can be redefined. As part of a classifier generalization, the classifierBehavior state machine of the general classifier and the method state machines of behavioral features of the general classifier can be redefined (by other state machines). These state machines may be specializations (extensions) of the corresponding state machines of the general classifier or of its behavioral features. A specialized state machine will have all the elements of the general state machine, and it may have additional elements. Regions may be added. Inherited regions may be redefined by extension: States and vertices are inherited, and states and transitions of the regions of the state machine may be redefined. A simple state can be redefined (extended) to a composite state, by adding one or more regions. A composite state can be redefined (extended) by either extending inherited regions or by adding regions as well as by adding entry and exit points. A region is extended by adding vertices, states, and transitions and by redefining states and transitions.
A submachine state may be redefined. The submachine state machine may be replaced by another submachine state machine, provided that it has the same entry/exit points as the redefined submachine state machine, but it may add entry/ exit points. Transitions can have their content and target state replaced, while the source state and trigger are preserved. In case of multiple general classifiers, extension implies that the extension state machine gets orthogonal regions for each of the state machines of the general classifiers in addition to the one of the specific classifier.
Description
An interaction is a unit of behavior that focuses on the observable exchange of information between ConnectableElements. An Interaction is a specialization of InteractionFragment and of Behavior.
Semantics
Interactions are units of behavior of an enclosing Classifier. Interactions focus on the passing of information with Messages between the ConnectableElements of the Classifier. The semantics of an Interaction is given as a pair of sets of traces. The two trace sets represent valid traces and invalid traces. The union of these two sets need not necessarily cover the whole universe of traces. The traces that are not included are not described by this Interaction at all, and we cannot know whether they are valid or invalid. A trace is a sequence of event occurrences, each of which is described by an OccurrenceSpecification in a model. The semantics of Interactions are compositional in the sense that the semantics of an Interaction is mechanically built from the semantics of its constituent InteractionFragments. The constituent InteractionFragments are ordered and combined by the seq operation (weak sequencing) as explained in “Weak Sequencing” on page 483. The invalid set of traces are associated only with the use of a Negative CombinedInteraction. For simplicity we describe only valid traces for all other constructs.
those of the original. The traces defined by the specialization is combined with those of the inherited Interaction with a union. The classifier owning an Interaction may be specialized, and in the specialization the Interaction may be redefined. Redefining an Interaction simply means to exchange the redefining Interaction for the redefined one, and this exchange takes effect also for InteractionUses within the supertype of the owner. This is similar to redefinition of other kinds of Behavior.
Basic trace model: The semantics of an Interaction is given by a pair [P, I] where P is the set of valid traces and I is the set of invalid traces. need not be the whole universe of traces. A trace is a sequence of event occurrences denoted <e1, e2, ... , en>. An event occurrence will also include information about the values of all relevant objects at this point in time. Each construct of Interactions (such as CombinedFragments of different kinds) are expressed in terms of how it relates to a pair of sets of traces. For simplicity we normally refer only to the set of valid traces as these traces are those mostly modeled. Two Interactions are equivalent if their pair of trace-sets are equal.
Relation of trace model to execution model: In Chapter 13, “Common Behaviors” we find an Execution model, and this is how the Interactions Trace Model relates to the Execution model. An Interaction is an Emergent Behavior. An InvocationOccurrence in the Execution model corresponds with an (event) Occurrence in a trace. Occurrences are modeled in an Interaction by OccurrenceSpecifications. Normally in Interaction the action leading to the invocation as such is not described (such as the sending action). However, if it is desirable to go into details, a Behavior (such as an Activity) may be associated with an OccurrenceSpecification. An occurrence in Interactions is normally interpreted to take zero time. Duration is always between occurrences. Likewise a ReceiveOccurrence in the Execution model is modeled by an OccurrenceSpecification. Similarly the detailed actions following immediately from this reception are often omitted in Interactions, but may also be described explicitly with a Behavior associated with that OccurrenceSpecification. A Request in the Execution model is modeled by the Message in Interactions. An Execution in the Execution model is modeled by an ExecutionSpecification in Interactions. An Execution is defined in the trace by two Occurrences, one at the start and one at the end. This corresponds to the StartOccurrence and the CompletionOccurrence of the Execution model.
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
An extension end is used to tie an extension to a stereotype when extending a metaclass.
Description ExtensionEnd is a kind of Property that is always typed by a Stereotype. An ExtensionEnd is a navigable ownedEnd, owned by an Extension. This allows a stereotype instance to be attached to an instance of the extended classifier without adding a property to the classifier. The aggregation of an ExtensionEnd is always composite. The default multiplicity of an ExtensionEnd is 0..1.
Semantics No additional semantics
A Model is a description of a system, where ‘system’ is meant in the broadest sense and may include not only software and hardware but organizations and processes. It describes the system from a certain viewpoint (or vantage point) for a certain category of stakeholders (e.g., designers, users, or customers of the system) and at a certain level of abstraction. A Model is complete in the sense that it covers the whole system, although only those aspects relevant to its purpose (i.e., within the given level of abstraction and viewpoint) are represented in the Model.
As a Package, a Model has a set of members that together describe the system being modeled. The organization of these elements varies by the modeling method being used. One approach is one or more composition hierarchies where a top-most Package/Component represents the boundary of the system. A Model may also contain elements describing relevant parts of the system’s environment. The environment is typically modeled by Actors and their Interfaces. As these are external to the system, they reside outside the Package/Component hierarchy. They may be collected in a separate Package, or owned directly by the Model as packagedElements.
Different Models can be defined for the same system, where typically the different Models are complementary and defined from the perspectives (viewpoints) of different system stakeholders. With composition of Models, a container model represents a comprehensive view of the system given by the different views defined by the contained Models.
Models can have Abstraction Dependencies between them: refinement (stereotyped by «refine» from the Standard Profile) or mapping ( for example stereotyped by «trace» from the Standard Profile). These are typically represented in more detail by Dependencies between the elements contained in the Models. Relationships between elements in different Models generally no direct impact on the contents of the Models because each Model is meant to be complete. However, they are useful for tracing refinements and for keeping track of cross-references between models.
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::A of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Class
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::roleNameB of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Property
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::attName of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Property
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::B of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Class
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::roleNameA of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Property
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Primitive_Links.Association_Example::Association Example of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Package
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Views.Modeling_Stack::UML Model (M1)
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
Properties are StructuralFeatures that represent the attributes of Classifiers, the memberEnds of Associations, and the parts of StructuredClassifiers.
Description Property represents a declared state of one or more instances in terms of a named relationship to a value or values. When a property is an attribute of a classifier, the value or values are related to the instance of the classifier by being held in slots of the instance. When a property is an association end, the value or values are related to the instance or instances at the other end(s) of the association (see semantics of Association). Property is indirectly a subclass of Constructs::TypedElement. The range of valid values represented by the property can be controlled by setting the property’s type.
Semantics When a property is owned by a classifier other than an association via ownedAttribute, then it represents an attribute of the class or data type. When related to an association via memberEnd or one of its specializations, it represents an end of the association. In either case, when instantiated a property represents a value or collection of values associated with an instance of one (or in the case of a ternary or higher-order association, more than one) type. This set of classifiers is called the context for the property; in the case of an attribute the context is the owning classifier, and in the case of an association end the context is the set of types at the other end or ends of the association. The value or collection of values instantiated for a property in an instance of its context conforms to the property’s type. Property inherits from MultiplicityElement and thus allows multiplicity bounds to be specified. These bounds constrain the size of the collection. Typically and by default the maximum bound is 1. Property also inherits the isUnique and isOrdered meta-attributes. When isUnique is true (the default) the collection of values may not contain duplicates. When isOrdered is true (false being the default) the collection of values is ordered. In combination these two allow the type of a property to represent a collection in the following way:
If there is a default specified for a property, this default is evaluated when an instance of the property is created in the absence of a specific setting for the property or a constraint in the model that requires the property to have a specific value. The evaluated default then becomes the initial value (or values) of the property. If a property is derived, then its value or values can be computed from other information. Actions involving a derived property behave the same as for a nonderived property. Derived properties are often specified to be read-only (i.e., clients cannot directly change values). But where a derived property is changeable, an implementation is expected to make appropriate changes to the model in order for all the constraints to be met, in particular the derivation constraint for the derived property. The derivation for a derived property may be specified by a constraint. The name and visibility of a property are not required to match those of any property it redefines. A derived property can redefine one which is not derived. An implementation must ensure that the constraints implied by the derivation are maintained if the property is updated. If a property has a specified default, and the property redefines another property with a specified default, then the redefining property’s default is used in place of the more general default from the redefined property. If a navigable property is marked as readOnly, then it cannot be updated once it has been assigned an initial value.
A property may be marked as the subset of another, as long as every element in the context of subsetting property conforms to the corresponding element in the context of the subsetted property. In this case, the collection associated with an instance of the subsetting property must be included in (or the same as) the collection associated with the corresponding instance of the subsetted property. A property may be marked as being a derived union. This means that the collection of values denoted by the property in some context is derived by being the strict union of all of the values denoted, in the same context, by properties defined to subset it. If the property has a multiplicity upper bound of 1, then this means that the values of all the subsets must be null or the same. A property may be owned by and in the namespace of a datatype A property may be marked as being (part of) the identifier (if any) for classes of which it is a member. The interpretation of this is left open but this could be mapped to implementations such as primary keys for relational database tables or ID attributes in XML. If multiple properties are marked (possibly in superclasses), then it is the combination of the (property, value) tuples that will logically provide the uniqueness for any instance. Hence there is no need for any specification of order and it is possible for some (but not all) of the property values to be empty. If the property is multivalued, then all values are included.
An Association specifies a semantic relationship that can occur between typed instances. It has at least two memberEnds represented by Properties, each of which has the type of the end. More than one end of the Association may have the same type.
An Association declares that there can be links between instances of the associated types. A link is a tuple with one value for each memberEnd of the Association, where each value is an instance of the type of the end.
Not all links need to be classified by an Association.
When one or more ends of the Association have isUnique=false, it is possible to have several links associating the same set of instances. In such a case, links carry an additional identifier apart from their end values.
When one or more ends of the Association are ordered, links carry ordering information in addition to their end values.
For an Association with N memberEnds, choose any N-1 ends and associate specific instances with those ends. Then the collection of links of the Association that refer to these specific instances will identify a collection of instances at the other end. The multiplicity of the other end constrains the size of this collection. If the other end is marked as isOrdered, this collection will be ordered. If the other end is marked as isUnique, this collection is a set; otherwise, it allows duplicate elements.
Subsetting represents the familiar set-theoretic concept. It applies to the collections represented by Association ends, not to the Association itself. It means that the subsetting Association end represents a collection that is either equal to or a proper subset of the collection that it is subsetting. Subsetting is a relationship in the domain of extensional semantics.
Specialization is, in contrast to subsetting, a relationship in the domain of intentional semantics, which is to say it characterizes the criteria whereby membership in the collection is defined, not by the membership. In the case of Associations, specialization means that a link classified by the specializing association is also classified by the specialized association. Semantically this implies that the collections representing the ends of the specializing association are subsets of the corresponding collections representing the ends of the specialized association; this fact of subsetting may or may not be explicitly declared in a model.
Note – For n-ary Associations, the lower multiplicity of an end is typically 0. A lower multiplicity for an end of an n-ary Association of 1 (or more) implies that one link (or more) must exist for every possible combination of values for the other ends.
A binary Association may represent a composite aggregation (i.e., a whole/part relationship). Composition is represented by the isComposite attribute on the part end of the Association being set to true. See the semantics of composition in 9.5.3.
An end Property of an Association that is owned by an end Class or that is a navigableOwnedEnd of the Association indicates that the Association is navigable from the opposite ends; otherwise, the Association is not navigable from the opposite ends. Navigability means that instances participating in links at runtime (instances of an Association) can be accessed efficiently from instances at the other ends of the Association. The precise mechanism by which such efficient access is achieved is implementation specific. If an end is not navigable, access from the other ends may or may not be possible, and if it is, it might not be efficient. Note that tools operating on UML models are not prevented from navigating Associations from non-navigable ends.
The existence of an association may be derived from other information in the model. The logical relationship between the derivation of an Association and the derivation of its ends is model-specific.
Operation (from Kernel, Interfaces) Description An operation is a behavioral feature of a classifier that specifies the name, type, parameters, and constraints for invoking an associated behavior.
Semantics An operation is invoked on an instance of the classifier for which the operation is a feature.
The preconditions for an operation define conditions that must be true when the operation is invoked. These preconditions may be assumed by an implementation of this operation. The postconditions for an operation define conditions that will be true when the invocation of the operation completes successfully, assuming the preconditions were satisfied. These postconditions must be satisfied by any implementation of the operation. The bodyCondition for an operation constrains the return result. The bodyCondition differs from postconditions in that the bodyCondition may be overridden when an operation is redefined, whereas postconditions can only be added during redefinition. An operation may raise an exception during its invocation. When an exception is raised, it should not be assumed that the postconditions or bodyCondition of the operation are satisfied. An operation may be redefined in a specialization of the featured classifier. This redefinition may specialize the types of the owned parameters, add new preconditions or postconditions, add new raised exceptions, or otherwise refine the specification of the operation. Each operation states whether or not its application will modify the state of the instance or any other element in the model (isQuery). An operation may be owned by and in the namespace of a class that provides the context for its possible redefinition. Semantic Variation Points The behavior of an invocation of an operation when a precondition is not satisfied is a semantic variation point. When operations are redefined in a specialization, rules regarding invariance, covariance, or contravariance of types and preconditions determine whether the specialized classifier is substitutable for its more general parent. Such rules constitute semantic variation points with respect to redefinition of operations.
Operation (from Communications) Description An operation may invoke both the execution of method behaviors as well as other behavioral responses. Semantics If an operation is not mentioned in a trigger of a behavior owned or inherited by the behaviored classifier owning the operation, then upon occurrence of a call event (representing the receipt of a request for the invocation of this operation) a resolution process is performed that determines the method behavior to be invoked, based on the operation and the data values corresponding to the parameters of the operation transmitted by the request; otherwise, the call event is placed into the input pool of the object (see BehavioredClassifier on page 449). If a behavior is triggered by this event, it begins with performing the resolution process and invoking the so determined method. Then the behavior continues its execution as specified. Operations specify immediate or triggered effects (see “BehavioredClassifier” )
Semantic Variation Points Resolution specifies how a particular behavior is identified to be executed in response to the invocation of an operation, using mechanisms such as inheritance. The mechanism by which the behavior to be invoked is determined from an operation and the transmitted argument data is a semantic variation point. In general, this mechanism may be complicated to include languages with features such as before-after methods, delegation, etc. In some of these variations, multiple behaviors may be executed as a result of a single call. The following defines a simple object-oriented process for this semantic variation point. • Object-oriented resolution When a call request is received, the class of the target object is examined for an owned operation with matching parameters (see “BehavioralFeature” on page 448). If such operation is found, the behavior associated as method is the result of the resolution; otherwise, the parent classifier is examined for a matching operation, and so on up the generalization hierarchy until a method is found or the root of the hierarchy is reached. If a class has multiple parents, all of them are examined for a method. If a method is found in exactly one ancestor class, then that method is the result of the resolution. If a method is found in more than one ancestor class along different paths, then the model is ill-formed under this semantic variation. If no method by the resolution process, then it is a semantic variation point what is to happen.
Description A type constrains the values represented by a typed element.
Semantics A type serves as a constraint on the range of values represented by a typed element. Type is an abstract metaclass.
Description A parameter is a specification of an argument used to pass information into or out of an invocation of a behavioral feature. It has a type, and may have a multiplicity and an optional default value.
Semantics A parameter specifies how arguments are passed into or out of an invocation of a behavioral feature like an operation. The type and multiplicity of a parameter restrict what values can be passed, how many, and whether the values are ordered. If a default is specified for a parameter, then it is evaluated at invocation time and used as the argument for this parameter if and only if no argument is supplied at invocation of the behavioral feature. A parameter may be given a name, which then identifies the parameter uniquely within the parameters of the same behavioral feature. If it is unnamed, it is distinguished only by its position in the ordered list of parameters. The parameter direction specifies whether its value is passed into, out of, or both into and out of the owning behavioral feature. A single parameter may be distinguished as a return parameter. If the behavioral feature is an operation, then the type and multiplicity of this parameter is the same as the type and multiplicity of the operation itself.
The connector concept is extended in the Components package to include contracts and notation. A delegation connector is a connector that links the external contract of a component (as specified by its ports) to the realization of that behavior. It represents the forwarding of events (operation requests and events): a signal that arrives at a port that has a delegation connector to one or more parts or ports on parts will be passed on to those targets for handling. An assembly connector is a connector between two or more parts or ports on parts that defines that one or more parts provide the services that other parts use.
Description In the metamodel, a derived connector kind attribute is added to the Connector metaclass. Its value is an enumeration type with valid values “assembly” or “delegation.”
Semantics A delegation connector is a declaration that behavior that is available on a component instance is not actually realized by that component itself, but by one or more instances that have “compatible” capabilities. These situations are modeled through a delegation connector from a Port to compatible Ports or Parts. Delegation connectors can be used to model the hierarchical decomposition of behavior, where services provided by a component may ultimately be realized by one that is nested multiple levels deep within it. The word delegation suggests that concrete message and signal flow will occur between the connected ports, possibly over multiple levels. It should be noted that such signal flow is not always realized in all system environments or implementations (i.e., it may be design time only). A port may delegate to a set of ports on subordinate components. In that case, these subordinate ports must collectively offer the delegated functionality of the delegating port. At execution time, signals will be delivered to the appropriate port. In cases where multiple target ports support the handling of the same signal, the signal will be delivered to all these subordinate ports.
The execution time semantics for an assembly connector are that signals travel along an instance of a connector. Multiple connectors directed to and from different parts, or n-ary connectors where n> 2, indicates that the instance that will originate or handle the signal will be determined at execution time. The interface compatibility between ports that are connected enables an existing component in a system to be replaced by one that (minimally) offers the same set of services. Also, in contexts where components are used to extend a system by offering existing services, but also adding new functionality, connectors can be used to link in the new component definition.
Description A typed element is an element that has a type that serves as a constraint on the range of values the element can represent. Typed element is an abstract metaclass.
Semantics Values represented by the element are constrained to be instances of the type. A typed element with no associated type may represent values of any type.
Class (from Kernel)
A class describes a set of objects that share the same specifications of features, constraints, and semantics.
Description Class is a kind of classifier whose features are attributes and operations. Attributes of a class are represented by instances of Property that are owned by the class. Some of these attributes may represent the navigable ends of binary associations.
Semantics The purpose of a class is to specify a classification of objects and to specify the features that characterize the structure and behavior of those objects. Objects of a class must contain values for each attribute that is a member of that class, in accordance with the characteristics of the attribute, for example its type and multiplicity. When an object is instantiated in a class, for every attribute of the class that has a specified default, if an initial value of the attribute is not specified explicitly for the instantiation, then the default value specification is evaluated to set the initial value of the attribute for the object. Operations of a class can be invoked on an object, given a particular set of substitutions for the parameters of the operation. An operation invocation may cause changes to the values of the attributes of that object. It may also return a value as a result, where a result type for the operation has been defined. Operation invocations may also cause changes in value to the attributes of other objects that can be navigated to, directly or indirectly, from the object on which the operation is invoked, to its output parameters, to objects navigable from its parameters, or to other objects in the scope of the operation’s execution. Operation invocations may also cause the creation and deletion of objects. A class cannot access private features of another class, or protected features on another class that is not its supertype. When creating and deleting associations, at least one end must allow access to the class.
Class (from StructuredClasses, InternalStructures) Description Extends the metaclass Class with the capability to have an internal structure and ports.
Semantics See “Property (from InternalStructures)” , “Connector (from InternalStructures)” , and “Port (from Ports)” on page 186 for the semantics of the features of Class. Initialization of the internal structure of a class is discussed in sub clause “StructuredClassifier (from InternalStructures)” . A class acts as the namespace for various kinds of classifiers defined within its scope, including classes. Nesting of classifiers limits the visibility of the classifier to within the scope of the namespace of the containing class and is used for reasons of information hiding. Nested classifiers are used like any other classifier in the containing class.
Class (from Communications) Description A class may be designated as active (i.e., each of its instances having its own thread of control) or passive (i.e., each of its instances executing within the context of some other object). A class may also specify which signals the instances of this class handle.
Semantics An active object is an object that, as a direct consequence of its creation, commences to execute its classifier behavior, and does not cease until either the complete behavior is executed or the object is terminated by some external object. (This is sometimes referred to as “the object having its own thread of control.”) The points at which an active object responds to communications from other objects is determined solely by the behavior of the active object and not by the invoking object. If the classifier behavior of an active object completes, the object is terminated.
Class (from Profiles) Description Class has derived association that indicates how it may be extended through one or more stereotypes. Stereotype is the only kind of metaclass that cannot be extended by stereotypes.
Semantics No additional semantics
Description An activity specifies the coordination of executions of subordinate behaviors, using a control and data flow model. The subordinate behaviors coordinated by these models may be initiated because other behaviors in the model finish executing, because objects and data become available, or because events occur external to the flow. The flow of execution is modeled as activity nodes connected by activity edges. A node can be the execution of a subordinate behavior, such as an arithmetic computation, a call to an operation, or manipulation of object contents. Activity nodes also include flow-of-control constructs, such as synchronization, decision, and concurrency control. Activities may form invocation hierarchies invoking other activities, ultimately resolving to individual actions. In an object-oriented model, activities are usually invoked indirectly as methods bound to operations that are directly invoked. Activities may describe procedural computation. In this context, they are the methods corresponding to operations on classes. Activities may be applied to organizational modeling for business process engineering and workflow. In this context, events often originate from inside the system, such as the finishing of a task, but also from outside the system, such as a customer call. Activities can also be used for information system modeling to specify system level processes. Activities may contain actions of various kinds:
• Occurrences of primitive functions, such as arithmetic functions.
• Invocations of behavior, such as activities.
• Communication actions, such as sending of signals.
• Manipulations of objects, such as reading or writing attributes or associations.
Actions have no further decomposition in the activity containing them. However, the execution of a single action may induce the execution of many other actions. For example, a call action invokes an operation that is implemented by an activity containing actions that execute before the call action completes. Most of the constructs in the Activity clause deal with various mechanisms for sequencing the flow of control and data among the actions:
• Object flows for sequencing data produced by one node that is used by other nodes.
• Control flows for sequencing the execution of nodes.
• Control nodes to structure control and object flow. These include decisions and merges to model contingency. These also include initial and final nodes for starting and ending flows. In IntermediateActivities, they include forks and joins for creating and synchronizing concurrent subexecutions.
• Activity generalization to replace nodes and edges.
• Object nodes to represent objects and data as they flow in and out of invoked behaviors, or to represent collections of tokens waiting to move downstream.
Package StructuredActivities
• Composite nodes to represent structured flow-of-control constructs, such as loops and conditionals.
Package IntermediateActivities
• Partitions to organize lower-level activities according to various criteria, such as the real-world organization responsible for their performance.
Package CompleteActivities
• Interruptible regions and exceptions to represent deviations from the normal, mainline flow of control.
Description ActivityEdge is an abstract class for the connections along which tokens flow between activity nodes. It covers control and data flow edges. Activity edges can control token flow.
Package CompleteActivities Complete activity edges can be contained in interruptible regions.
Semantics Activity edges are directed connections, that is, they have a source and a target, along which tokens may flow. Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. The guard must evaluate to true for every token that is offered to pass along the edge. Tokens in the intermediate level of activities can only pass along the edge individually at different times. See application of guards at DecisionNode.
Package CompleteActivities
Any number of tokens can pass along the edge, in groups at one time, or individually at different times. The weight attribute dictates the minimum number of tokens that must traverse the edge at the same time. It is a value specification evaluated every time a new token becomes available at the source. It must evaluate to a positive LiteralUnlimitedNatural, and may be a constant. When the minimum number of tokens are offered, all the tokens at the source are offered to the target all at once. The minimum number of tokens must be accepted by the target for any tokens to traverse the edge. The guard must evaluate to true for each token. If the guard fails for any of the tokens, and this reduces the number of tokens that can be offered to the target to less than the weight, then all the tokens fail to be offered. An unlimited weight means that all the tokens at the source must be accepted by the target for any of them to traverse the edge. This can be combined with a join to take all of the tokens at the source when certain conditions hold (see examples in Figure 12.45). A weaker but simpler alternative to weight is grouping information into larger objects so that a single token carries all necessary data (see additional functionality for guards at DecisionNode). Other rules for when tokens may be passed along the edge depend on the kind of edge and characteristics of its source and target. See the children of ActivityEdge and ActivityNode. The rules may be optimized to a different algorithm as long as the effect is the same. For example, if the target is an object node that has reached its upper bound, no token can be passed. The implementation can omit unnecessary weight evaluations until the downstream object node can accept tokens. Edges can be named, by inheritance from RedefinableElement, which is a NamedElement. However, edges are not required to have unique names within an activity. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of edges is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Edges inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements.
Semantic Variation Points See variations at children of ActivityEdge and ActivityNode.
An activity node is an abstract class for the steps of an activity. It covers executable nodes, control nodes, and object nodes.
(BasicActivities) Nodes can be replaced in generalization and (CompleteActivities) be contained in interruptible regions.
Constraints [1] Activity nodes can only be owned by activities or groups. Package StructuredActivities [1] Activity nodes may be owned by at most one structured node.
Semantics Nodes can be named, however, nodes are not required to have unique names within an activity to support multiple invocations of the same behavior or multiple uses of the same action. See Action, which is a kind of node. The fact that Activity is a Namespace, inherited through Behavior, does not affect this, because the containment of nodes is through ownedElement, the general ownership metaassociation for Element that does not imply unique names, rather than ownedMember. Other than naming, and functionality added by the complete version of activities, an activity node is only a point in an activity at this level of abstraction. See the children of ActivityNode for additional semantics. Package BasicActivities Nodes inherited from more general activities can be replaced. See RedefinableElement for more information on overriding inherited elements, and Activity for more information on activity generalization. See children of ActivityNode for additional semantics.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
A decision node is a control node that chooses between outgoing flows.
Description A decision node accepts tokens on an incoming edge and presents them to multiple outgoing edges. Which of the edges is actually traversed depends on the evaluation of the guards on the outgoing edges.
Semantics Each token arriving at a decision node can traverse only one outgoing edge. Tokens are not duplicated. Each token offered by the incoming edge is offered to the outgoing edges. Most commonly, guards of the outgoing edges are evaluated to determine which edge should be traversed. The order in which guards are evaluated is not defined, because edges in general are not required to determine which tokens they accept in any particular order. The modeler should arrange that each token only be chosen to traverse one outgoing edge; otherwise, there will be race conditions among the outgoing edges. If the implementation can ensure that only one guard will succeed, it is not required to evaluate all guards when one is found that does. For decision points, a predefined guard “else” may be defined for at most one outgoing edge. This guard succeeds for a token only if the token is not accepted by all the other edges outgoing from the decision point. Notice that the semantics only requires that the token traverse one edge, rather than be offered to only one edge. Multiple edges may be offered the token, but if only one of them has a target that accepts the token, then that edge is traversed. If multiple edges accept the token and have approval from their targets for traversal at the same time, then the semantics is not defined. If a decision input behavior is specified, then each data token is passed to the behavior before guards are evaluated on the outgoing edges. The behavior is invoked without input for control tokens. The output of the behavior is available to the guard. Because the behavior is used during the process of offering tokens to outgoing edges, it may be run many times on the same token before the token is accepted by those edges. This means the behavior cannot have side effects. It may not modify objects, but it may for example, navigate from one object to another or get an attribute value from an object. If there is a decision input flow, but no decision input behavior, then it is the tokens offered on the decision input flow that are made available to the guard on each outgoing edge to determine whether the offer on the regular incoming edge is passed along that outgoing edge. If there is a decision input behavior and a decision input flow, the token offered on the decision input flow is passed to the behavior (as the only argument if the regular incoming edge is control flow, as the second argument if it is an object flow). Decision nodes with the additional decision input flow offer tokens to outgoing edges only when one token is offered on each incoming edge.
Description A control node is an activity node used to coordinate the flows between other nodes. It covers initial node, final node and its children, fork node, join node, decision node, and merge node.
Semantics See semantics at Activity. See subclasses for the semantics of each kind of control node.
A final node is an abstract control node at which a flow in an activity stops.
Description See descriptions at children of final node.
Semantics All tokens offered on incoming edges are accepted. See children of final node for other semantics.
Description A fork node has one incoming edge and multiple outgoing edges.
Semantics Tokens that arrive at a fork node are duplicated across the outgoing edges of the node. Specifically, tokens offered to a fork node are offered to all outgoing edges of the node. If at least one of these offers is accepted, the offered tokens are removed from their source and a copy of the tokens traverse each edge for which the offer was accepted.
Any offer that was not accepted on an outgoing edge due to the failure of the target to accept it remains pending on that edge and may be accepted by the target at a later time. These edges effectively accept a separate copy of the offered tokens, and offers made to the edges stand to their targets in the order in which they were accepted by the edge (first in, first out). This is an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream (see “Activity (from BasicActivities, CompleteActivities, FundamentalActivities, StructuredActivities)” on page 324). Note that any outgoing edges that fail to accept an offer due to the failure of a guard do not receive copies of those tokens. If guards are used on edges outgoing from forks, the modelers should ensure that no downstream joins depend on the arrival of tokens passing through the guarded edge. If that cannot be avoided, then a decision node should be introduced to have the guard, and shunt the token to the downstream join if the guard fails. See example in Figure 12.44 on page 338.
Description An activity may have more than one initial node.
Semantics An initial node is a starting point for executing an activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). A control token is placed at the initial node when the activity starts, but not in initial nodes in structured nodes contained by the activity. Tokens in an initial node are offered to all outgoing edges. If an activity has more than one initial node, then invoking the activity starts multiple flows, one at each initial node. For convenience, initial nodes are an exception to the rule that control nodes cannot hold tokens if they are blocked from moving downstream, for example, by guards (see Activity). This is equivalent to interposing a CentralBufferNode between the initial node and its outgoing edges. Note that flows can also start at other nodes, see ActivityParameterNode and AcceptEventAction, so initial nodes are not required for an activity to start execution. In addition, when an activity starts, a control token is placed at each action or structured node that has no incoming edges, except if it is a handler body (see “ExceptionHandler (from ExtraStructuredActivities)” on page 373, it is the fromAction of an action input pin (see “ActionInputPin (as specialized)” on page 323), or it is contained in a structured node.
Description A join node has multiple incoming edges and one outgoing edge.
Package CompleteActivities Join nodes have a Boolean value specification using the names of the incoming edges to specify the conditions under which the join will emit a token.
Semantics If there is a token offered on all incoming edges, then tokens are offered on the outgoing edge according to the following join rules:
1. If all the tokens offered on the incoming edges are control tokens, then one control token is offered on the outgoing edge.
2. If some of the tokens offered on the incoming edges are control tokens and others are data tokens, then only the data tokens are offered on the outgoing edge. Tokens are offered on the outgoing edge in the same order they were offered to the join.
Multiple control tokens offered on the same incoming edge are combined into one before applying the above rules. No joining of tokens is necessary if there is only one incoming edge, but it is not a useful case.
Package CompleteActivities The reserved string “and” used as a join specification is equivalent to a specification that requires at least one token offered on each incoming edge. It is the default. The join specification is evaluated whenever a new token is offered on any incoming edge. The evaluation is not interrupted by any new tokens offered during the evaluation, nor are concurrent evaluations started when new tokens are offered during an evaluation. If any tokens are offered to the outgoing edge, they must be accepted or rejected for traversal before any more tokens are offered to the outgoing edge. If tokens are rejected for traversal, they are no longer offered to the outgoing edge. The join specification may contain the names of the incoming edges to refer to whether a token was offered on that edge at the time the evaluation started. If isCombinedDuplicate is true, then before object tokens are offered to the outgoing edge, those containing objects with the same identity are combined into one token.
A merge node is a control node that brings together multiple alternate flows. It is not used to synchronize concurrent flows but to accept one among several alternate flows.
Description A merge node has multiple incoming edges and a single outgoing edge.
Semantics All tokens offered on incoming edges are offered to the outgoing edge. There is no synchronization of flows or joining of tokens.
A flow final node is a final node that terminates a flow.
Description A flow final destroys all tokens that arrive at it. It has no effect on other flows in the activity.
Semantics Flow final destroys tokens flowing into it.
An activity final node is a final node that stops all flows in an activity.
Description An activity may have more than one activity final node. The first one reached stops all flows in the activity.
Semantics A token reaching an activity final node terminates the activity (or structured node, see “StructuredActivityNode (from CompleteStructuredActivities, StructuredActivities)” on page 423). In particular, it stops all executing actions in the activity, and destroys all tokens in object nodes, except in the output activity parameter nodes. Terminating the execution of synchronous invocation actions also terminates whatever behaviors they are waiting on for return. Any behaviors invoked asynchronously by the activity are not affected. All tokens offered on the incoming edges are accepted. The content of output activity parameter nodes are passed out of the containing activity, using the null token for object nodes that have nothing in them. If there is more than one final node in an activity, the first one reached terminates the activity, including the flow going towards the other activity final.
If it is not desired to abort all flows in the activity, use flow final instead. For example, if the same execution of an activity is being used for all its invocations, then multiple streams of tokens will be flowing through the same activity. In this case, it is probably not desired to abort all tokens just because one reaches an activity final. Using a flow final will simply consume the tokens reaching it without aborting other flows. Or arrange for separate invocations of the activity to use separate executions of the activity, so tokens from separate invocations will not affect each other.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description
AcceptEventAction is an action that waits for the occurrence of an event meeting specified condition.
Semantics
Accept event actions handle event occurrences detected by the object owning the behavior (also see “InterruptibleActivityRegion (from CompleteActivities)”).
Event occurrences are detected by objects independently of actions and the occurrences are stored by the object. The arrangement of detected event occurrences is not defined, but it is expected that extensions or profiles will specify such arrangements.
If the accept event action is executed and the object detected an event occurrence matching one of the triggers on the action and the occurrence has not been accepted by another action or otherwise consumed by another behavior, then the accept event action completes and outputs a value describing the occurrence.
If such a matching occurrence is not available, the action waits until such an occurrence becomes available, at which point the action may accept it.
In a system with concurrency, several actions or other behaviors might contend for an available event occurrence. Unless otherwise specified by an extension or profile, only one action accepts a given occurrence, even if the occurrence would satisfy multiple concurrently executing actions.
If the occurrence is a signal event occurrence and isUnmarshall is false, the result value contains a signal object whose reception by the owning object caused the occurrence.
If the occurrence is a signal event occurrence and isUnmarshall is true, the attribute values of the signal are placed on the result output pins of the action.
Signal objects may be copied in transmission and storage by the owning object, so identity might not be preserved.
An action whose trigger is a signal event is informally called an accept signal action. If the occurrence is a time event occurrence, the result value contains the time at which the occurrence transpired. Such an action is informally called a wait time action. If the occurrences are all occurrences of ChangeEvent, or all CallEvent, or a combination of these, there are no output pins (however, see “AcceptCallAction (from CompleteActions)” ).
See CommonBehavior for a description of Event specifications. If the triggers are a combination of SignalEvents and ChangeEvents, the result is a null value if a change event occurrence or a call event occurrence is accepted. If one of the triggers is an AnyReceiveEvent, and the event occurrence is for a message that is not matched by any specific SignalEvent or CallEvent trigger on the same action, then the event occurrence matches the AnyReceiveEvent (see also , “AnyReceiveEvent (from Communications)”).
This action handles asynchronous messages, including asynchronous calls. It cannot be used with synchronous calls (except see “AcceptCallAction (from CompleteActions)”).
Description An action with implementation-specific semantics
Semantics The semantics of the action are determined by the implementation.
Rationale OpaqueAction is introduced for implementation-specific actions or for use as a temporary placeholder before some other action is chosen.
Description SendSignalAction is an action that creates a signal instance from its inputs, and transmits it to the target object, where it may cause the firing of a state machine transition or the execution of an activity. The argument values are available to the execution of associated behaviors. The requestor continues execution immediately. Any reply message is ignored and is not transmitted to the requestor. If the input is already a signal instance, use SendObjectAction.
Semantics
[1] When all the prerequisites of the action execution are satisfied, a signal instance of the type specified by signal is generated from the argument values and this signal instance is transmitted to the identified target object. The target object may be local or remote. The signal instance may be copied during transmission, so identity might not be preserved. The manner of transmitting the signal object, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
[2] When a transmission arrives at a target object, it may invoke behavior in the target object. The effect of receiving a signal object is specified in 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
[3] A send signal action receives no reply from the invoked behavior; any attempted reply is simply ignored, and no transmission is performed to the requestor.
Rationale Sends a signal to a specified target object.
Description CallAction is an abstract class for actions that invoke behavior and receive return values.
Semantics Parameters on behaviors and operations are totally ordered lists. To match parameters to pins on call actions, select the sublist of that list that corresponds to in and inout owned parameters (i.e., Behavior.ownedParameter). The input pins on Action::input are matched in order against these parameters in the sublist order. Then take the sublist of the parameter list that corresponds to out, inout, and return parameters. The output pins on Action::output are matched in order against these parameters in sublist order. If the behavior invoked by a call action is not reentrant, then no more than one execution of it will exist at any given time. An invocation of a non-reentrant behavior does not start the behavior when the behavior is already executing.
An invocation of a reentrant behavior may start a new execution of the behavior when offered the required tokens, even if the behavior is already executing. However, it will not invoke the behavior if there is an ongoing behavior execution invocated by the same action within the same activity execution, and the action has isLocallyReentrant=false (see “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319). See children of CallAction.
Description
BroadcastSignalAction is an action that transmits a signal instance to all the potential target objects in the system, which may cause the firing of a state machine transitions or the execution of associated activities of a target object. The argument values are available to the execution of associated behaviors. The requestor continues execution immediately after the signals are sent out. It does not wait for receipt. Any reply messages are ignored and are not transmitted to the requestor.
Semantics
When all the prerequisites of the action execution are satisfied, a signal object is generated from the argument values according to signal and this signal object is transmitted concurrently to each of the implicit broadcast target objects in the system. The manner of identifying the set of objects that are broadcast targets is a semantic variation point and may be limited to some subset of all the objects that exist. There is no restriction on the location of target objects. The manner of transmitting the signal object, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
When a transmission arrives at a target object, it may invoke a behavior in the target object. The effect of receiving such transmission is specified in Clause 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
A broadcast signal action receives no reply from the invoked behavior; any attempted reply is simply ignored, and no transmission is performed to the requestor.
Semantic Variation Points
The determination of the set of broadcast target objects is a semantic variation point.
Description
CallBehaviorAction is a call action that invokes a behavior directly rather than invoking a behavioral feature that, in turn, results in the invocation of that behavior. The argument values of the action are available to the execution of the invoked behavior. For synchronous calls the execution of the call behavior action waits until the execution of the invoked behavior completes and a result is returned on its output pin. The action completes immediately without a result, if the call is asynchronous.
Semantics
[1] When all the prerequisites of the action execution are satisfied, CallBehaviorAction invokes its specified behavior with the values on the input pins as arguments. When the behavior is finished, the output values are put on the output pins. Each parameter of the behavior of the action provides output to a pin or takes input from one. No other implementation specifics are implied, such as call stacks, and so on.
[2] If the call is asynchronous, the action completes immediately. Execution of the invoked behavior proceeds without any further dependency on the execution of the behavior containing the invoking action. Once the invocation of the behavior has been initiated, execution of the asynchronous action is complete.
[3] An asynchronous invocation completes when its behavior is started, or is at least ensured to be started at some point. Any return or out values from the invoked behavior are not passed back to the containing behavior. When an asynchronous invocation is done, the containing behavior continues regardless of the status of the invoked behavior. For example, the containing behavior may complete even though the invoked behavior is not finished.
[4] If the call is synchronous, execution of the calling action is blocked until it receives a reply from the invoked behavior. The reply includes values for any return, out, or inout parameters.
[5] If the call is synchronous, when the execution of the invoked behavior completes, the result values are placed on the result pins of the call behavior action, and the execution of the action is complete (StructuredActions, ExtraStructuredActivities). If the execution of the invoked behavior yields an exception, the exception is transmitted to the call behavior action to begin search for a handler. See RaiseExceptionAction.
Description
CallOperationAction is an action that transmits an operation call request to the target object, where it may cause the invocation of associated behavior. The argument values of the action are available to the execution of the invoked behavior. If the action is marked synchronous, the execution of the call operation action waits until the execution of the invoked behavior completes and a reply transmission is returned to the caller; otherwise, execution of the action is complete when the invocation of the operation is established and the execution of the invoked operation proceeds concurrently with the execution of the calling behavior. Any values returned as part of the reply transmission are put on the result output pins of the call operation action. Upon receipt of the reply transmission, execution of the call operation action is complete.
Semantics
The inputs to the action determine the target object and additional actual arguments of the call.
[1] When all the prerequisites of the action execution are satisfied, information comprising the operation and the argument pin values of the action execution is created and transmitted to the target object. The target objects may be local or remote. The manner of transmitting the call, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
[2] When a call arrives at a target object, it may invoke a behavior in the target object. The effect of receiving such call is specified in 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
[3] If the call is synchronous, when the execution of the invoked behavior completes, its return results are transmitted back as a reply to the calling action execution. The manner of transmitting the reply, the time required for transmission, the representation of the reply transmission, and the transmission path are unspecified. If the execution of the invoked behavior yields an exception, the exception is transmitted to the caller where it is reraised as an exception in the execution of the calling action. Possible exception types may be specified by attaching them to the called Operation using the raisedException association.
[4] If the call is asynchronous, the caller proceeds immediately and the execution of the call operation action is complete. Any return or out values from the invoked operation are not passed back to the containing behavior. If the call is synchronous, the caller is blocked from further execution until it receives a reply from the invoked behavior.
[5] When the reply transmission arrives at the invoking action execution, the return result values are placed on the result pins of the call operation action, and the execution of the action is complete.
Semantic Variation Points The mechanism for determining the method to be invoked as a result of a call operation is unspecified.
A port is a property of a classifier that specifies a distinct interaction point between that classifier and its environment or between the (behavior of the) classifier and its internal parts. Ports are connected to properties of the classifier by connectors through which requests can be made to invoke the behavioral features of a classifier. A Port may specify the services a classifier provides (offers) to its environment as well as the services that a classifier expects (requires) of its environment.
Description
Ports represent interaction points between a classifier and its environment. The interfaces associated with a port specify the nature of the interactions that may occur over a port. The required interfaces of a port characterize the requests that may be made from the classifier to its environment through this port. The provided interfaces of a port characterize requests to the classifier that its environment may make through this port. A port has the ability to specify that any requests arriving at this port are handled by the behavior of the instance of the owning classifier, rather than being forwarded to any contained instances, if any.
Semantics
A port represents an interaction point between a classifier instance and its environment or between a classifier instance and instances it may contain. A port by default has public visibility.
The required interfaces characterize services that the owning classifier expects from its environment and that it may access through this interaction point: Instances of this classifier expect that the features owned by its required interfaces will be offered by one or more instances in its environment.
The provided interfaces characterize the behavioral features that the owning classifier offers to its environment at this interaction point. The owning classifier must offer the features owned by the provided interfaces. The provided and required interfaces completely characterize any interaction that may occur between a classifier and its environment at a port with respect to the data communicated at this port and the behaviors that may be invoked through this port. The interfaces do not necessarily establish the exact sequences of interactions across the port. When an instance of a classifier is created, instances corresponding to each of its ports are created and held in the slots specified by the ports, in accordance with its multiplicity. These instances are referred to as “interaction points” and provide unique references. A link from that instance to the instance of the owning classifier is created through which communication is forwarded to the instance of the owning classifier or through which the owning classifier communicates with its environment. It is, therefore, possible for an instance to differentiate between requests for the invocation of a behavioral feature targeted at its different ports. Similarly, it is possible to direct such requests at a port, and the requests will be routed as specified by the links corresponding to connectors attached to this port. (In the following, “requests arriving at a port” shall mean “request occurrences arriving at the interaction point of this instance corresponding to this port.”)
If connectors are attached to both the port when used on a property within the internal structure of a classifier and the port on the container of an internal structure, the instance of the owning classifier will forward any requests arriving at this port along the link specified by those connectors. If there is a connector attached to only one side of a port, any requests arriving at this port will terminate at this port. For a behavior port, the instance of the owning classifier will handle requests arriving at this port, if this classifier has any behavior. If there is no behavior defined for this classifier, any communication arriving at a behavior port is lost.
Semantic Variation Points If several connectors are attached on one side of a port, then any request arriving at this port on a link derived from a connector on the other side of the port will be forwarded on links corresponding to these connectors. It is a semantic variation point whether these requests will be forwarded on all links, or on only one of those links. In the latter case, one possibility is that the link at which this request will be forwarded will be arbitrarily selected among those links leading to an instance that had been specified as being able to handle this request (i.e., this request is specified in a provided interface of the part corresponding to this instance).
An action is a named element that is the fundamental unit of executable functionality. The execution of an action represents some transformation or processing in the modeled system, be it a computer system or otherwise.
An action execution represents the run-time behavior of executing an action within a specific behavior execution. As Action is an abstract class, all action executions will be executions of specific kinds of actions. When the action executes, and what its actual inputs are, is determined by the concrete action and the behaviors in which it is used.
Description
BroadcastSignalAction is an action that transmits a signal instance to all the potential target objects in the system, which may cause the firing of a state machine transitions or the execution of associated activities of a target object. The argument values are available to the execution of associated behaviors. The requestor continues execution immediately after the signals are sent out. It does not wait for receipt. Any reply messages are ignored and are not transmitted to the requestor.
Semantics
When all the prerequisites of the action execution are satisfied, a signal object is generated from the argument values according to signal and this signal object is transmitted concurrently to each of the implicit broadcast target objects in the system. The manner of identifying the set of objects that are broadcast targets is a semantic variation point and may be limited to some subset of all the objects that exist. There is no restriction on the location of target objects. The manner of transmitting the signal object, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
When a transmission arrives at a target object, it may invoke a behavior in the target object. The effect of receiving such transmission is specified in Clause 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
A broadcast signal action receives no reply from the invoked behavior; any attempted reply is simply ignored, and no transmission is performed to the requestor.
Semantic Variation Points
The determination of the set of broadcast target objects is a semantic variation point.
Description CallAction is an abstract class for actions that invoke behavior and receive return values.
Semantics Parameters on behaviors and operations are totally ordered lists. To match parameters to pins on call actions, select the sublist of that list that corresponds to in and inout owned parameters (i.e., Behavior.ownedParameter). The input pins on Action::input are matched in order against these parameters in the sublist order. Then take the sublist of the parameter list that corresponds to out, inout, and return parameters. The output pins on Action::output are matched in order against these parameters in sublist order. If the behavior invoked by a call action is not reentrant, then no more than one execution of it will exist at any given time. An invocation of a non-reentrant behavior does not start the behavior when the behavior is already executing.
An invocation of a reentrant behavior may start a new execution of the behavior when offered the required tokens, even if the behavior is already executing. However, it will not invoke the behavior if there is an ongoing behavior execution invocated by the same action within the same activity execution, and the action has isLocallyReentrant=false (see “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319). See children of CallAction.
Description SendSignalAction is an action that creates a signal instance from its inputs, and transmits it to the target object, where it may cause the firing of a state machine transition or the execution of an activity. The argument values are available to the execution of associated behaviors. The requestor continues execution immediately. Any reply message is ignored and is not transmitted to the requestor. If the input is already a signal instance, use SendObjectAction.
Semantics
[1] When all the prerequisites of the action execution are satisfied, a signal instance of the type specified by signal is generated from the argument values and this signal instance is transmitted to the identified target object. The target object may be local or remote. The signal instance may be copied during transmission, so identity might not be preserved. The manner of transmitting the signal object, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
[2] When a transmission arrives at a target object, it may invoke behavior in the target object. The effect of receiving a signal object is specified in 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
[3] A send signal action receives no reply from the invoked behavior; any attempted reply is simply ignored, and no transmission is performed to the requestor.
Rationale Sends a signal to a specified target object.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Description
CallBehaviorAction is a call action that invokes a behavior directly rather than invoking a behavioral feature that, in turn, results in the invocation of that behavior. The argument values of the action are available to the execution of the invoked behavior. For synchronous calls the execution of the call behavior action waits until the execution of the invoked behavior completes and a result is returned on its output pin. The action completes immediately without a result, if the call is asynchronous.
Semantics
[1] When all the prerequisites of the action execution are satisfied, CallBehaviorAction invokes its specified behavior with the values on the input pins as arguments. When the behavior is finished, the output values are put on the output pins. Each parameter of the behavior of the action provides output to a pin or takes input from one. No other implementation specifics are implied, such as call stacks, and so on.
[2] If the call is asynchronous, the action completes immediately. Execution of the invoked behavior proceeds without any further dependency on the execution of the behavior containing the invoking action. Once the invocation of the behavior has been initiated, execution of the asynchronous action is complete.
[3] An asynchronous invocation completes when its behavior is started, or is at least ensured to be started at some point. Any return or out values from the invoked behavior are not passed back to the containing behavior. When an asynchronous invocation is done, the containing behavior continues regardless of the status of the invoked behavior. For example, the containing behavior may complete even though the invoked behavior is not finished.
[4] If the call is synchronous, execution of the calling action is blocked until it receives a reply from the invoked behavior. The reply includes values for any return, out, or inout parameters.
[5] If the call is synchronous, when the execution of the invoked behavior completes, the result values are placed on the result pins of the call behavior action, and the execution of the action is complete (StructuredActions, ExtraStructuredActivities). If the execution of the invoked behavior yields an exception, the exception is transmitted to the call behavior action to begin search for a handler. See RaiseExceptionAction.
Description CallAction is an abstract class for actions that invoke behavior and receive return values.
Semantics Parameters on behaviors and operations are totally ordered lists. To match parameters to pins on call actions, select the sublist of that list that corresponds to in and inout owned parameters (i.e., Behavior.ownedParameter). The input pins on Action::input are matched in order against these parameters in the sublist order. Then take the sublist of the parameter list that corresponds to out, inout, and return parameters. The output pins on Action::output are matched in order against these parameters in sublist order. If the behavior invoked by a call action is not reentrant, then no more than one execution of it will exist at any given time. An invocation of a non-reentrant behavior does not start the behavior when the behavior is already executing.
An invocation of a reentrant behavior may start a new execution of the behavior when offered the required tokens, even if the behavior is already executing. However, it will not invoke the behavior if there is an ongoing behavior execution invocated by the same action within the same activity execution, and the action has isLocallyReentrant=false (see “Action (from CompleteActivities, FundamentalActivities, StructuredActivities, CompleteStructuredActivities)” on page 319). See children of CallAction.
Description
CallOperationAction is an action that transmits an operation call request to the target object, where it may cause the invocation of associated behavior. The argument values of the action are available to the execution of the invoked behavior. If the action is marked synchronous, the execution of the call operation action waits until the execution of the invoked behavior completes and a reply transmission is returned to the caller; otherwise, execution of the action is complete when the invocation of the operation is established and the execution of the invoked operation proceeds concurrently with the execution of the calling behavior. Any values returned as part of the reply transmission are put on the result output pins of the call operation action. Upon receipt of the reply transmission, execution of the call operation action is complete.
Semantics
The inputs to the action determine the target object and additional actual arguments of the call.
[1] When all the prerequisites of the action execution are satisfied, information comprising the operation and the argument pin values of the action execution is created and transmitted to the target object. The target objects may be local or remote. The manner of transmitting the call, the amount of time required to transmit it, the order in which the transmissions reach the various target objects, and the path for reaching the target objects are undefined.
[2] When a call arrives at a target object, it may invoke a behavior in the target object. The effect of receiving such call is specified in 13, “Common Behaviors.” Such effects include executing activities and firing state machine transitions.
[3] If the call is synchronous, when the execution of the invoked behavior completes, its return results are transmitted back as a reply to the calling action execution. The manner of transmitting the reply, the time required for transmission, the representation of the reply transmission, and the transmission path are unspecified. If the execution of the invoked behavior yields an exception, the exception is transmitted to the caller where it is reraised as an exception in the execution of the calling action. Possible exception types may be specified by attaching them to the called Operation using the raisedException association.
[4] If the call is asynchronous, the caller proceeds immediately and the execution of the call operation action is complete. Any return or out values from the invoked operation are not passed back to the containing behavior. If the call is synchronous, the caller is blocked from further execution until it receives a reply from the invoked behavior.
[5] When the reply transmission arrives at the invoking action execution, the return result values are placed on the result pins of the call operation action, and the execution of the action is complete.
Semantic Variation Points The mechanism for determining the method to be invoked as a result of a call operation is unspecified.
Description An output pin is a pin that holds output values produced by an action.
Semantics
For each execution, an action cannot terminate itself unless it can put at least as many values on its output pins as required by the lower multiplicity on those pins. The values are actually put in the pins once the action completes. Values that may remain on the output pins from previous executions are not included in meeting this minimum multiplicity requirement. An action may not put more values in an output pin in a single execution than the upper multiplicity of the pin.
Description
An input pin is a pin that holds input values to be consumed by an action.
Semantics
An action cannot start execution if an input pin has fewer values than the lower multiplicity. The upper multiplicity determines the maximum number of values that can be consumed by a single execution of the action.
Operation (from Kernel, Interfaces) Description An operation is a behavioral feature of a classifier that specifies the name, type, parameters, and constraints for invoking an associated behavior.
Semantics An operation is invoked on an instance of the classifier for which the operation is a feature.
The preconditions for an operation define conditions that must be true when the operation is invoked. These preconditions may be assumed by an implementation of this operation. The postconditions for an operation define conditions that will be true when the invocation of the operation completes successfully, assuming the preconditions were satisfied. These postconditions must be satisfied by any implementation of the operation. The bodyCondition for an operation constrains the return result. The bodyCondition differs from postconditions in that the bodyCondition may be overridden when an operation is redefined, whereas postconditions can only be added during redefinition. An operation may raise an exception during its invocation. When an exception is raised, it should not be assumed that the postconditions or bodyCondition of the operation are satisfied. An operation may be redefined in a specialization of the featured classifier. This redefinition may specialize the types of the owned parameters, add new preconditions or postconditions, add new raised exceptions, or otherwise refine the specification of the operation. Each operation states whether or not its application will modify the state of the instance or any other element in the model (isQuery). An operation may be owned by and in the namespace of a class that provides the context for its possible redefinition. Semantic Variation Points The behavior of an invocation of an operation when a precondition is not satisfied is a semantic variation point. When operations are redefined in a specialization, rules regarding invariance, covariance, or contravariance of types and preconditions determine whether the specialized classifier is substitutable for its more general parent. Such rules constitute semantic variation points with respect to redefinition of operations.
Operation (from Communications) Description An operation may invoke both the execution of method behaviors as well as other behavioral responses. Semantics If an operation is not mentioned in a trigger of a behavior owned or inherited by the behaviored classifier owning the operation, then upon occurrence of a call event (representing the receipt of a request for the invocation of this operation) a resolution process is performed that determines the method behavior to be invoked, based on the operation and the data values corresponding to the parameters of the operation transmitted by the request; otherwise, the call event is placed into the input pool of the object (see BehavioredClassifier on page 449). If a behavior is triggered by this event, it begins with performing the resolution process and invoking the so determined method. Then the behavior continues its execution as specified. Operations specify immediate or triggered effects (see “BehavioredClassifier” )
Semantic Variation Points Resolution specifies how a particular behavior is identified to be executed in response to the invocation of an operation, using mechanisms such as inheritance. The mechanism by which the behavior to be invoked is determined from an operation and the transmitted argument data is a semantic variation point. In general, this mechanism may be complicated to include languages with features such as before-after methods, delegation, etc. In some of these variations, multiple behaviors may be executed as a result of a single call. The following defines a simple object-oriented process for this semantic variation point. • Object-oriented resolution When a call request is received, the class of the target object is examined for an owned operation with matching parameters (see “BehavioralFeature” on page 448). If such operation is found, the behavior associated as method is the result of the resolution; otherwise, the parent classifier is examined for a matching operation, and so on up the generalization hierarchy until a method is found or the root of the hierarchy is reached. If a class has multiple parents, all of them are examined for a method. If a method is found in exactly one ancestor class, then that method is the result of the resolution. If a method is found in more than one ancestor class along different paths, then the model is ill-formed under this semantic variation. If no method by the resolution process, then it is a semantic variation point what is to happen.
Description An interface is a kind of classifier that represents a declaration of a set of coherent public features and obligations. An interface specifies a contract; any instance of a classifier that realizes the interface must fulfill that contract. The obligations that may be associated with an interface are in the form of various kinds of constraints (such as pre- and post-conditions) or protocol specifications, which may impose ordering restrictions on interactions through the interface. Since interfaces are declarations, they are not instantiable. Instead, an interface specification is implemented by an instance of an instantiable classifier, which means that the instantiable classifier presents a public facade that conforms to the interface specification. Note that a given classifier may implement more than one interface and that an interface may be implemented by a number of different classifiers (see “InterfaceRealization (from Interfaces)”
Semantics An interface declares a set of public features and obligations that constitute a coherent service offered by a classifier. Interfaces provide a way to partition and characterize groups of properties that realizing classifier instances must possess. An interface does not specify how it is to be implemented, but merely what needs to be supported by realizing instances. That is, such instances must provide a public facade (attributes, operations, externally observable behavior) that conforms to the interface. Thus, if an interface declares an attribute, this does not necessarily mean that the realizing instance will necessarily have such an attribute in its implementation, only that it will appear so to external observers. Because an interface is merely a declaration it is not an instantiable model element; that is, there are no instances of interfaces at run time.
The set of interfaces realized by a classifier are its provided interfaces, which represent the obligations that instances of that classifier have to their clients. They describe the services that the instances of that classifier offer to their clients. Interfaces may also be used to specify required interfaces, which are specified by a usage dependency between the classifier and the corresponding interfaces. Required interfaces specify services that a classifier needs in order to perform its function and fulfill its own obligations to its clients. Properties owned by interfaces are abstract and imply that the conforming instance should maintain information corresponding to the type and multiplicity of the property and facilitate retrieval and modification of that information. A property declared on an Interface does not necessarily imply that there will be such a property on a classifier realizing that Interface (e.g., it may be realized by equivalent get and set operations). Interfaces may also own constraints that impose constraints on the features of the implementing classifier. An association between an interface and any other classifier implies that a conforming association must exist between any implementation of that interface and that other classifier. In particular, an association between interfaces implies that a conforming association must exist between implementations of the interfaces. An interface cannot be directly instantiated. Instantiable classifiers, such as classes, must implement an interface (see “InterfaceRealization (from Interfaces)”).
A component represents a modular part of a system that encapsulates its contents and whose manifestation is replaceable within its environment. A component defines its behavior in terms of provided and required interfaces. As such, a component serves as a type whose conformance is defined by these provided and required interfaces (encompassing both their static as well as dynamic semantics). One component may therefore be substituted by another only if the two are type conformant. Larger pieces of a system’s functionality may be assembled by reusing components as parts in an encompassing component or assembly of components, and wiring them together. A component is modeled throughout the development life cycle and successively refined into deployment and run-time. A component may be manifest by one or more artifacts, and in turn, that artifact may be deployed to its execution environment. A deployment specification may define values that parameterize the component’s execution. (See Deployment clause).
Description BasicComponents A component is a subtype of Class that provides for a Component having attributes and operations, and being able to participate in Associations and Generalizations. A Component may form the abstraction for a set of realizingClassifiers that realize its behavior. In addition, because a Class itself is a subtype of an EncapsulatedClassifier, a Component may optionally have an internal structure and own a set of Ports that formalize its interaction points. A component has a number of provided and required Interfaces. A provided Interface is one that is either realized directly by the component or one of its realizingClassifiers, or it is provided by a public Port of the Component. A required interface is designated by a Usage Dependency from the Component or one of its realizingClassifiers, or it is required by a public Port.
PackagingComponents A component is extended to define the grouping aspects of packaging components. This defines the Namespace aspects of a Component through its inherited ownedMember and elementImport associations. In the namespace of a component, all model elements that are involved in or related to its definition are either owned or imported explicitly. This may include, for example, UseCases and Dependencies (e.g., mappings), Packages, Components, and Artifacts.
Semantics A component is a self contained unit that encapsulates the state and behavior of a number of classifiers. A component specifies a formal contract of the services that it provides to its clients and those that it requires from other components or services in the system in terms of its provided and required interfaces.
A component is a substitutable unit that can be replaced at design time or run-time by a component that offers equivalent functionality based on compatibility of its interfaces. As long as the environment obeys the constraints expressed by the provided and required interfaces of a component, it will be able to interact with this environment. Similarly, a system can be extended by adding new component types that add new functionality. The required and provided interfaces of a component allow for the specification of structural features such as attributes and association ends, as well as behavioral features such as operations and events. A component may implement a provided interface directly, or, its realizing classifiers may do so, or they may be inherited. The required and provided interfaces may optionally be organized through ports, these enable the definition of named sets of provided and required interfaces that are typically (but not always) addressed at run-time. A component has an external view (or “black-box” view) by means of its publicly visible properties and operations. Optionally, a behavior such as a protocol state machine may be attached to an interface, port, and to the component itself, to define the external view more precisely by making dynamic constraints in the sequence of operation calls explicit. Other behaviors may also be associated with interfaces or connectors to define the ‘contract’ between participants in a collaboration (e.g., in terms of use case, activity, or interaction specifications). The wiring between components in a system or other context can be structurally defined by using dependencies between compatible simple Ports, or between Usages and matching InterfaceRealizations that are represented by sockets and lollipops on Components on component diagrams. Creating a wiring Dependency between a Usage and a matching InterfaceRealization, or between compatible simple Ports, means that there may be some additional information, such as performance requirements, transport bindings, or other policies that determine that the interface is realized in a way that is suitable for consumption by the depending Component. Such additional information could be captured in a profile by means of stereotypes. A component also has an internal view (or “white-box” view) by means of its private properties and realizing classifiers. This view shows how the external behavior is realized internally. Dependencies on the external view provide a convenient overview of what may happen in the internal view; they do not prescribe what must happen. More detailed behavior specifications such as interactions and activities may be used to detail the mapping from external to internal behavior. A number of UML standard stereotypes exist that apply to component. For example, «subsystem» to model large-scale components, and «specification» and «realization» to model components with distinct specification and realization definitions, where one specification may have multiple realizations (see the UML Standard Elements Annex).
A port is a property of a classifier that specifies a distinct interaction point between that classifier and its environment or between the (behavior of the) classifier and its internal parts. Ports are connected to properties of the classifier by connectors through which requests can be made to invoke the behavioral features of a classifier. A Port may specify the services a classifier provides (offers) to its environment as well as the services that a classifier expects (requires) of its environment.
Description
Ports represent interaction points between a classifier and its environment. The interfaces associated with a port specify the nature of the interactions that may occur over a port. The required interfaces of a port characterize the requests that may be made from the classifier to its environment through this port. The provided interfaces of a port characterize requests to the classifier that its environment may make through this port. A port has the ability to specify that any requests arriving at this port are handled by the behavior of the instance of the owning classifier, rather than being forwarded to any contained instances, if any.
Semantics
A port represents an interaction point between a classifier instance and its environment or between a classifier instance and instances it may contain. A port by default has public visibility.
The required interfaces characterize services that the owning classifier expects from its environment and that it may access through this interaction point: Instances of this classifier expect that the features owned by its required interfaces will be offered by one or more instances in its environment.
The provided interfaces characterize the behavioral features that the owning classifier offers to its environment at this interaction point. The owning classifier must offer the features owned by the provided interfaces. The provided and required interfaces completely characterize any interaction that may occur between a classifier and its environment at a port with respect to the data communicated at this port and the behaviors that may be invoked through this port. The interfaces do not necessarily establish the exact sequences of interactions across the port. When an instance of a classifier is created, instances corresponding to each of its ports are created and held in the slots specified by the ports, in accordance with its multiplicity. These instances are referred to as “interaction points” and provide unique references. A link from that instance to the instance of the owning classifier is created through which communication is forwarded to the instance of the owning classifier or through which the owning classifier communicates with its environment. It is, therefore, possible for an instance to differentiate between requests for the invocation of a behavioral feature targeted at its different ports. Similarly, it is possible to direct such requests at a port, and the requests will be routed as specified by the links corresponding to connectors attached to this port. (In the following, “requests arriving at a port” shall mean “request occurrences arriving at the interaction point of this instance corresponding to this port.”)
If connectors are attached to both the port when used on a property within the internal structure of a classifier and the port on the container of an internal structure, the instance of the owning classifier will forward any requests arriving at this port along the link specified by those connectors. If there is a connector attached to only one side of a port, any requests arriving at this port will terminate at this port. For a behavior port, the instance of the owning classifier will handle requests arriving at this port, if this classifier has any behavior. If there is no behavior defined for this classifier, any communication arriving at a behavior port is lost.
Semantic Variation Points If several connectors are attached on one side of a port, then any request arriving at this port on a link derived from a connector on the other side of the port will be forwarded on links corresponding to these connectors. It is a semantic variation point whether these requests will be forwarded on all links, or on only one of those links. In the latter case, one possibility is that the link at which this request will be forwarded will be arbitrarily selected among those links leading to an instance that had been specified as being able to handle this request (i.e., this request is specified in a provided interface of the part corresponding to this instance).
Properties are StructuralFeatures that represent the attributes of Classifiers, the memberEnds of Associations, and the parts of StructuredClassifiers.
Description Property represents a declared state of one or more instances in terms of a named relationship to a value or values. When a property is an attribute of a classifier, the value or values are related to the instance of the classifier by being held in slots of the instance. When a property is an association end, the value or values are related to the instance or instances at the other end(s) of the association (see semantics of Association). Property is indirectly a subclass of Constructs::TypedElement. The range of valid values represented by the property can be controlled by setting the property’s type.
Semantics When a property is owned by a classifier other than an association via ownedAttribute, then it represents an attribute of the class or data type. When related to an association via memberEnd or one of its specializations, it represents an end of the association. In either case, when instantiated a property represents a value or collection of values associated with an instance of one (or in the case of a ternary or higher-order association, more than one) type. This set of classifiers is called the context for the property; in the case of an attribute the context is the owning classifier, and in the case of an association end the context is the set of types at the other end or ends of the association. The value or collection of values instantiated for a property in an instance of its context conforms to the property’s type. Property inherits from MultiplicityElement and thus allows multiplicity bounds to be specified. These bounds constrain the size of the collection. Typically and by default the maximum bound is 1. Property also inherits the isUnique and isOrdered meta-attributes. When isUnique is true (the default) the collection of values may not contain duplicates. When isOrdered is true (false being the default) the collection of values is ordered. In combination these two allow the type of a property to represent a collection in the following way:
If there is a default specified for a property, this default is evaluated when an instance of the property is created in the absence of a specific setting for the property or a constraint in the model that requires the property to have a specific value. The evaluated default then becomes the initial value (or values) of the property. If a property is derived, then its value or values can be computed from other information. Actions involving a derived property behave the same as for a nonderived property. Derived properties are often specified to be read-only (i.e., clients cannot directly change values). But where a derived property is changeable, an implementation is expected to make appropriate changes to the model in order for all the constraints to be met, in particular the derivation constraint for the derived property. The derivation for a derived property may be specified by a constraint. The name and visibility of a property are not required to match those of any property it redefines. A derived property can redefine one which is not derived. An implementation must ensure that the constraints implied by the derivation are maintained if the property is updated. If a property has a specified default, and the property redefines another property with a specified default, then the redefining property’s default is used in place of the more general default from the redefined property. If a navigable property is marked as readOnly, then it cannot be updated once it has been assigned an initial value.
A property may be marked as the subset of another, as long as every element in the context of subsetting property conforms to the corresponding element in the context of the subsetted property. In this case, the collection associated with an instance of the subsetting property must be included in (or the same as) the collection associated with the corresponding instance of the subsetted property. A property may be marked as being a derived union. This means that the collection of values denoted by the property in some context is derived by being the strict union of all of the values denoted, in the same context, by properties defined to subset it. If the property has a multiplicity upper bound of 1, then this means that the values of all the subsets must be null or the same. A property may be owned by and in the namespace of a datatype A property may be marked as being (part of) the identifier (if any) for classes of which it is a member. The interpretation of this is left open but this could be mapped to implementations such as primary keys for relational database tables or ID attributes in XML. If multiple properties are marked (possibly in superclasses), then it is the combination of the (property, value) tuples that will logically provide the uniqueness for any instance. Hence there is no need for any specification of order and it is possible for some (but not all) of the property values to be empty. If the property is multivalued, then all values are included.
Description
A reception is a declaration stating that a classifier is prepared to react to the receipt of a signal. A reception designates a signal and specifies the expected behavioral response. The details of handling a signal are specified by the behavior associated with the reception or the classifier itself.
The receipt of a signal instance by the instance of the classifier owning a matching reception will cause the asynchronous invocation of the behavior specified as the method of the reception. A reception matches a signal if the received signal is a subtype of the signal referenced by the reception. The details of how the behavior responds to the received signal depend on the kind of behavior associated with the reception. (For example, if the reception is implemented by a state machine, the signal event will trigger a transition and subsequent effects as specified by that state machine.)
Receptions specify triggered effects (see “BehavioredClassifier” on page 448).
Description A protocol state machine is always defined in the context of a classifier. It specifies which operations of the classifier can be called in which state and under which condition, thus specifying the allowed call sequences on the classifier’s operations. A protocol state machine presents the possible and permitted transitions on the instances of its context classifier, together with the operations that carry the transitions. In this manner, an instance lifecycle can be created for a classifier, by specifying the order in which the operations can be activated and the states through which an instance progresses during its existence.
Semantics Protocol state machines help define the usage mode of the operations and receptions of a classifier by specifying: • In which context (under which states and pre conditions) they can be used. • If there is a protocol order between them. • What result is expected from their use. The states of a protocol state machine (protocol states) present an external view of the class that is exposed to its clients. Depending on the context, protocol states can correspond to the internal states of the instances as expressed by behavioral state machines, or they can be different. A protocol state machine expresses parts of the constraints that can be formulated for pre- and post-conditions on operations. The translation from protocol state machine to pre- and post-conditions on operations might not be straightforward, because the conditions would need to account for the operation call history on the instance, which may or may not be directly represented by its internal states. A protocol state machine provides a direct model of the state of interaction with the instance, so that constraints on interaction are more easily expressed. The protocol state machine defines all allowed transitions for each operation. The protocol state machine must represent all operations that can generate a given change of state for a class. Those operations that do not generate a transition are not represented in the protocol state machine. Protocol state machines constitute a means to formalize the interface of classes, and do not express anything except consistency rules for the implementation or dynamics of classes. Protocol state machine interpretation can vary from: 1. Declarative protocol state machines that specify the legal transitions for each operation. The exact triggering condition for the operations is not specified. This specification only defines the contract for the user of the context classifier. 2. Executable protocol state machines, that specify all events that an object may receive and handle, together with the transitions that are implied. In this case, the legal transitions for operations will exactly be the triggered transitions. The call trigger specifies the effect action, which is the call of the associated operation. The representation for both interpretations is the same, the only difference being the direct dynamic implication that the interpretation 2 provides. Elaborated forms of state machine modeling such as compound transitions, sub-state machines, composite states, and concurrent regions can also be used for protocol state machines. For example, concurrent regions make it possible to express protocol where an instance can have several active states simultaneously. Sub state machines and compound transitions are used as in behavioral state machines for factorizing complex protocol state machines.
A classifier may have several protocol state machines. This happens frequently, for example, when a class inherits several parent classes having protocol state machine, when the protocols are orthogonal. An alternative to multiple protocol state machines can always be found by having one protocol state machine, with sub state machines in concurrent regions.
Operation (from Kernel, Interfaces) Description An operation is a behavioral feature of a classifier that specifies the name, type, parameters, and constraints for invoking an associated behavior.
Semantics An operation is invoked on an instance of the classifier for which the operation is a feature.
The preconditions for an operation define conditions that must be true when the operation is invoked. These preconditions may be assumed by an implementation of this operation. The postconditions for an operation define conditions that will be true when the invocation of the operation completes successfully, assuming the preconditions were satisfied. These postconditions must be satisfied by any implementation of the operation. The bodyCondition for an operation constrains the return result. The bodyCondition differs from postconditions in that the bodyCondition may be overridden when an operation is redefined, whereas postconditions can only be added during redefinition. An operation may raise an exception during its invocation. When an exception is raised, it should not be assumed that the postconditions or bodyCondition of the operation are satisfied. An operation may be redefined in a specialization of the featured classifier. This redefinition may specialize the types of the owned parameters, add new preconditions or postconditions, add new raised exceptions, or otherwise refine the specification of the operation. Each operation states whether or not its application will modify the state of the instance or any other element in the model (isQuery). An operation may be owned by and in the namespace of a class that provides the context for its possible redefinition. Semantic Variation Points The behavior of an invocation of an operation when a precondition is not satisfied is a semantic variation point. When operations are redefined in a specialization, rules regarding invariance, covariance, or contravariance of types and preconditions determine whether the specialized classifier is substitutable for its more general parent. Such rules constitute semantic variation points with respect to redefinition of operations.
Operation (from Communications) Description An operation may invoke both the execution of method behaviors as well as other behavioral responses. Semantics If an operation is not mentioned in a trigger of a behavior owned or inherited by the behaviored classifier owning the operation, then upon occurrence of a call event (representing the receipt of a request for the invocation of this operation) a resolution process is performed that determines the method behavior to be invoked, based on the operation and the data values corresponding to the parameters of the operation transmitted by the request; otherwise, the call event is placed into the input pool of the object (see BehavioredClassifier on page 449). If a behavior is triggered by this event, it begins with performing the resolution process and invoking the so determined method. Then the behavior continues its execution as specified. Operations specify immediate or triggered effects (see “BehavioredClassifier” )
Semantic Variation Points Resolution specifies how a particular behavior is identified to be executed in response to the invocation of an operation, using mechanisms such as inheritance. The mechanism by which the behavior to be invoked is determined from an operation and the transmitted argument data is a semantic variation point. In general, this mechanism may be complicated to include languages with features such as before-after methods, delegation, etc. In some of these variations, multiple behaviors may be executed as a result of a single call. The following defines a simple object-oriented process for this semantic variation point. • Object-oriented resolution When a call request is received, the class of the target object is examined for an owned operation with matching parameters (see “BehavioralFeature” on page 448). If such operation is found, the behavior associated as method is the result of the resolution; otherwise, the parent classifier is examined for a matching operation, and so on up the generalization hierarchy until a method is found or the root of the hierarchy is reached. If a class has multiple parents, all of them are examined for a method. If a method is found in exactly one ancestor class, then that method is the result of the resolution. If a method is found in more than one ancestor class along different paths, then the model is ill-formed under this semantic variation. If no method by the resolution process, then it is a semantic variation point what is to happen.
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Views.Interaction_Example::foo of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Message
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Views.Interaction_Example::A of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Lifeline
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Views.Interaction_Example::B of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::Lifeline
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Views.Interaction_Example::send_foo of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::MessageOccurrenceSpecification
UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.Views.Interaction_Example::receive_foo of type UML_2_4_1_Metamodel.UML_Metamodel_Web_Page.UML_2_4_1_Metamodel_Classes::MessageOccurrenceSpecification
Description
An interaction is a unit of behavior that focuses on the observable exchange of information between ConnectableElements. An Interaction is a specialization of InteractionFragment and of Behavior.
Semantics
Interactions are units of behavior of an enclosing Classifier. Interactions focus on the passing of information with Messages between the ConnectableElements of the Classifier. The semantics of an Interaction is given as a pair of sets of traces. The two trace sets represent valid traces and invalid traces. The union of these two sets need not necessarily cover the whole universe of traces. The traces that are not included are not described by this Interaction at all, and we cannot know whether they are valid or invalid. A trace is a sequence of event occurrences, each of which is described by an OccurrenceSpecification in a model. The semantics of Interactions are compositional in the sense that the semantics of an Interaction is mechanically built from the semantics of its constituent InteractionFragments. The constituent InteractionFragments are ordered and combined by the seq operation (weak sequencing) as explained in “Weak Sequencing” on page 483. The invalid set of traces are associated only with the use of a Negative CombinedInteraction. For simplicity we describe only valid traces for all other constructs.
those of the original. The traces defined by the specialization is combined with those of the inherited Interaction with a union. The classifier owning an Interaction may be specialized, and in the specialization the Interaction may be redefined. Redefining an Interaction simply means to exchange the redefining Interaction for the redefined one, and this exchange takes effect also for InteractionUses within the supertype of the owner. This is similar to redefinition of other kinds of Behavior.
Basic trace model: The semantics of an Interaction is given by a pair [P, I] where P is the set of valid traces and I is the set of invalid traces. need not be the whole universe of traces. A trace is a sequence of event occurrences denoted <e1, e2, ... , en>. An event occurrence will also include information about the values of all relevant objects at this point in time. Each construct of Interactions (such as CombinedFragments of different kinds) are expressed in terms of how it relates to a pair of sets of traces. For simplicity we normally refer only to the set of valid traces as these traces are those mostly modeled. Two Interactions are equivalent if their pair of trace-sets are equal.
Relation of trace model to execution model: In Chapter 13, “Common Behaviors” we find an Execution model, and this is how the Interactions Trace Model relates to the Execution model. An Interaction is an Emergent Behavior. An InvocationOccurrence in the Execution model corresponds with an (event) Occurrence in a trace. Occurrences are modeled in an Interaction by OccurrenceSpecifications. Normally in Interaction the action leading to the invocation as such is not described (such as the sending action). However, if it is desirable to go into details, a Behavior (such as an Activity) may be associated with an OccurrenceSpecification. An occurrence in Interactions is normally interpreted to take zero time. Duration is always between occurrences. Likewise a ReceiveOccurrence in the Execution model is modeled by an OccurrenceSpecification. Similarly the detailed actions following immediately from this reception are often omitted in Interactions, but may also be described explicitly with a Behavior associated with that OccurrenceSpecification. A Request in the Execution model is modeled by the Message in Interactions. An Execution in the Execution model is modeled by an ExecutionSpecification in Interactions. An Execution is defined in the trace by two Occurrences, one at the start and one at the end. This corresponds to the StartOccurrence and the CompletionOccurrence of the Execution model.
A lifeline represents an individual participant in the Interaction. While Parts and StructuralFeatures may have multiplicity greater than 1, Lifelines represent only one interacting entity. Lifeline is a specialization of NamedElement. If the referenced ConnectableElement is multivalued (i.e, has a multiplicity > 1), then the Lifeline may have an expression (the ‘selector’) that specifies which particular part is represented by this Lifeline. If the selector is omitted, this means that an arbitrary representative of the multivalued ConnectableElement is chosen.
Semantics
The order of OccurrenceSpecifications along a Lifeline is significant denoting the order in which these OccurrenceSpecifications will occur. The absolute distances between the OccurrenceSpecifications on the Lifeline are, however, irrelevant for the semantics. The semantics of the Lifeline (within an Interaction) is the semantics of the Interaction selecting only OccurrenceSpecifications of this Lifeline.
Specifies the occurrence of events, such as sending and receiving of signals or invoking or receiving of operation calls. A message occurrence specification is a kind of message end. Messages are generated either by synchronous operation calls or asynchronous signal sends. They are received by the execution of corresponding accept event actions.
A Message defines a particular communication between Lifelines of an Interaction.
A Message is a NamedElement that defines one specific kind of communication in an Interaction. A communication can be, for example, raising a signal, invoking an Operation, creating or destroying an Instance. The Message specifies not only the kind of communication given by the dispatching ExecutionSpecification, but also the sender and the receiver. A Message associates normally two OccurrenceSpecifications - one sending OccurrenceSpecification and one receiving OccurrenceSpecification.
Semantics
The semantics of a complete Message is simply the trace <sendEvent, receiveEvent>. A lost message is a message where the sending event occurrence is known, but there is no receiving event occurrence. We interpret this to be because the message never reached its destination. The semantics is simply the trace <sendEvent>. A found message is a message where the receiving event occurrence is known, but there is no (known) sending event occurrence. We interpret this to be because the origin of the message is outside the scope of the description. This may for example be noise or other activity that we do not want to describe in detail. The semantics is simply the trace <receiveEvent>. A Message reflects either an Operation call and start of execution or a sending and reception of a Signal.When a Message represents an Operation, the arguments of the Message are the arguments of the Operation. When a Message represents a Signal, the arguments of the Message are the attributes of the Signal.
A MessageEnd is an abstract NamedElement that represents what can occur at the end of a Message.
Semantics
Subclasses of MessageEnd define the specific semantics appropriate to the concept they represent.
An OccurrenceSpecification is the basic semantic unit of Interactions. The sequences of occurrences specified by them are the meanings of Interactions. OccurrenceSpecifications are ordered along a Lifeline. The namespace of an OccurrenceSpecification is the Interaction in which it is contained.

 UML 2.4.1 Metamodel
UML 2.4.1 Metamodel
 Start
Start